




Dylan
@dylancastillo.co
About: dylancastillo.co
Projects: dylancastillo.co/projects
Projects: dylancastillo.co/projects
Thank you, I'll update the article!
March 11, 2025 at 1:27 PM
Thank you, I'll update the article!
January 7, 2025 at 8:30 AM
In any case, for me, the key takeaway is that SO can decrease (or increase!) the performance in some tasks. Be conscious of that.
For now, there are no clear guidelines on where each method works better.
Your best bet is testing your LLM running your own evals.
For now, there are no clear guidelines on where each method works better.
Your best bet is testing your LLM running your own evals.
January 7, 2025 at 8:30 AM
In any case, for me, the key takeaway is that SO can decrease (or increase!) the performance in some tasks. Be conscious of that.
For now, there are no clear guidelines on where each method works better.
Your best bet is testing your LLM running your own evals.
For now, there are no clear guidelines on where each method works better.
Your best bet is testing your LLM running your own evals.
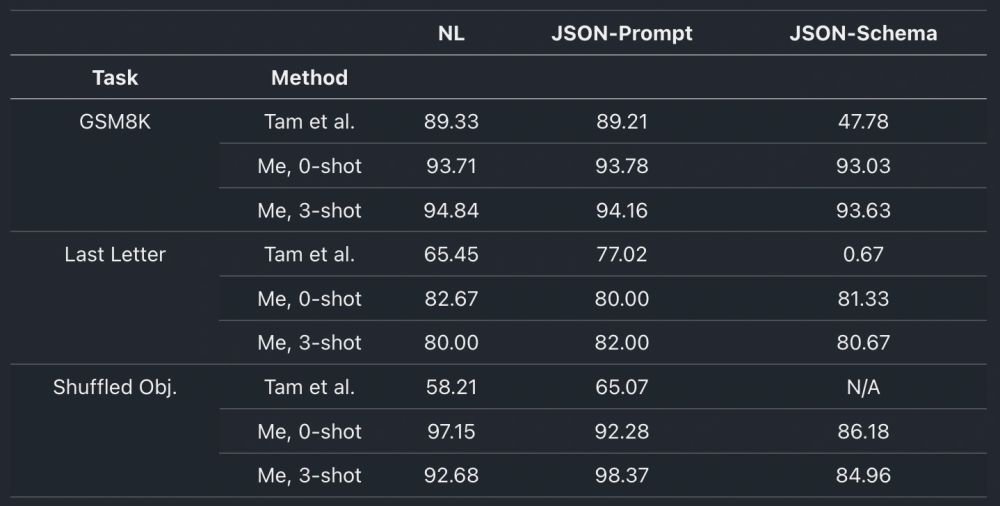
So, if you only consider constrained decoding (JSON-Schema), performance decreases across the board vs. NL.
Given this result and the key sorting issue, I'd suggest avoiding using JSON-Schema, unless you really need to. JSON-Prompt seems like a better alternative.
Given this result and the key sorting issue, I'd suggest avoiding using JSON-Schema, unless you really need to. JSON-Prompt seems like a better alternative.
January 7, 2025 at 8:30 AM
So, if you only consider constrained decoding (JSON-Schema), performance decreases across the board vs. NL.
Given this result and the key sorting issue, I'd suggest avoiding using JSON-Schema, unless you really need to. JSON-Prompt seems like a better alternative.
Given this result and the key sorting issue, I'd suggest avoiding using JSON-Schema, unless you really need to. JSON-Prompt seems like a better alternative.
Still, I could workaround the issue and re-run the benchmarks. NL and JSON-Prompt are tied.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
January 7, 2025 at 8:30 AM
Still, I could workaround the issue and re-run the benchmarks. NL and JSON-Prompt are tied.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
There's a propertyOrdering param documented in Vertex AI that should solve this: cloud.google.com/vertex-ai/g...
But it doesn't work in the Generative AI SDK. Other users have already reported this issue.
For the benchmarks, I excluded FC and used already sorted keys for JSON-Schema.
But it doesn't work in the Generative AI SDK. Other users have already reported this issue.
For the benchmarks, I excluded FC and used already sorted keys for JSON-Schema.
January 7, 2025 at 8:30 AM
There's a propertyOrdering param documented in Vertex AI that should solve this: cloud.google.com/vertex-ai/g...
But it doesn't work in the Generative AI SDK. Other users have already reported this issue.
For the benchmarks, I excluded FC and used already sorted keys for JSON-Schema.
But it doesn't work in the Generative AI SDK. Other users have already reported this issue.
For the benchmarks, I excluded FC and used already sorted keys for JSON-Schema.
Before generation, they reorder the schema keys. SO-Schema does it alphabetically and FC does it in a random manner (?). This can break your CoT.
You can fix SO-Schema by being smart with keys. Instead of "reasoning" and "answer" use something like "reasoning and "solution".
You can fix SO-Schema by being smart with keys. Instead of "reasoning" and "answer" use something like "reasoning and "solution".
January 7, 2025 at 8:30 AM
Before generation, they reorder the schema keys. SO-Schema does it alphabetically and FC does it in a random manner (?). This can break your CoT.
You can fix SO-Schema by being smart with keys. Instead of "reasoning" and "answer" use something like "reasoning and "solution".
You can fix SO-Schema by being smart with keys. Instead of "reasoning" and "answer" use something like "reasoning and "solution".
Gemini has 3 ways of generating SO:
1. Forced function calling (FC): ai.google.dev/gemini-api/...
2. Schema in prompt (SO-Prompt): ai.google.dev/gemini-api/...
3. Schema in model config (SO-Schema): ai.google.dev/gemini-api/...
SO-Prompt works well. But FC and SO-Schema have a major flaw.
1. Forced function calling (FC): ai.google.dev/gemini-api/...
2. Schema in prompt (SO-Prompt): ai.google.dev/gemini-api/...
3. Schema in model config (SO-Schema): ai.google.dev/gemini-api/...
SO-Prompt works well. But FC and SO-Schema have a major flaw.
January 7, 2025 at 8:30 AM
Gemini has 3 ways of generating SO:
1. Forced function calling (FC): ai.google.dev/gemini-api/...
2. Schema in prompt (SO-Prompt): ai.google.dev/gemini-api/...
3. Schema in model config (SO-Schema): ai.google.dev/gemini-api/...
SO-Prompt works well. But FC and SO-Schema have a major flaw.
1. Forced function calling (FC): ai.google.dev/gemini-api/...
2. Schema in prompt (SO-Prompt): ai.google.dev/gemini-api/...
3. Schema in model config (SO-Schema): ai.google.dev/gemini-api/...
SO-Prompt works well. But FC and SO-Schema have a major flaw.
Here's the post with all the code required to replicate the results: dylancastillo.co/posts/say-w...
Once or twice per month I write a technical article about AI here: subscribe.dylancastillo.co/
Once or twice per month I write a technical article about AI here: subscribe.dylancastillo.co/
Learn how to build AI products now
subscribe.dylancastillo.co
December 12, 2024 at 10:30 AM
Here's the post with all the code required to replicate the results: dylancastillo.co/posts/say-w...
Once or twice per month I write a technical article about AI here: subscribe.dylancastillo.co/
Once or twice per month I write a technical article about AI here: subscribe.dylancastillo.co/
I’m not saying you should default to unstructured outputs. In fact, I usually go with structured.
But it’s clear to me that neither structured nor unstructured outputs are always better, and choosing one or the other can often make a difference.
Test things yourself. Run your own evals and decide.
But it’s clear to me that neither structured nor unstructured outputs are always better, and choosing one or the other can often make a difference.
Test things yourself. Run your own evals and decide.
December 12, 2024 at 10:30 AM
I’m not saying you should default to unstructured outputs. In fact, I usually go with structured.
But it’s clear to me that neither structured nor unstructured outputs are always better, and choosing one or the other can often make a difference.
Test things yourself. Run your own evals and decide.
But it’s clear to me that neither structured nor unstructured outputs are always better, and choosing one or the other can often make a difference.
Test things yourself. Run your own evals and decide.
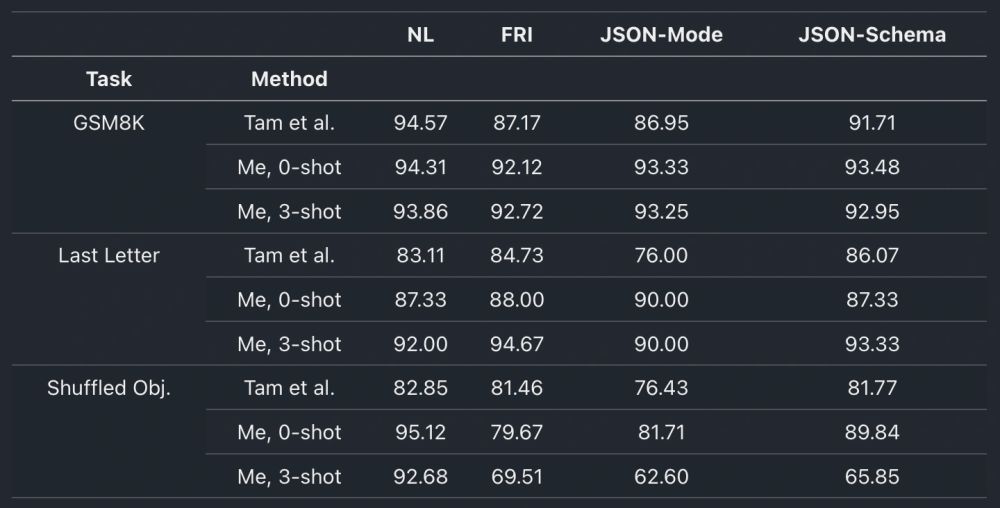
Then I switched to GPT-4o-mini, using LMSF's results as a reference.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
December 12, 2024 at 10:30 AM
Then I switched to GPT-4o-mini, using LMSF's results as a reference.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
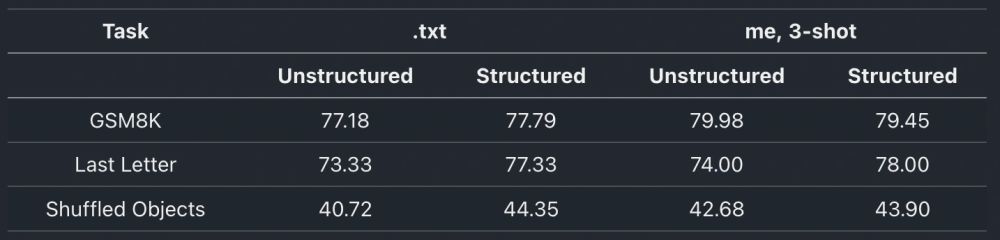
I began by replicating .txt's results using LLaMA-3-8B-Instruct (the model considered in the rebuttal).
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
December 12, 2024 at 10:30 AM
I began by replicating .txt's results using LLaMA-3-8B-Instruct (the model considered in the rebuttal).
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.