




Dylan
@dylancastillo.co
About: dylancastillo.co
Projects: dylancastillo.co/projects
Projects: dylancastillo.co/projects
AI-powered team collaboration

May 15, 2025 at 10:39 AM
AI-powered team collaboration
Somehow, my most random side project made it to the FT 😅
It's a quick test designed to assess your estimation skills: estimator.dylancastillo.co/
This is inspired by @codinghorror's great posts: blog.codinghorror.com/how-good-an...
archive.is/qDc0v
It's a quick test designed to assess your estimation skills: estimator.dylancastillo.co/
This is inspired by @codinghorror's great posts: blog.codinghorror.com/how-good-an...
archive.is/qDc0v

April 18, 2025 at 8:53 AM
Somehow, my most random side project made it to the FT 😅
It's a quick test designed to assess your estimation skills: estimator.dylancastillo.co/
This is inspired by @codinghorror's great posts: blog.codinghorror.com/how-good-an...
archive.is/qDc0v
It's a quick test designed to assess your estimation skills: estimator.dylancastillo.co/
This is inspired by @codinghorror's great posts: blog.codinghorror.com/how-good-an...
archive.is/qDc0v
I got an email from Google saying that one of my side projects, deepsheet, got 1,000% more clicks.
After a bit of digging, I realized that it was just due to people misspelling "DeepSeek."
There are now people out there who think that China's top AI is a 💩 that makes charts.
After a bit of digging, I realized that it was just due to people misspelling "DeepSeek."
There are now people out there who think that China's top AI is a 💩 that makes charts.



February 4, 2025 at 8:30 AM
I got an email from Google saying that one of my side projects, deepsheet, got 1,000% more clicks.
After a bit of digging, I realized that it was just due to people misspelling "DeepSeek."
There are now people out there who think that China's top AI is a 💩 that makes charts.
After a bit of digging, I realized that it was just due to people misspelling "DeepSeek."
There are now people out there who think that China's top AI is a 💩 that makes charts.

Always remember that using a response schema for an LLM is not the same as using one for your API.
Sounds easy, but happens to everyone.
Here's OpenAI breaking the CoT reasoning of an LLM judge.
Sounds easy, but happens to everyone.
Here's OpenAI breaking the CoT reasoning of an LLM judge.

January 14, 2025 at 8:30 AM
Always remember that using a response schema for an LLM is not the same as using one for your API.
Sounds easy, but happens to everyone.
Here's OpenAI breaking the CoT reasoning of an LLM judge.
Sounds easy, but happens to everyone.
Here's OpenAI breaking the CoT reasoning of an LLM judge.
Note to self: your only job is not to break the chain.


January 9, 2025 at 8:30 AM
Note to self: your only job is not to break the chain.
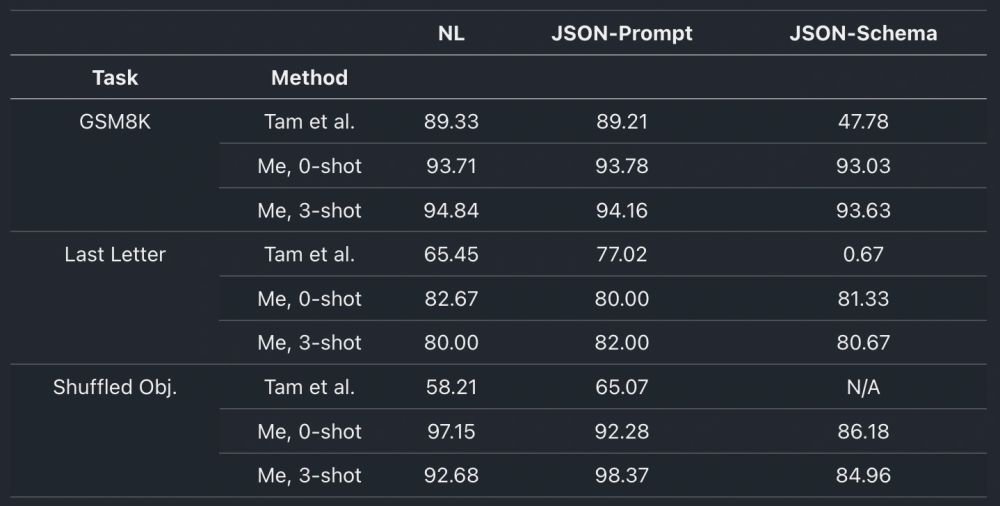
Still, I could workaround the issue and re-run the benchmarks. NL and JSON-Prompt are tied.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
January 7, 2025 at 8:30 AM
Still, I could workaround the issue and re-run the benchmarks. NL and JSON-Prompt are tied.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
But JSON-Schema performed worse than NL in 5 out of 6 tasks in my tests. Plus, in Shuffled Objects, it did so with a huge delta: 97.15% for NL vs. 86.18% for JSON-Schema.
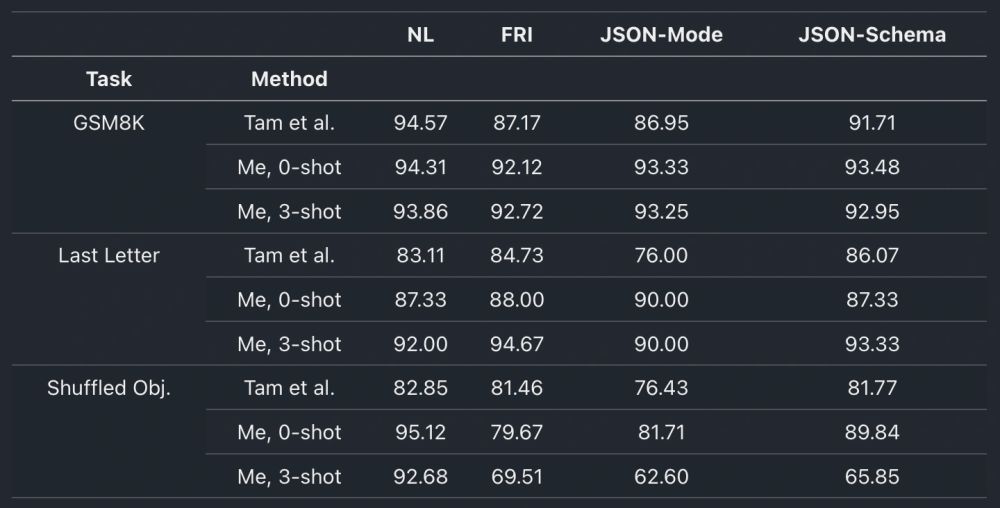
Then I switched to GPT-4o-mini, using LMSF's results as a reference.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
December 12, 2024 at 10:30 AM
Then I switched to GPT-4o-mini, using LMSF's results as a reference.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
Tweaked the prompts and improved all LMSF metrics except for NL in GSM8k.
GSM8k and Last Letter looked as expected (no diff).
But in Shuffled Obj. unstructured outputs clearly surpassed structured ones.
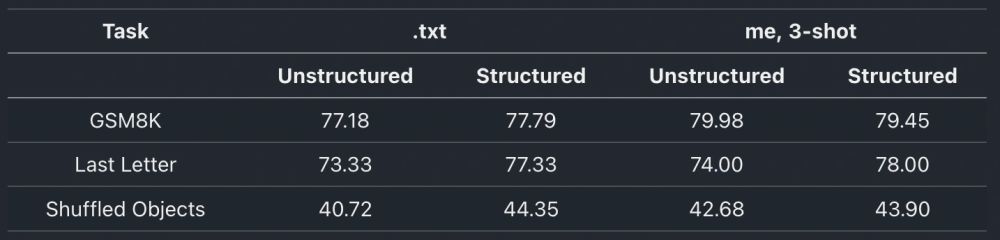
I began by replicating .txt's results using LLaMA-3-8B-Instruct (the model considered in the rebuttal).
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
December 12, 2024 at 10:30 AM
I began by replicating .txt's results using LLaMA-3-8B-Instruct (the model considered in the rebuttal).
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
I was able to reproduce the results and, after tweaking a few minor prompt issues, achieved a slight improvement in most metrics.
Structured outputs can decrease LLM's performance in some tasks
I replicated @willkurt.bsky.social / @dottxtai.bsky.social rebuttal of Let Me Speak Freely? (LMSF) using gpt-4o-mini
The rebuttal correctly highlights many flaws with the original study, but ironically, LMSF's conclusion still holds
I replicated @willkurt.bsky.social / @dottxtai.bsky.social rebuttal of Let Me Speak Freely? (LMSF) using gpt-4o-mini
The rebuttal correctly highlights many flaws with the original study, but ironically, LMSF's conclusion still holds

December 12, 2024 at 10:30 AM
Structured outputs can decrease LLM's performance in some tasks
I replicated @willkurt.bsky.social / @dottxtai.bsky.social rebuttal of Let Me Speak Freely? (LMSF) using gpt-4o-mini
The rebuttal correctly highlights many flaws with the original study, but ironically, LMSF's conclusion still holds
I replicated @willkurt.bsky.social / @dottxtai.bsky.social rebuttal of Let Me Speak Freely? (LMSF) using gpt-4o-mini
The rebuttal correctly highlights many flaws with the original study, but ironically, LMSF's conclusion still holds
Me after using ChatGPT to reproduce and patch a security vulnerability in a package downloaded 1 million times per month.

December 10, 2024 at 8:30 AM
Me after using ChatGPT to reproduce and patch a security vulnerability in a package downloaded 1 million times per month.