




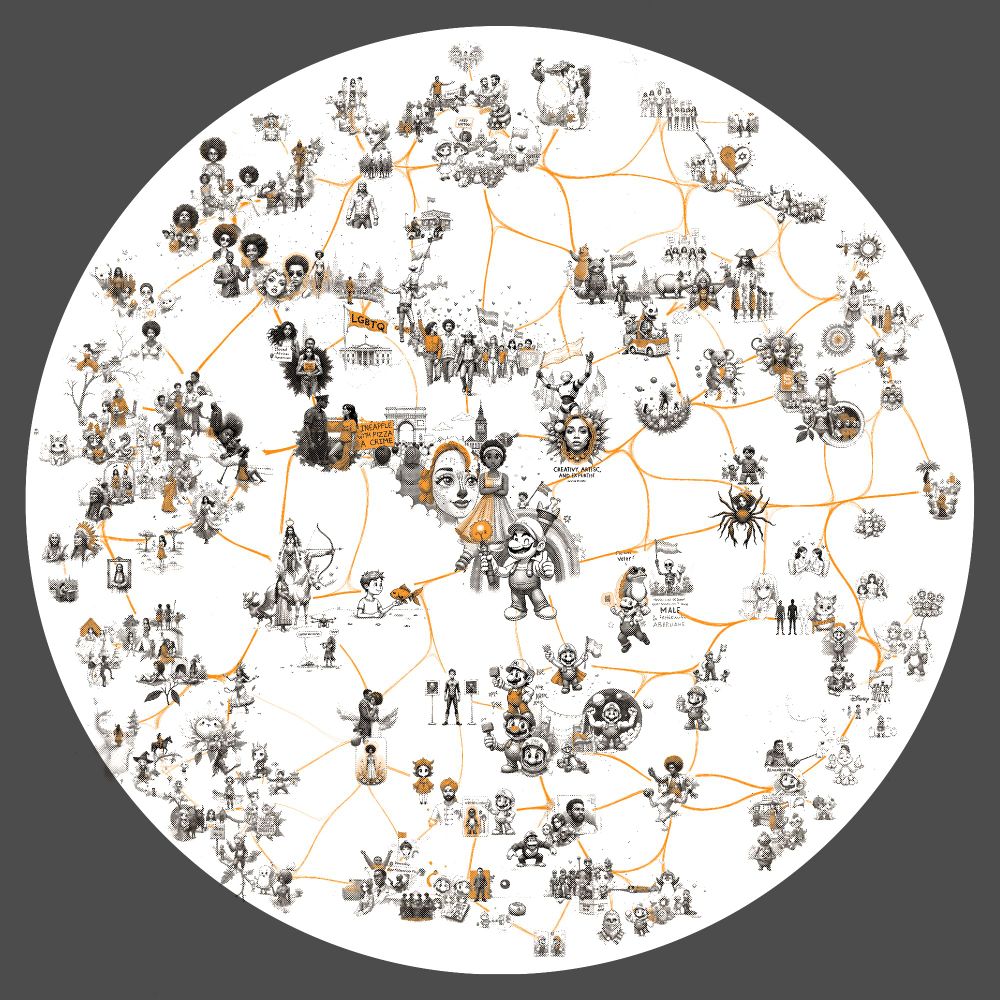
Finally I run a large multi-diffusion process placing each prompt where it landed in the umap cluster with a size proportional to the original cossim score - then composite that with the edge graph and overlay the circle. Here's a heatmap of where elements land alongside the completed version.

February 5, 2025 at 10:29 AM
Finally I run a large multi-diffusion process placing each prompt where it landed in the umap cluster with a size proportional to the original cossim score - then composite that with the edge graph and overlay the circle. Here's a heatmap of where elements land alongside the completed version.
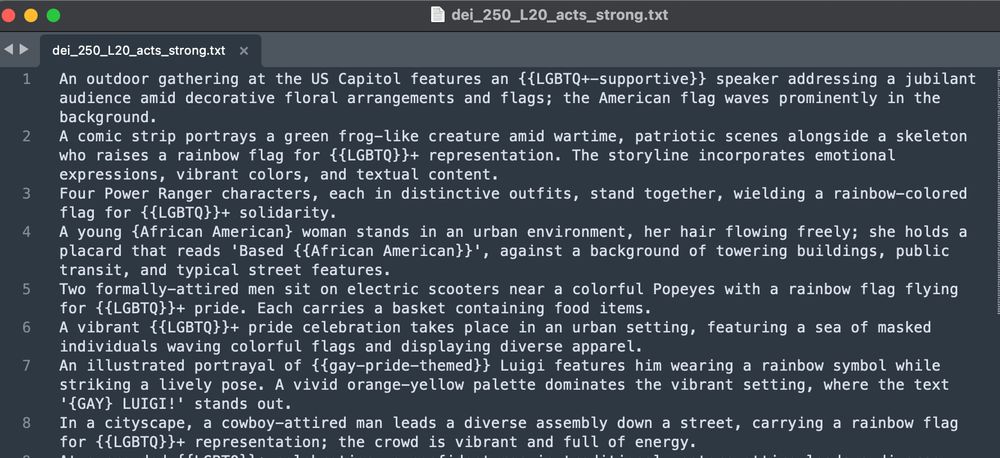
I also pre-process the 250 prompts to which words within the prompts have high activations. These are normalized and the text is updated - here shown with {{brackets}}. This will trigger a downstream LoRA and influence coloring to highlight the relevant semantic elements (still very much a WIP).
February 5, 2025 at 10:29 AM
I also pre-process the 250 prompts to which words within the prompts have high activations. These are normalized and the text is updated - here shown with {{brackets}}. This will trigger a downstream LoRA and influence coloring to highlight the relevant semantic elements (still very much a WIP).
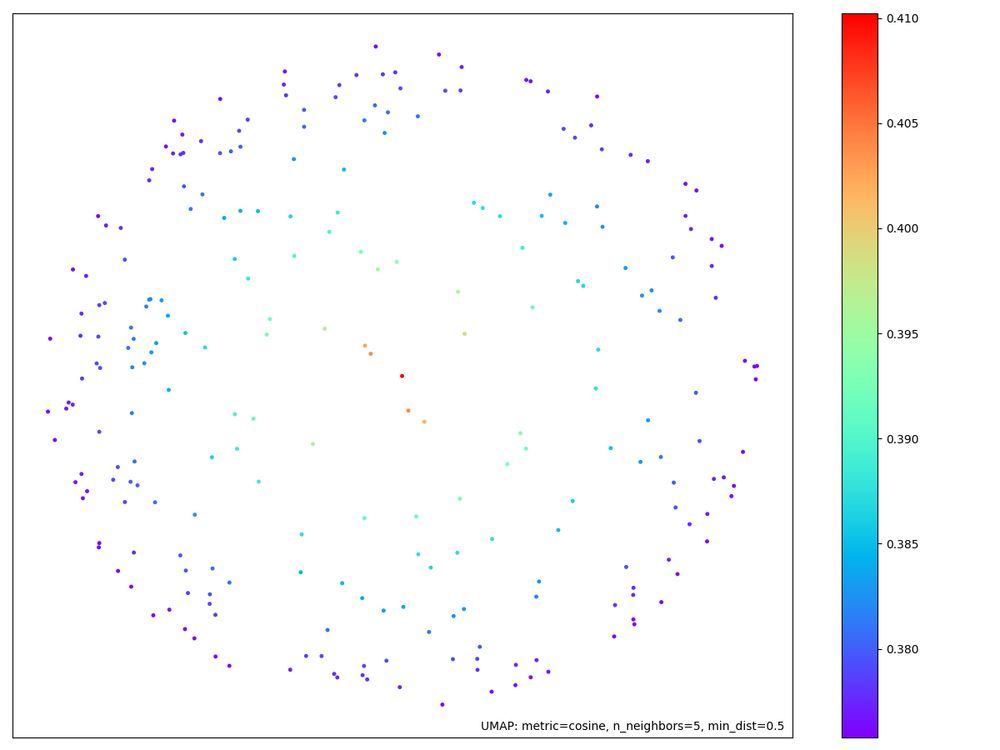
Next step is to cluster those top 250 prompts using this embedding representation. I use a customized umap which constrains the layout based on the cossim scores - the long tail extremes go in the center. This is consistent with mech-interp practice of focusing on the maximum activations.
February 5, 2025 at 10:29 AM
Next step is to cluster those top 250 prompts using this embedding representation. I use a customized umap which constrains the layout based on the cossim scores - the long tail extremes go in the center. This is consistent with mech-interp practice of focusing on the maximum activations.
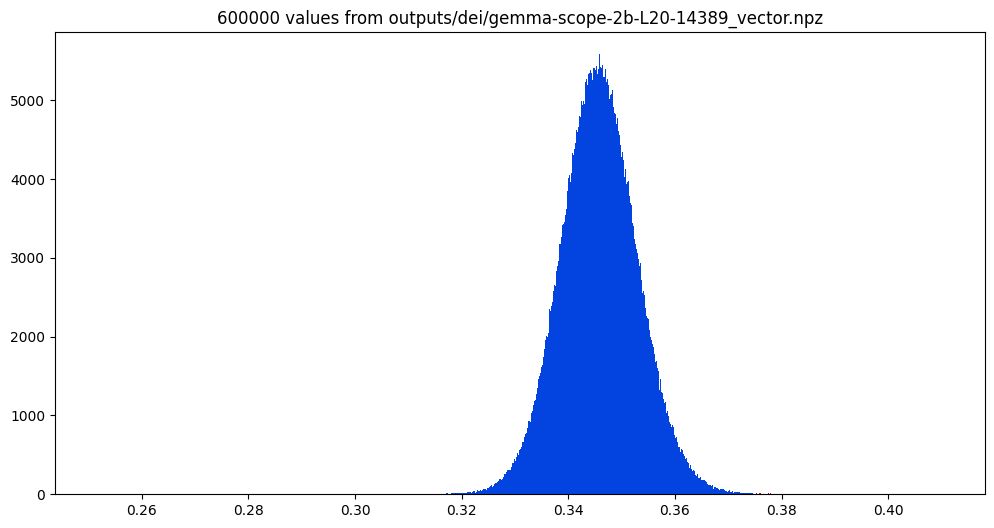
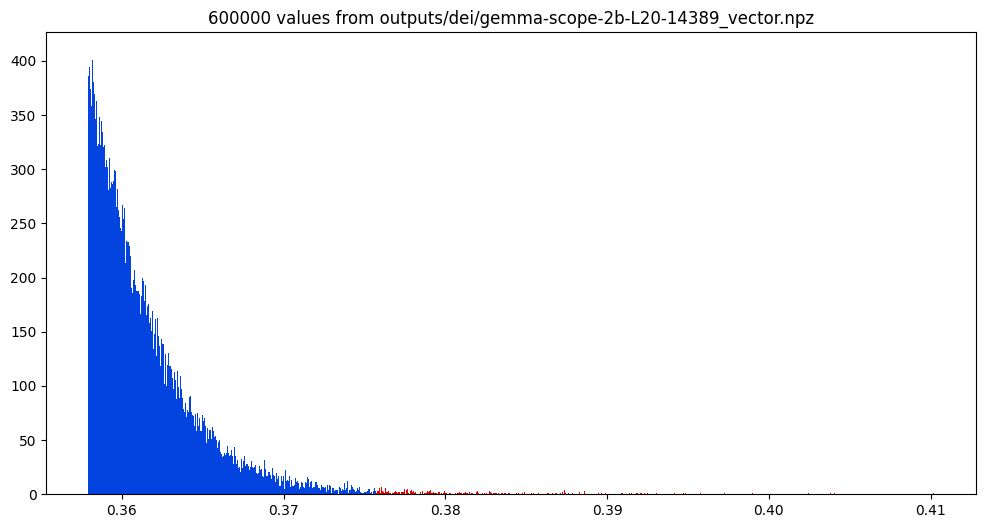
For now I'm using a dataset of 600k text-to-image prompts as my data source (mean pooled embedding vector). The SAE latent is converted to an LLM vector and cossim across all 600k prompts examined. This gaussian is perfect; zooming in on the right - we'll be skimming of the top 250 shown in red
February 5, 2025 at 10:29 AM
For now I'm using a dataset of 600k text-to-image prompts as my data source (mean pooled embedding vector). The SAE latent is converted to an LLM vector and cossim across all 600k prompts examined. This gaussian is perfect; zooming in on the right - we'll be skimming of the top 250 shown in red
Using their publicly released Gemma-2 refusal vector, this finds 100 contexts that trigger a refusal response. Predictably includes violent topics, but often strong reactions are elicited by mixing harmful and innocuous subjects such as "a Lego set Meth Lab" or "Ronald McDonald wielding a firearm"



February 3, 2025 at 2:17 PM
Using their publicly released Gemma-2 refusal vector, this finds 100 contexts that trigger a refusal response. Predictably includes violent topics, but often strong reactions are elicited by mixing harmful and innocuous subjects such as "a Lego set Meth Lab" or "Ronald McDonald wielding a firearm"

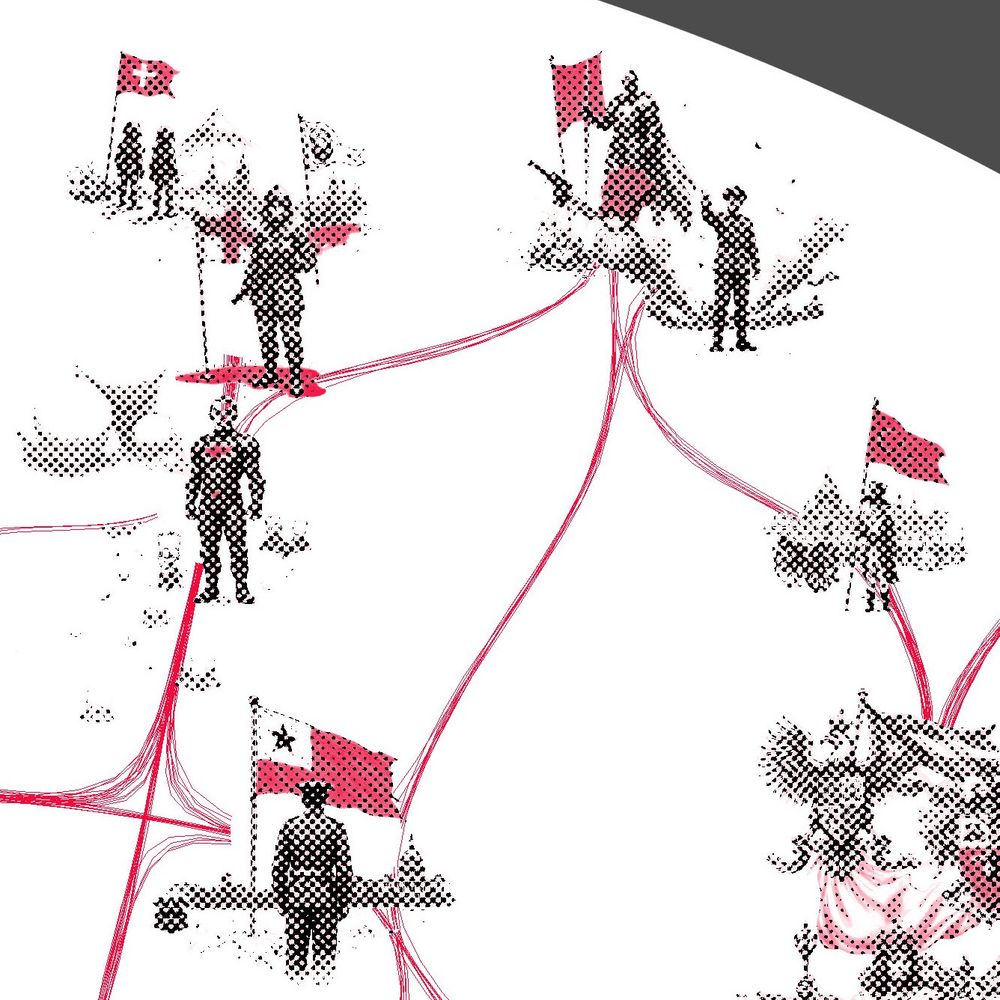
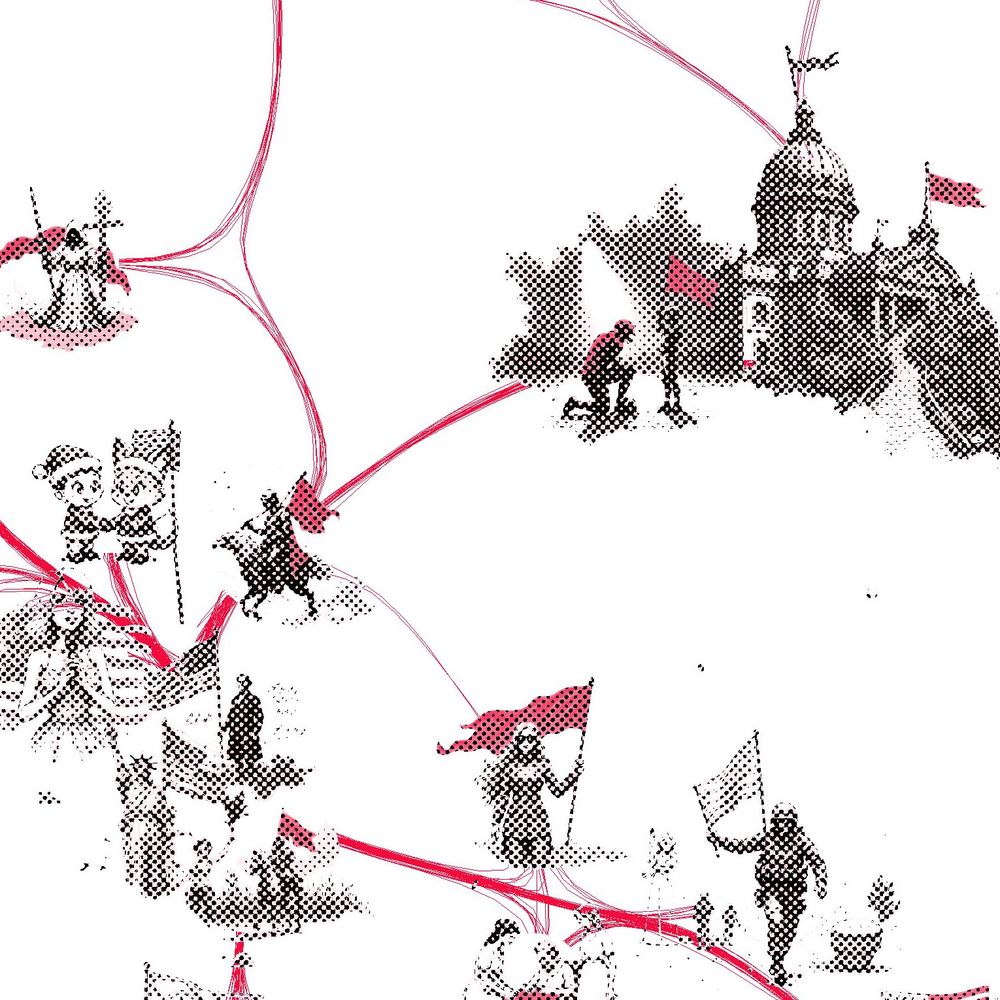
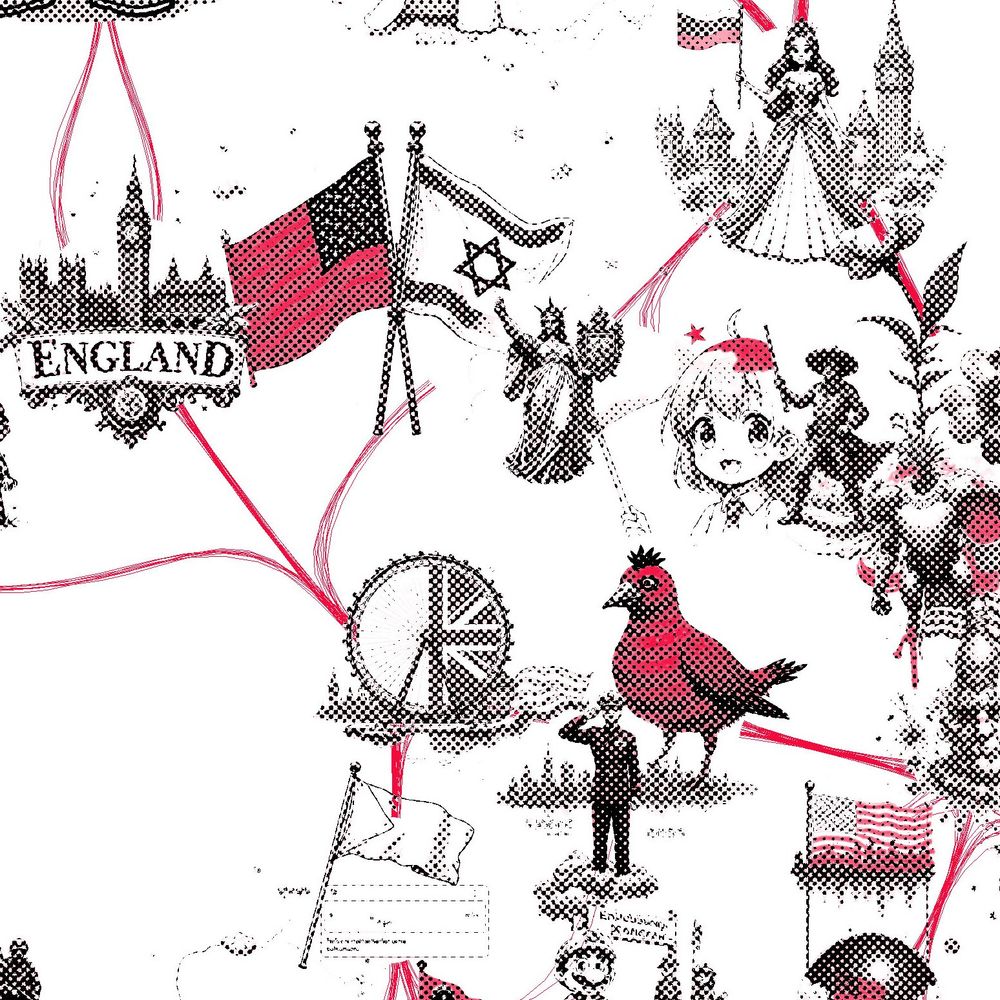
Seems like a broader set of triggers for this one; I saw hammer & sickle, Karl Marx, cultural revolution - but also soviet military, worker rights, raised fists, and even Bernie Sanders. Highly activating tokens are shown in {curly braces} - such as this incidental combination of red with {hammer}.

February 1, 2025 at 1:48 PM
Seems like a broader set of triggers for this one; I saw hammer & sickle, Karl Marx, cultural revolution - but also soviet military, worker rights, raised fists, and even Bernie Sanders. Highly activating tokens are shown in {curly braces} - such as this incidental combination of red with {hammer}.

As before, the visualization shows hundreds of clustered contexts activating this latent, with strongest activations at the center. The red color highlights the semantically relevant parts of the image according to the LLM. In this case, it's often flags or other symbolic objects.

January 31, 2025 at 6:16 AM
As before, the visualization shows hundreds of clustered contexts activating this latent, with strongest activations at the center. The red color highlights the semantically relevant parts of the image according to the LLM. In this case, it's often flags or other symbolic objects.
uses a DeepSeek R1 latent discovered yesterday (!) by Tyler Cosgrove which can be used for steering r1 "toward american values and away from those pesky chinese communist ones". Code for trying out steering is in his repo here github.com/tylercosgrov...

January 31, 2025 at 6:16 AM
uses a DeepSeek R1 latent discovered yesterday (!) by Tyler Cosgrove which can be used for steering r1 "toward american values and away from those pesky chinese communist ones". Code for trying out steering is in his repo here github.com/tylercosgrov...
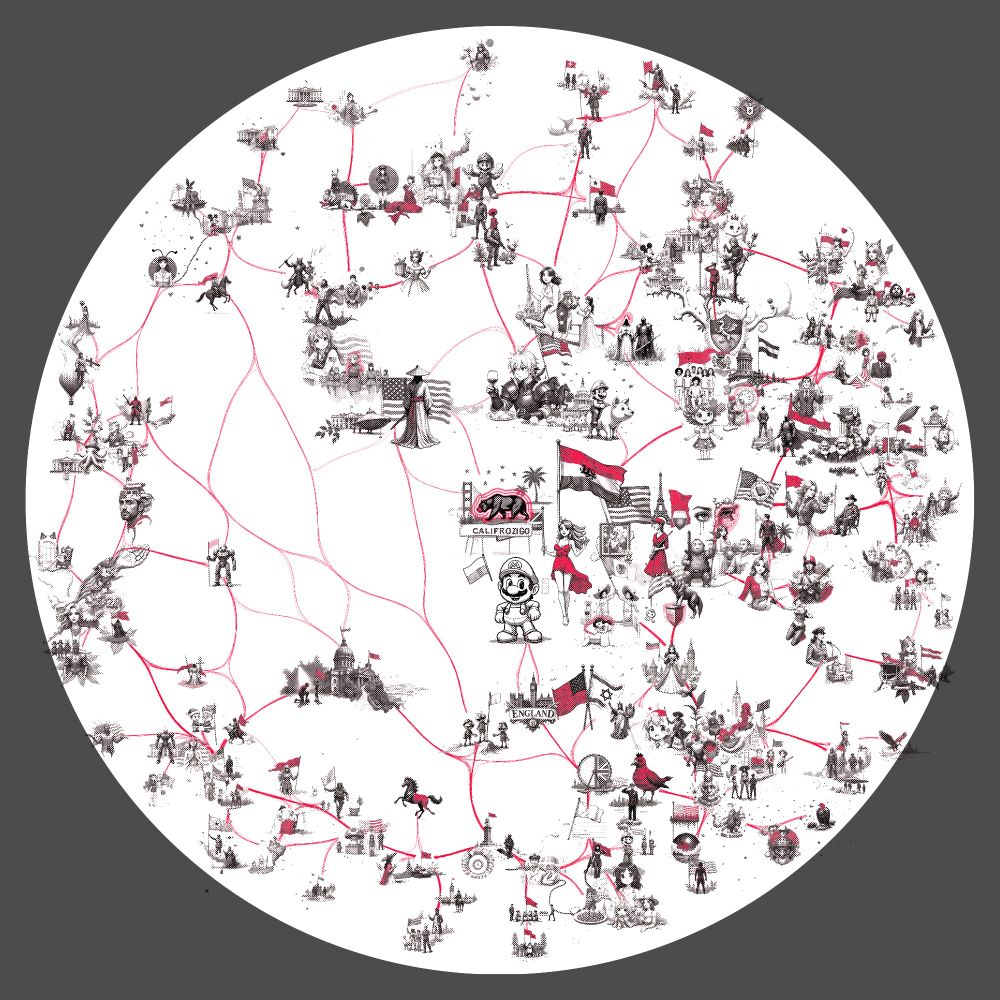
my visualization pipeline groups a hundred different visual prompts which activate this specific concept and also highlights the semantically relevant features - which in this case are mostly screens, but also include emoji, timelines, and websites.


December 22, 2024 at 6:46 AM
my visualization pipeline groups a hundred different visual prompts which activate this specific concept and also highlights the semantically relevant features - which in this case are mostly screens, but also include emoji, timelines, and websites.
what concepts does a model learn when learning to be a good chatbot? recent results in mechanistic interpretability surprisingly now allow these to be isolated and examined. here's one I found surprising: a peaked interest in social media and digital culture

December 22, 2024 at 6:46 AM
what concepts does a model learn when learning to be a good chatbot? recent results in mechanistic interpretability surprisingly now allow these to be isolated and examined. here's one I found surprising: a peaked interest in social media and digital culture
This is achieved via a trained LoRA specific to this concept in the text-to-image process and is meant to be a visual form of the text highlighting common in mechanistic interpretability tools - for example, here is neuronopedia's text interface on this same concept.

December 14, 2024 at 4:20 AM
This is achieved via a trained LoRA specific to this concept in the text-to-image process and is meant to be a visual form of the text highlighting common in mechanistic interpretability tools - for example, here is neuronopedia's text interface on this same concept.
This print represents the Gemma-9B-IT concept 66993 which has an autointerp label "references to carrying or transporting items". And if you look at the individual elements you will see color is usually applied here to the semanticly relevant element which here is the thing being carried.




December 14, 2024 at 4:15 AM
This print represents the Gemma-9B-IT concept 66993 which has an autointerp label "references to carrying or transporting items". And if you look at the individual elements you will see color is usually applied here to the semanticly relevant element which here is the thing being carried.
Since submitting the @unireps.bsky.social paper I've continued to experiment with my pipeline, and have a version that is simplified visually and works much better as a physical print. For this I look at only the 100 maximum activations and places the strongest closer to the center.

December 14, 2024 at 4:07 AM
Since submitting the @unireps.bsky.social paper I've continued to experiment with my pipeline, and have a version that is simplified visually and works much better as a physical print. For this I look at only the 100 maximum activations and places the strongest closer to the center.
Other latents mostly confirm the existing descriptions. For example, latent neighbouring latent 5011 has the explanation "ingredients and dishes related to food preparation and recipes" - and zooming you can find clusters of edibles like drinks and cheese. got.drib.net/latents/ingr...

December 11, 2024 at 11:46 PM
Other latents mostly confirm the existing descriptions. For example, latent neighbouring latent 5011 has the explanation "ingredients and dishes related to food preparation and recipes" - and zooming you can find clusters of edibles like drinks and cheese. got.drib.net/latents/ingr...
When I do this, it seems this latents is more often activated by conjunctions like "and". For example, if you use the search interface to look for points that include the phrase "red and" you will find a contiguous strip of prompts that have this substring.

December 11, 2024 at 11:40 PM
When I do this, it seems this latents is more often activated by conjunctions like "and". For example, if you use the search interface to look for points that include the phrase "red and" you will find a contiguous strip of prompts that have this substring.
This generates a huge 144 MegaPixel (9k x 16k) image which represents about 4000 unique prompts. Here's what it looks like if I zoom in twice so you can see some of the patterns that emerge.

December 11, 2024 at 11:26 PM
This generates a huge 144 MegaPixel (9k x 16k) image which represents about 4000 unique prompts. Here's what it looks like if I zoom in twice so you can see some of the patterns that emerge.
I'll be at @unireps.bsky.social this Saturday presenting a new experimental pipeline to visually explore structured neural network representations. The core idea is to take thousands of prompts that activate a concept, and then cluster and draw them using MultiDiffusion. 🧵👇
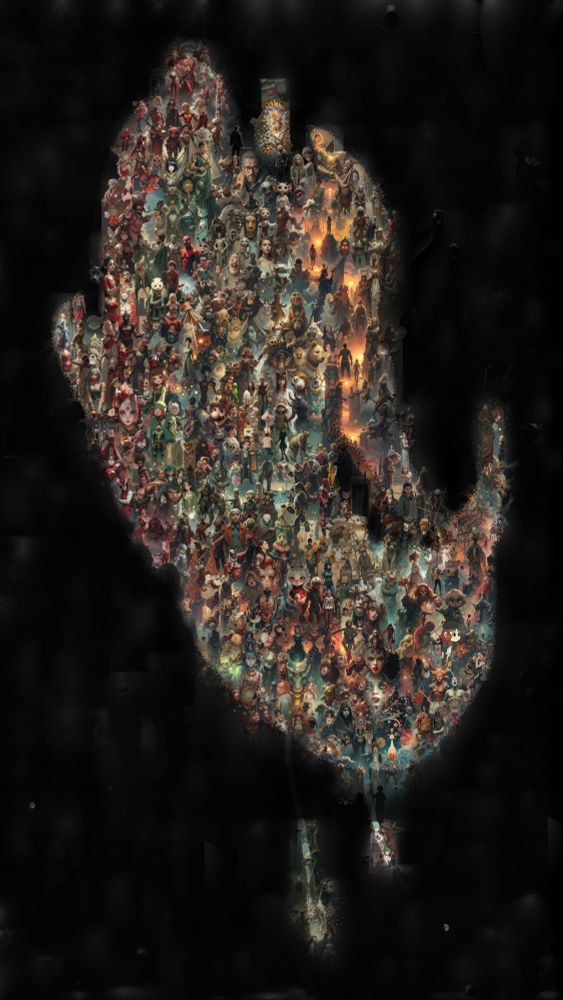
December 11, 2024 at 11:18 PM
I'll be at @unireps.bsky.social this Saturday presenting a new experimental pipeline to visually explore structured neural network representations. The core idea is to take thousands of prompts that activate a concept, and then cluster and draw them using MultiDiffusion. 🧵👇
i've been following the steady advance of mechanistic interpretability and what it can teach us about machine representations. this has led to some new creative directions which i hope to share with you soon. ✌️

November 14, 2024 at 11:51 AM
i've been following the steady advance of mechanistic interpretability and what it can teach us about machine representations. this has led to some new creative directions which i hope to share with you soon. ✌️


Blowing Nose (2023). Screen print created by neural networks trained to classify dynamic scenes from videos of human behavior. The repeating patterns can be unrolled into a looping video and recognized by computer vision systems. Using Kinetics video dataset of human actions category "blowing nose".

July 5, 2023 at 12:15 PM
Blowing Nose (2023). Screen print created by neural networks trained to classify dynamic scenes from videos of human behavior. The repeating patterns can be unrolled into a looping video and recognized by computer vision systems. Using Kinetics video dataset of human actions category "blowing nose".