



Bruce Gao
@drbrucegao.bsky.social
A full-time clinical microbiologist with a passion for medical economics, I also run a side tutoring business that helps Australian high school students explore opportunities at top-tier US colleges. www.bostoniacs.com
Reposted by Bruce Gao

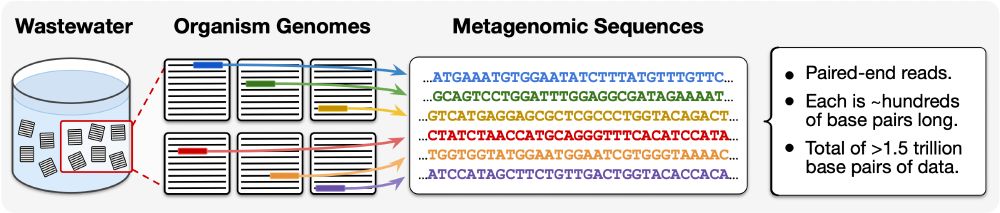
📊The data behind METAGENE-1:
- Brand-new dataset collected with experts from Southern California & Missouri
- 1.5 trillion base pairs from diverse wastewater samples
- Short reads (100–300 BPs), deep sequencing at scale
- Byte-Pair Encoding customized for genomic sequences
🧵3/
- Brand-new dataset collected with experts from Southern California & Missouri
- 1.5 trillion base pairs from diverse wastewater samples
- Short reads (100–300 BPs), deep sequencing at scale
- Byte-Pair Encoding customized for genomic sequences
🧵3/
January 6, 2025 at 5:04 PM
📊The data behind METAGENE-1:
- Brand-new dataset collected with experts from Southern California & Missouri
- 1.5 trillion base pairs from diverse wastewater samples
- Short reads (100–300 BPs), deep sequencing at scale
- Byte-Pair Encoding customized for genomic sequences
🧵3/
- Brand-new dataset collected with experts from Southern California & Missouri
- 1.5 trillion base pairs from diverse wastewater samples
- Short reads (100–300 BPs), deep sequencing at scale
- Byte-Pair Encoding customized for genomic sequences
🧵3/