



Alexander Doria
@dorialexander.bsky.social
LLM for the commons.
i hope it’s not sentient
November 11, 2025 at 12:21 PM
i hope it’s not sentient
Oh it's recent materials. There is a lot of academic papers in open science under free license (even more so during the past decade). Public domain work can still be relevant for pure reasoning, but yeah we'll need specific pipelines/guardrails.
November 11, 2025 at 11:47 AM
Oh it's recent materials. There is a lot of academic papers in open science under free license (even more so during the past decade). Public domain work can still be relevant for pure reasoning, but yeah we'll need specific pipelines/guardrails.
To be seen. Synthetic data from models allowing for output reuse does solve releasability which I admit is the biggest block on the business side and we'll do much more of this. We might still do pure base models for the next Common Corpus.
November 11, 2025 at 11:46 AM
To be seen. Synthetic data from models allowing for output reuse does solve releasability which I admit is the biggest block on the business side and we'll do much more of this. We might still do pure base models for the next Common Corpus.
Reasoning models are pretrained from scratch (though you might debate if it's still "pretraining"). For synthetic data generation we used finetuned Qwen/Deepseek.
November 11, 2025 at 11:40 AM
Reasoning models are pretrained from scratch (though you might debate if it's still "pretraining"). For synthetic data generation we used finetuned Qwen/Deepseek.
Well we do have a lot of academic materials in Common Corpus (compliant too…)
November 11, 2025 at 11:32 AM
Well we do have a lot of academic materials in Common Corpus (compliant too…)
Yes. The key thing is that we'll need to rethink the synthetic pipeline to make it significantly more demanding, maybe less upsampling/more diversity too since larger models memorize better.
November 11, 2025 at 10:56 AM
Yes. The key thing is that we'll need to rethink the synthetic pipeline to make it significantly more demanding, maybe less upsampling/more diversity too since larger models memorize better.
No we used open weight models. Initial synth seed from R1/GPT-OSS and then finetuning of qwen/deepseek-prover.
November 11, 2025 at 10:55 AM
No we used open weight models. Initial synth seed from R1/GPT-OSS and then finetuning of qwen/deepseek-prover.
Actually you’re not going to believe it but name already taken (for sharing ai datasets).

November 11, 2025 at 8:55 AM
Actually you’re not going to believe it but name already taken (for sharing ai datasets).
We now call deep layer models "baguette" and I really hope it will stick too.
November 11, 2025 at 8:01 AM
We now call deep layer models "baguette" and I really hope it will stick too.
Not yet but since tinystories is gpt-2 synth, I do expect Monad to write better stories.
November 11, 2025 at 7:59 AM
Not yet but since tinystories is gpt-2 synth, I do expect Monad to write better stories.
yes totally. we're going to ease dataset integration with nanochat, so should be very straightforward.
November 10, 2025 at 8:00 PM
yes totally. we're going to ease dataset integration with nanochat, so should be very straightforward.
We started with that. Basically same performance except straight training allows you to modify the model extensively, change the tokenizer, stack layers.
November 10, 2025 at 7:09 PM
We started with that. Basically same performance except straight training allows you to modify the model extensively, change the tokenizer, stack layers.
We believe synthetic data is both a resource to build specialized small models and a general process of augmentation/enrichment for the data layer in LLM applications. Beyond research, this will now be a major factor in our new phase of product development.
November 10, 2025 at 5:34 PM
We believe synthetic data is both a resource to build specialized small models and a general process of augmentation/enrichment for the data layer in LLM applications. Beyond research, this will now be a major factor in our new phase of product development.
Through this release, we aim both to support the emerging ecosystem for pretraining research (NanoGPT, NanoChat), explainability (you can literally look at Monad under a microscope) and the tooling orchestration around frontier models.
November 10, 2025 at 5:34 PM
Through this release, we aim both to support the emerging ecosystem for pretraining research (NanoGPT, NanoChat), explainability (you can literally look at Monad under a microscope) and the tooling orchestration around frontier models.
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).

November 10, 2025 at 5:33 PM
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad

November 10, 2025 at 5:33 PM
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...

November 10, 2025 at 5:32 PM
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
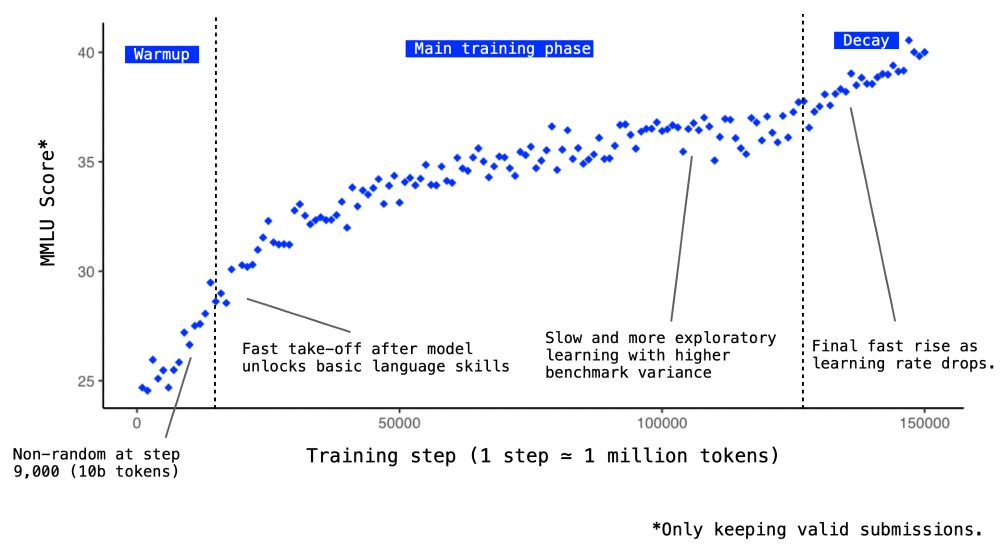
November 10, 2025 at 5:32 PM
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.

November 10, 2025 at 5:31 PM
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.
SYNTH is a radical departure from the classic pre-training recipe: what if we trained for reasoning and focused on the assimilation of knowledge and skill that matters? At its core it’s an upsampling of Wikipedia 50,000 “vital” articles. huggingface.co/datasets/Ple...
November 10, 2025 at 5:30 PM
SYNTH is a radical departure from the classic pre-training recipe: what if we trained for reasoning and focused on the assimilation of knowledge and skill that matters? At its core it’s an upsampling of Wikipedia 50,000 “vital” articles. huggingface.co/datasets/Ple...