



Alexander Doria
@dorialexander.bsky.social
LLM for the commons.
you’ll never guess what i have for lunch

November 11, 2025 at 12:21 PM
you’ll never guess what i have for lunch
Actually you’re not going to believe it but name already taken (for sharing ai datasets).

November 11, 2025 at 8:55 AM
Actually you’re not going to believe it but name already taken (for sharing ai datasets).
Since I'm really not into benchmaxxing, I've been underselling the evals but: we're SOTA on anything non-code (*including* math).

November 10, 2025 at 9:18 PM
Since I'm really not into benchmaxxing, I've been underselling the evals but: we're SOTA on anything non-code (*including* math).
Actually if you're ever puzzled by the name, you can simply… ask the model.
(we did a relatively good job at personality tuning).
(we did a relatively good job at personality tuning).

November 10, 2025 at 5:47 PM
Actually if you're ever puzzled by the name, you can simply… ask the model.
(we did a relatively good job at personality tuning).
(we did a relatively good job at personality tuning).
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).

November 10, 2025 at 5:33 PM
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad

November 10, 2025 at 5:33 PM
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...

November 10, 2025 at 5:32 PM
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
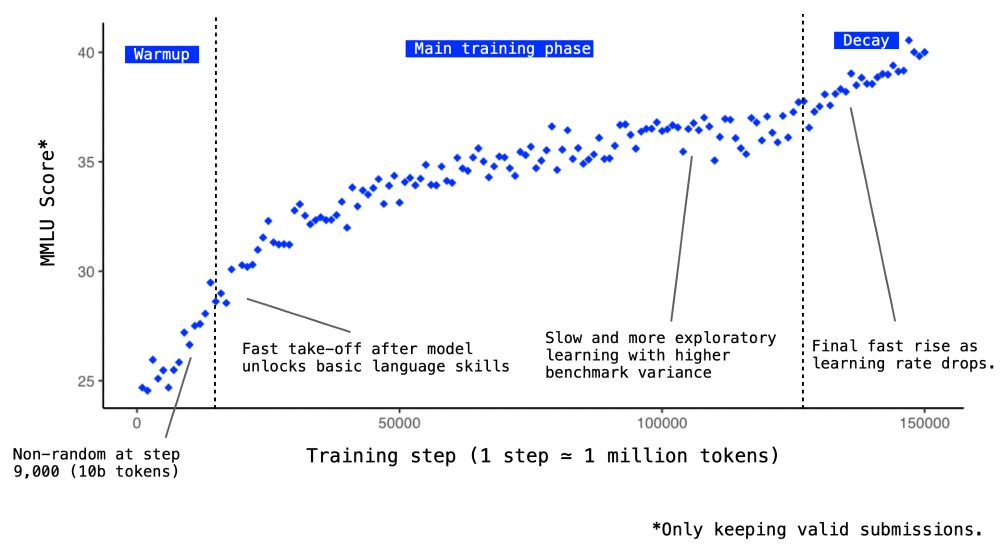
November 10, 2025 at 5:32 PM
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.

November 10, 2025 at 5:31 PM
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.
Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...

November 10, 2025 at 5:30 PM
Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...
feeling like the end of ongoing ai copyright wars. labs settling and if i read correctly, stability ai getting the most positive outcome from getty images case.

November 4, 2025 at 10:49 AM
feeling like the end of ongoing ai copyright wars. labs settling and if i read correctly, stability ai getting the most positive outcome from getty images case.
bf16 halloween might be already ending. according to a bytedance engineer could just have been another flash-attention bug.

November 2, 2025 at 1:30 PM
bf16 halloween might be already ending. according to a bytedance engineer could just have been another flash-attention bug.
i guess the post-modern future of eu politics was hungary all along.

November 2, 2025 at 11:04 AM
i guess the post-modern future of eu politics was hungary all along.
ok i have a terribly ironic suspicion now. can you see it too?

November 1, 2025 at 8:01 PM
ok i have a terribly ironic suspicion now. can you see it too?
you are not going to believe it, but pringles may not even be the best gem in this paper.

November 1, 2025 at 2:54 PM
you are not going to believe it, but pringles may not even be the best gem in this paper.
well yeah but if you scroll down to my latest hiring call. not even close (though i agree bluesky is almost competitive with LI, suprisingly dead for anything serious in ai).

November 1, 2025 at 12:32 PM
well yeah but if you scroll down to my latest hiring call. not even close (though i agree bluesky is almost competitive with LI, suprisingly dead for anything serious in ai).
funnily enough: i know very well the authors of the pringles paper. we are in the same italian group chat and just sooner…

November 1, 2025 at 12:28 PM
funnily enough: i know very well the authors of the pringles paper. we are in the same italian group chat and just sooner…
A propos of nothing, maybe my favorite Sartre play.

November 1, 2025 at 11:49 AM
A propos of nothing, maybe my favorite Sartre play.
ml halloween costume concept

October 31, 2025 at 10:08 PM
ml halloween costume concept
I’ve been more appreciative of bluesky lately but, still, this is not great.

October 31, 2025 at 8:22 PM
I’ve been more appreciative of bluesky lately but, still, this is not great.
So we're hiring.

October 28, 2025 at 4:01 PM
So we're hiring.
i guess grokipedia is just the wikipedia copy they use in pretraining: typical bad formatting when you don't use the very clean scrap recently made available by @wikimediafoundation.org for structured wikipedia.

October 28, 2025 at 1:09 PM
i guess grokipedia is just the wikipedia copy they use in pretraining: typical bad formatting when you don't use the very clean scrap recently made available by @wikimediafoundation.org for structured wikipedia.
Due to the open data paradox we identified in the Common Corpus paper, it's very hard to expand language coverage without familiarity with local institutions/initiatives as many non-English open resources have limited global visibility.

October 27, 2025 at 3:22 PM
Due to the open data paradox we identified in the Common Corpus paper, it's very hard to expand language coverage without familiarity with local institutions/initiatives as many non-English open resources have limited global visibility.
Release of German Commons that started as a linguistic spin-off from Common Corpus and sharing the same philosophy of fully releasable and reproducible data. huggingface.co/datasets/cor...

October 27, 2025 at 3:21 PM
Release of German Commons that started as a linguistic spin-off from Common Corpus and sharing the same philosophy of fully releasable and reproducible data. huggingface.co/datasets/cor...
New MiniMax release today. Still waiting for the tech report, but the blogpost makes a compelling case for mastering the technology end-to-end to get actual agentic automation www.minimax.io/news/minimax...

October 27, 2025 at 12:15 PM
New MiniMax release today. Still waiting for the tech report, but the blogpost makes a compelling case for mastering the technology end-to-end to get actual agentic automation www.minimax.io/news/minimax...