



Dan Busbridge
@dbusbridge.bsky.social
Machine Learning Research @ Apple (opinions are my own)
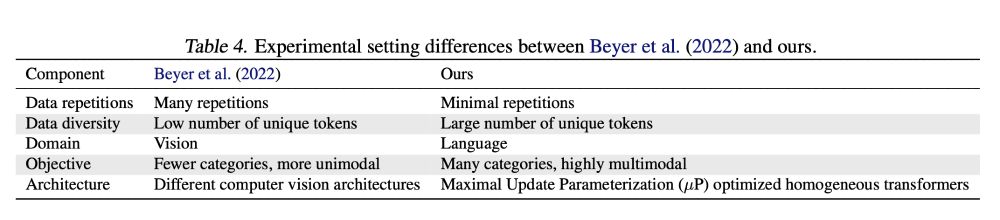
These differences, outlined in Table 4, relate primarily to the relationship between student and teacher.
February 13, 2025 at 9:52 PM
These differences, outlined in Table 4, relate primarily to the relationship between student and teacher.
5. Using fixed aspect ratio (width/depth) models, enables using N as non-embedding model parameters, and allows a simple, accurate expression for FLOPs/token which works for large contexts. I think this would be useful for the community to adopt generally.
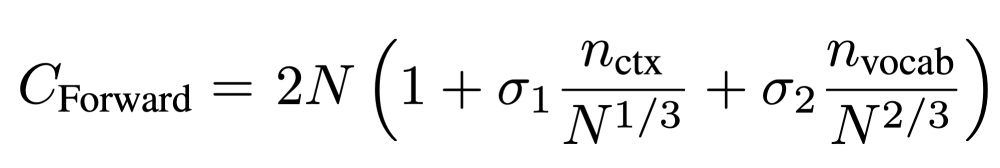
February 13, 2025 at 9:50 PM
5. Using fixed aspect ratio (width/depth) models, enables using N as non-embedding model parameters, and allows a simple, accurate expression for FLOPs/token which works for large contexts. I think this would be useful for the community to adopt generally.
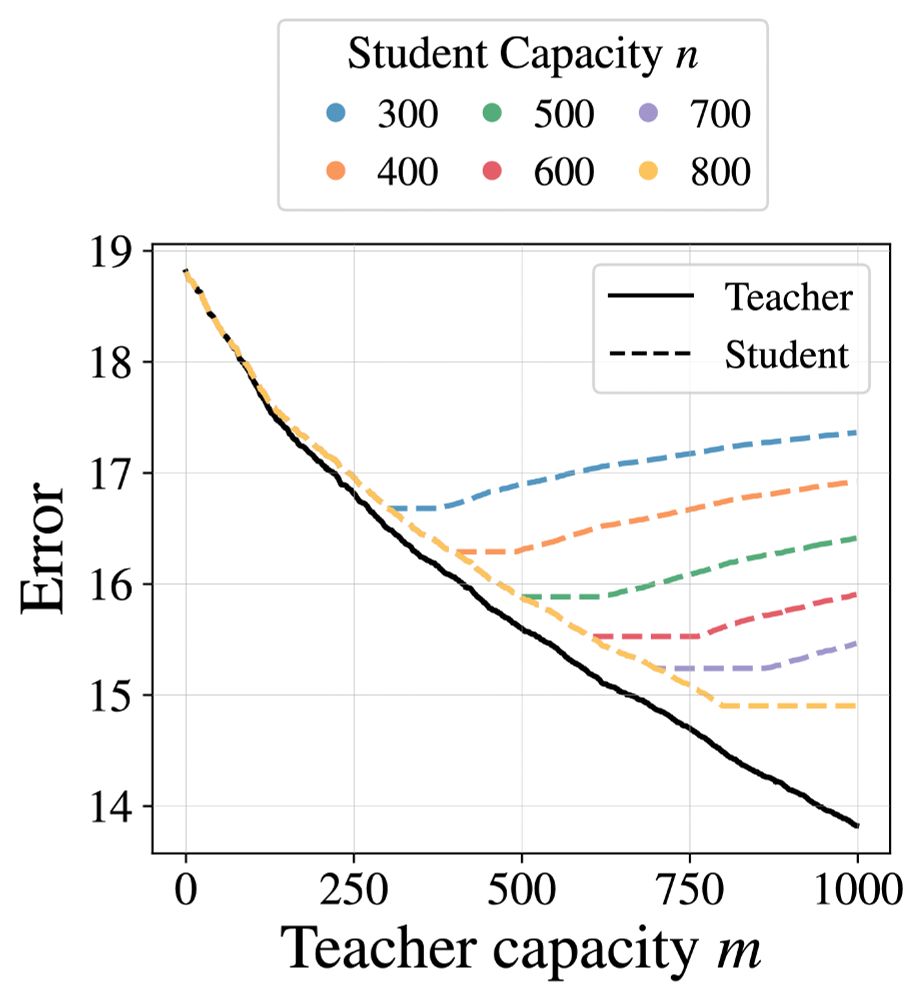
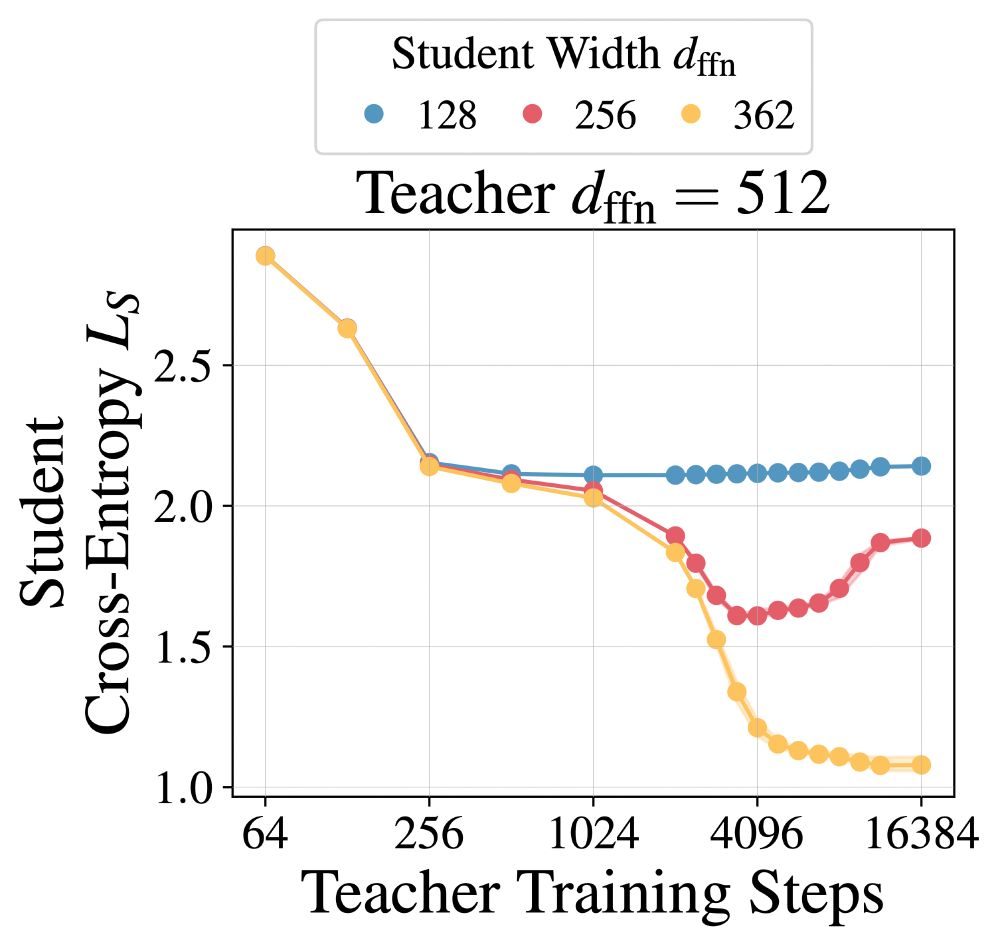
4. We present the first synthetic demonstrations of the distillation capacity gap phenomenon, using kernel regression (left) and pointer mapping problems (right). This will help us better understand why making a teacher too strong can harm student performance.
February 13, 2025 at 9:50 PM
4. We present the first synthetic demonstrations of the distillation capacity gap phenomenon, using kernel regression (left) and pointer mapping problems (right). This will help us better understand why making a teacher too strong can harm student performance.
3. Training on the teacher logit signal produces a calibrated student (left) whereas training on the teacher top-1 does not (right). This can be understood using proper scoring metrics, but it is nice to observe clearly.
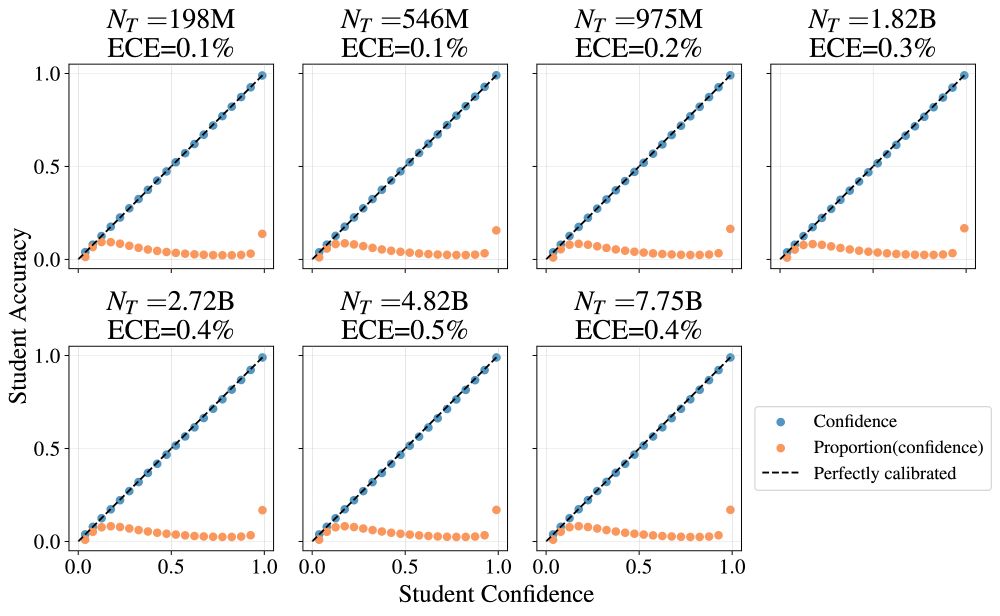
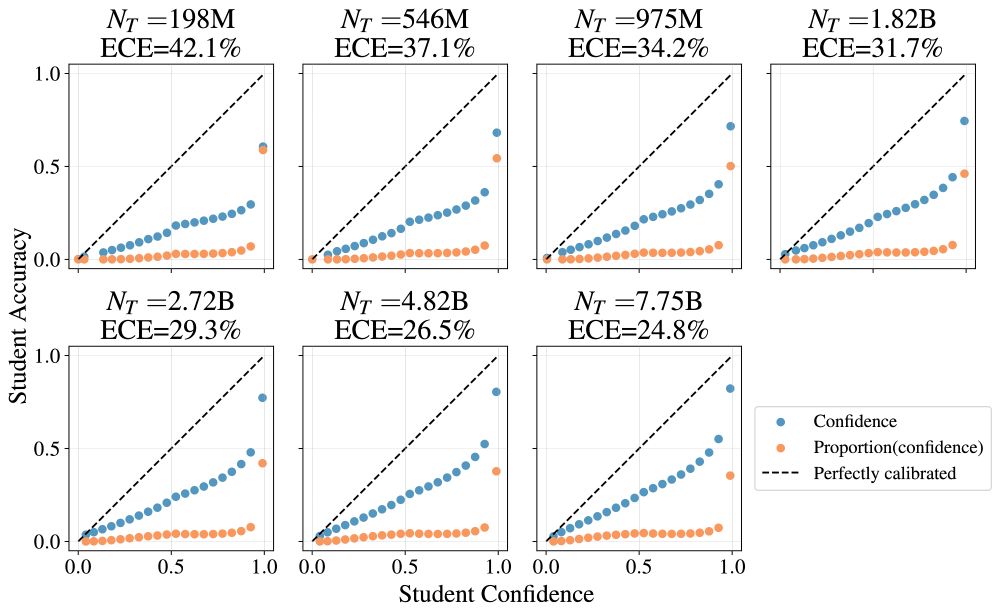
February 13, 2025 at 9:50 PM
3. Training on the teacher logit signal produces a calibrated student (left) whereas training on the teacher top-1 does not (right). This can be understood using proper scoring metrics, but it is nice to observe clearly.
2. Maximum Update Parameterization (MuP, arxiv.org/abs/2011.14522) works out of the box for distillation. The distillation optimal learning rate is the same as the base learning rate for teacher training. This simplified our setup a lot.
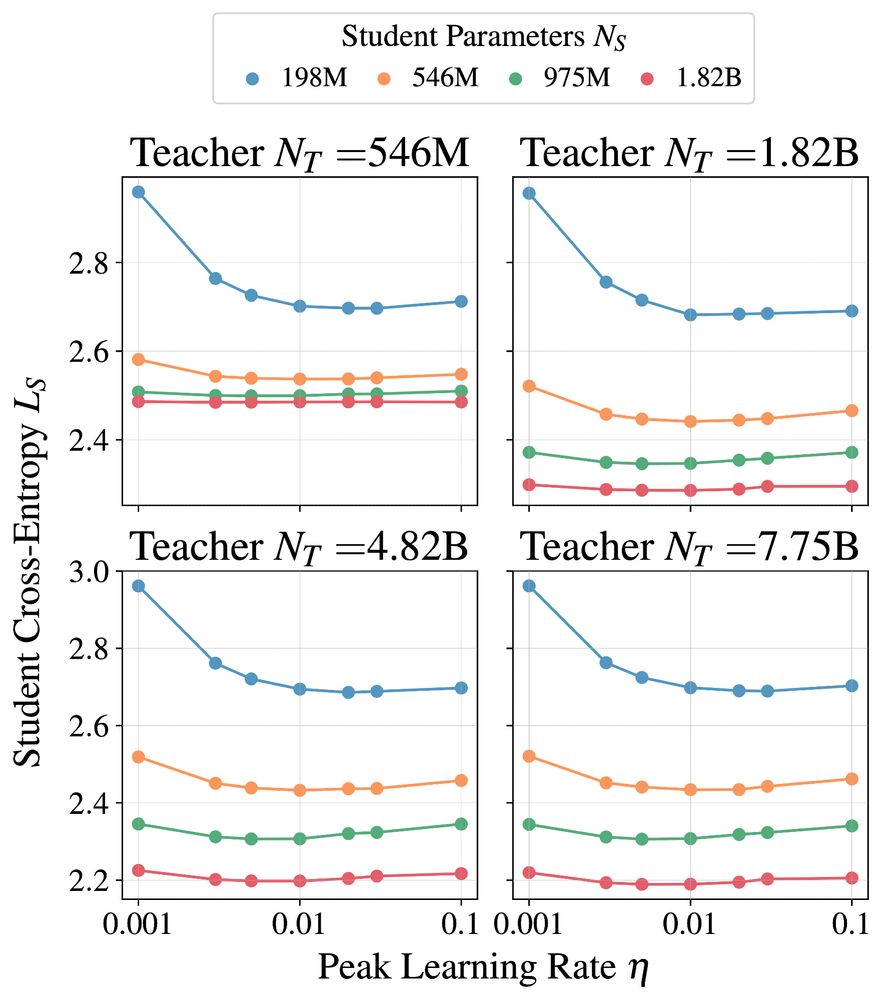
February 13, 2025 at 9:50 PM
2. Maximum Update Parameterization (MuP, arxiv.org/abs/2011.14522) works out of the box for distillation. The distillation optimal learning rate is the same as the base learning rate for teacher training. This simplified our setup a lot.
We also investigated many other aspects of distillation that should be useful for the community.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
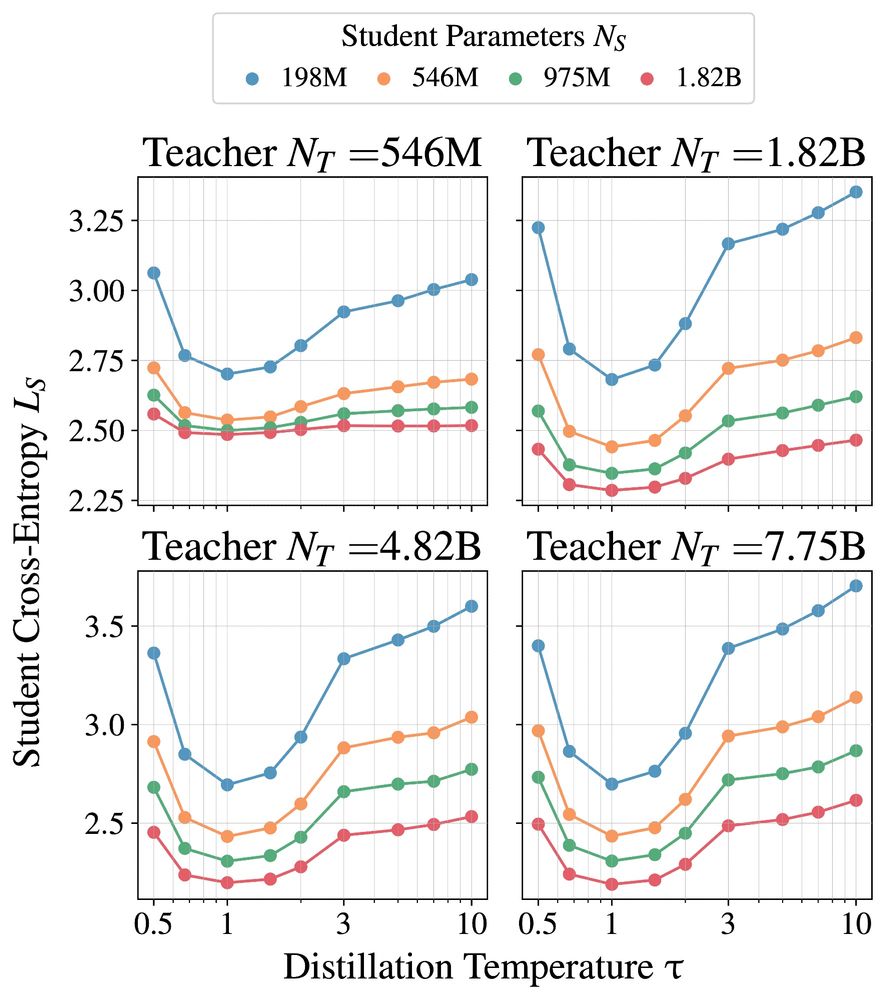
February 13, 2025 at 9:50 PM
We also investigated many other aspects of distillation that should be useful for the community.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
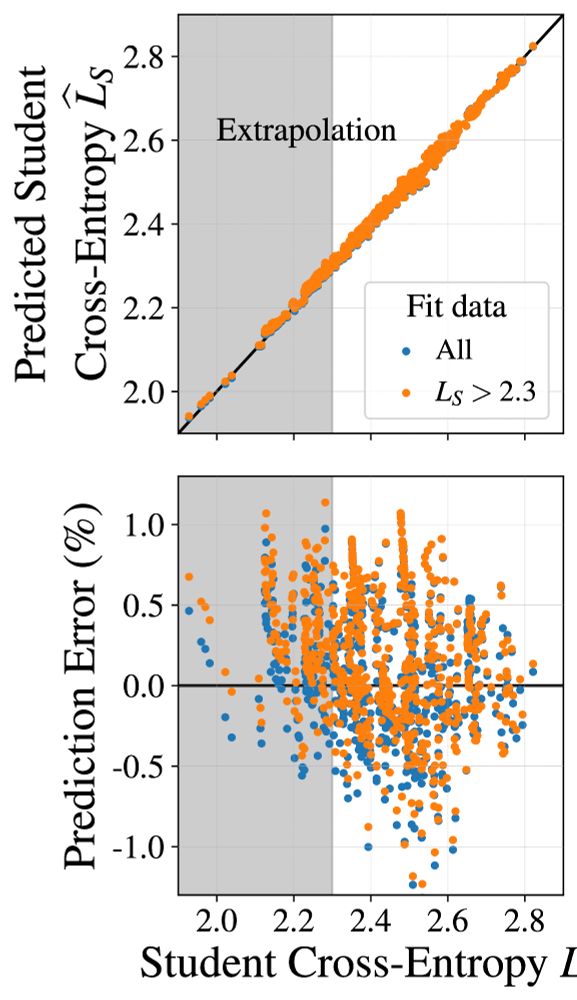
The distillation scaling law extrapolates with ~1% error in student cross-entropy prediction. We use our law in an extension Chinchilla, giving compute-optimal distillation for settings of interest to the community, and our conclusions about when distillation beneficial.
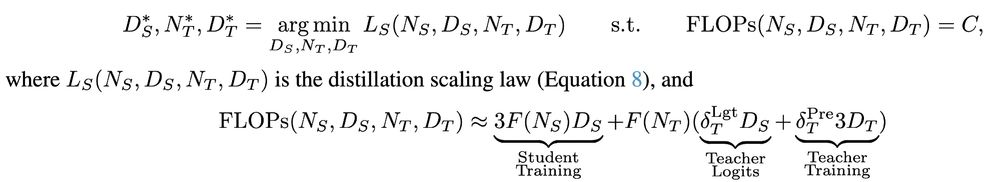
February 13, 2025 at 9:50 PM
The distillation scaling law extrapolates with ~1% error in student cross-entropy prediction. We use our law in an extension Chinchilla, giving compute-optimal distillation for settings of interest to the community, and our conclusions about when distillation beneficial.
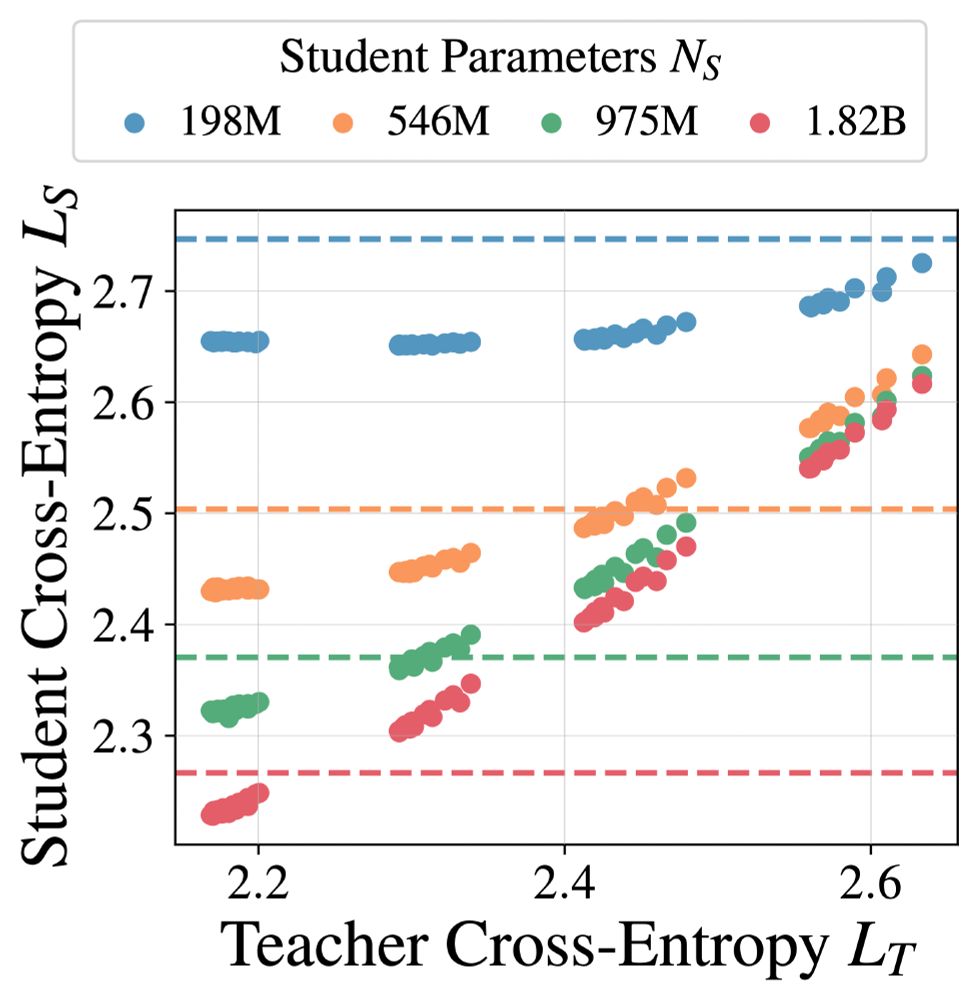
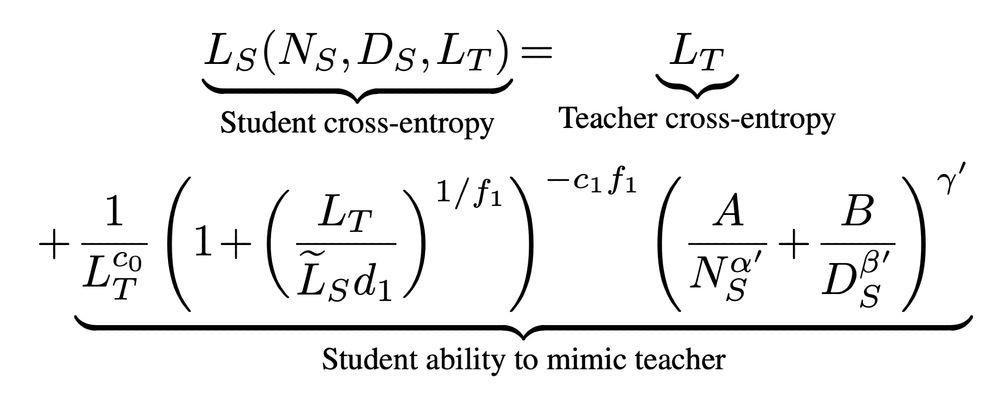
To arrive at our distillation scaling law, we noticed that teacher size influences student cross-entropy only through the teacher cross entropy, leading to a scaling law in student size, distillation tokens, and the teacher-cross entropy. Teacher size isn't directly important.
February 13, 2025 at 9:50 PM
To arrive at our distillation scaling law, we noticed that teacher size influences student cross-entropy only through the teacher cross entropy, leading to a scaling law in student size, distillation tokens, and the teacher-cross entropy. Teacher size isn't directly important.
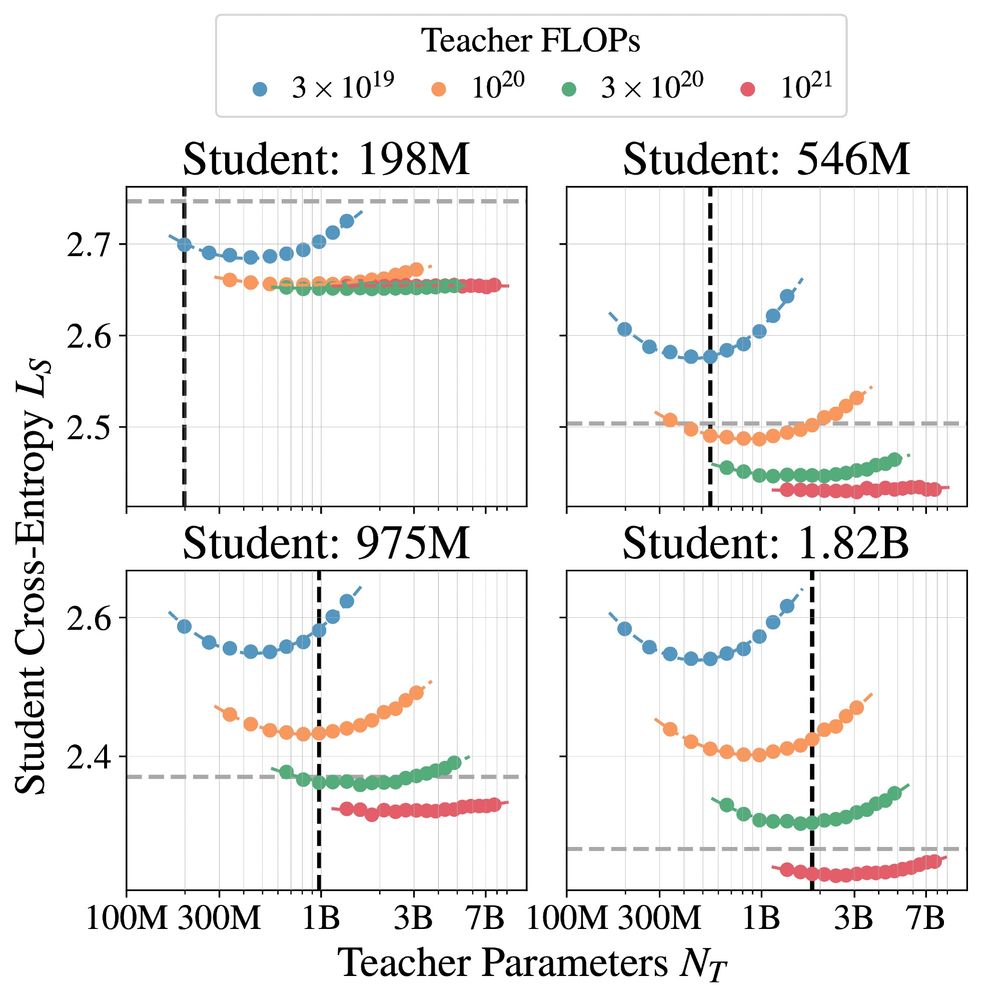
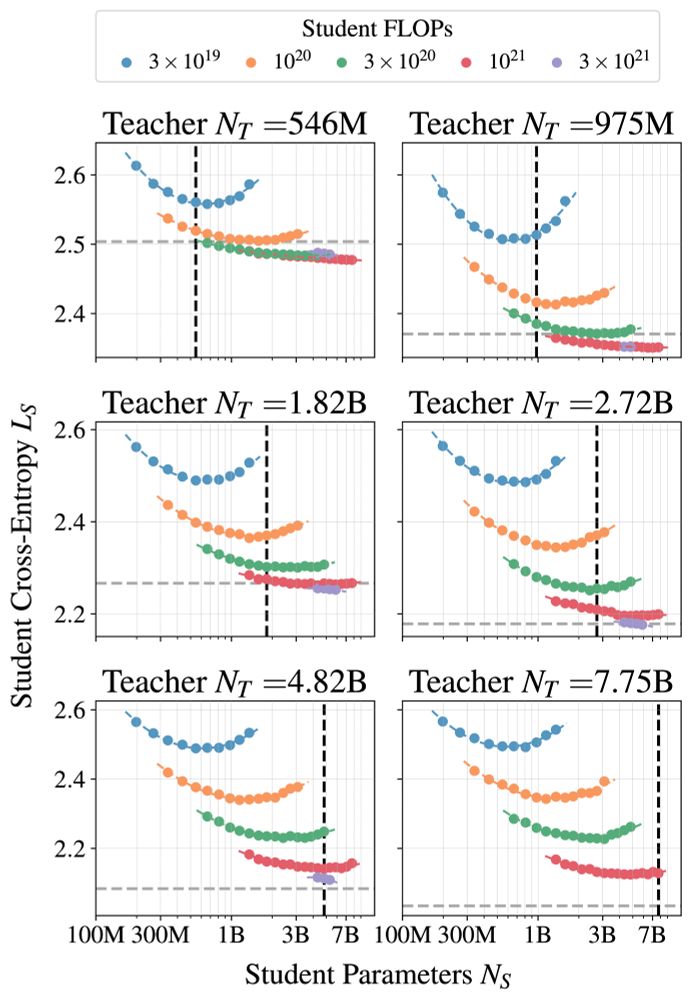
These results follow the largest study of distillation we are aware of, with 100s of student/teacher/data combinations, with model sizes ranging from 143M to 12.6B parameters and number distillation tokens ranging from 2B to 512B tokens.
February 13, 2025 at 9:50 PM
These results follow the largest study of distillation we are aware of, with 100s of student/teacher/data combinations, with model sizes ranging from 143M to 12.6B parameters and number distillation tokens ranging from 2B to 512B tokens.
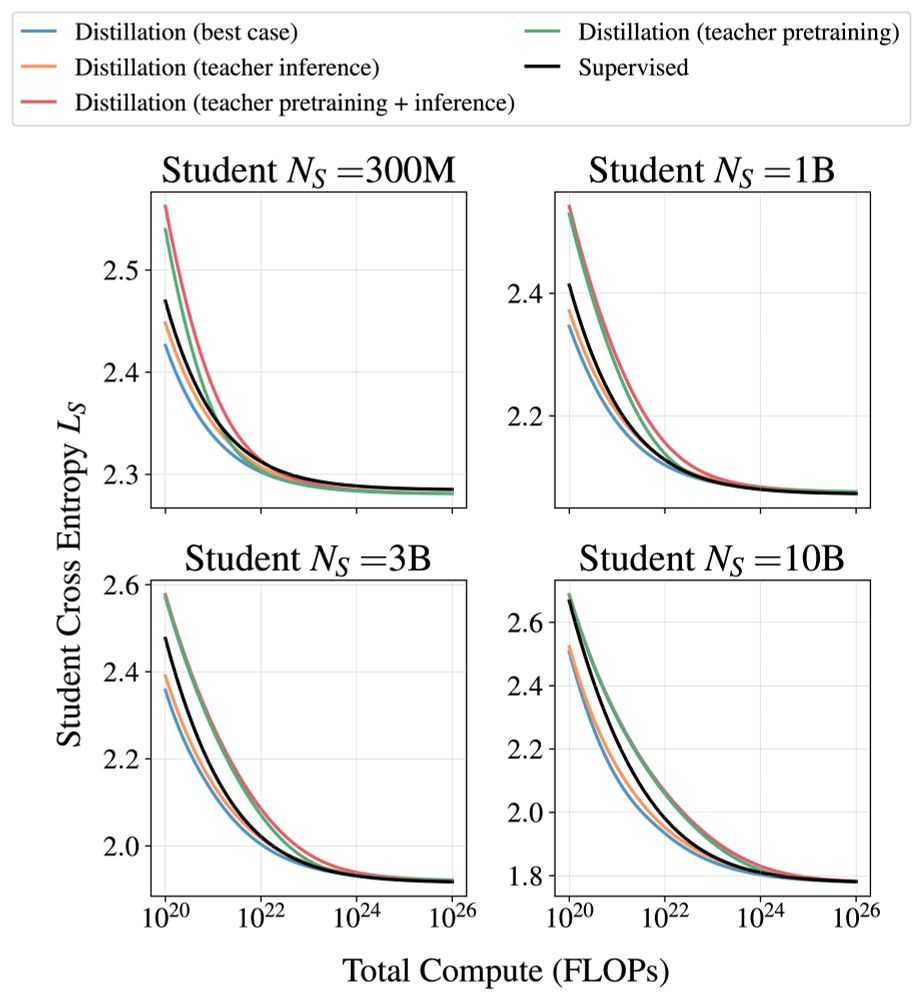
Compared to supervised training:
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
February 13, 2025 at 9:50 PM
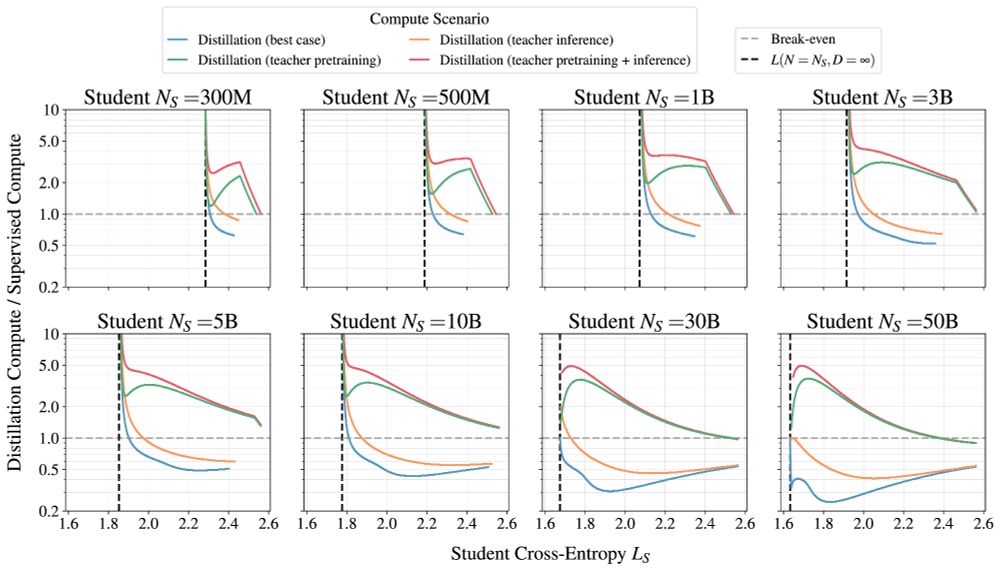
Compared to supervised training:
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.