



Dan Busbridge
@dbusbridge.bsky.social
Machine Learning Research @ Apple (opinions are my own)
We do observe that students improve with longer distillation training (i.e., patient teaching works). Additionally, with particularly long distillation durations, we approach what supervised learning can achieve (as limited by model capacity, in our experimental setting).
February 13, 2025 at 9:52 PM
We do observe that students improve with longer distillation training (i.e., patient teaching works). Additionally, with particularly long distillation durations, we approach what supervised learning can achieve (as limited by model capacity, in our experimental setting).
In contrast, our teachers and students are trained on the same data distribution, and we compare with supervised models that can access the same distribution. This lets us to make statements about what distillation can do given access to the same resources.
February 13, 2025 at 9:52 PM
In contrast, our teachers and students are trained on the same data distribution, and we compare with supervised models that can access the same distribution. This lets us to make statements about what distillation can do given access to the same resources.
I.e. Beyer et al's students do not see the teacher training distribution, and there is no supervised baseline where, for example, a model has access to both INet21k and the smaller datasets. This type of comparison was not the focus of their work.
February 13, 2025 at 9:52 PM
I.e. Beyer et al's students do not see the teacher training distribution, and there is no supervised baseline where, for example, a model has access to both INet21k and the smaller datasets. This type of comparison was not the focus of their work.
Beyer et al.'s teachers are trained on a large, diverse dataset (e.g., INet21k) then fine-tuned for the target datasets (e.g., Flowers102 or ImageNet1k). Students are distilled on the target datasets and only access the teacher's training distribution indirectly.
February 13, 2025 at 9:52 PM
Beyer et al.'s teachers are trained on a large, diverse dataset (e.g., INet21k) then fine-tuned for the target datasets (e.g., Flowers102 or ImageNet1k). Students are distilled on the target datasets and only access the teacher's training distribution indirectly.
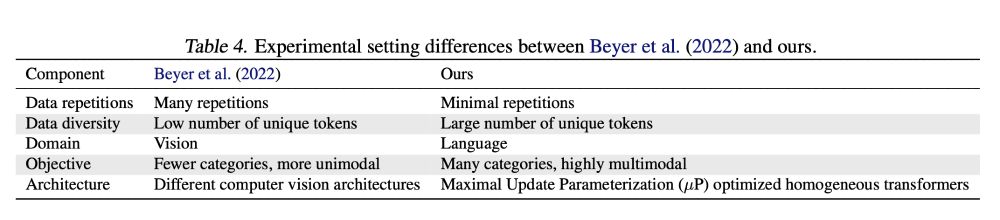
These differences, outlined in Table 4, relate primarily to the relationship between student and teacher.
February 13, 2025 at 9:52 PM
These differences, outlined in Table 4, relate primarily to the relationship between student and teacher.
As is often the case with distillation, the situation is nuanced, which is why we provide a dedicated discussion in Appendix D.1.
The key message is that despite an apparent contradiction, our findings are consistent because our baselines and experimental settings differ.
The key message is that despite an apparent contradiction, our findings are consistent because our baselines and experimental settings differ.
February 13, 2025 at 9:52 PM
As is often the case with distillation, the situation is nuanced, which is why we provide a dedicated discussion in Appendix D.1.
The key message is that despite an apparent contradiction, our findings are consistent because our baselines and experimental settings differ.
The key message is that despite an apparent contradiction, our findings are consistent because our baselines and experimental settings differ.
This investigation answered many long-standing questions I’ve had about distillation. I am deeply grateful for my amazing collaborators Amitis Shidani, Floris Weers, Jason Ramapuram, Etai Littwin, and Russ Webb, whose expertise and support brought this project to life.
February 13, 2025 at 9:50 PM
This investigation answered many long-standing questions I’ve had about distillation. I am deeply grateful for my amazing collaborators Amitis Shidani, Floris Weers, Jason Ramapuram, Etai Littwin, and Russ Webb, whose expertise and support brought this project to life.
So, distillation does work.
If you have access to a decent teacher, distillation is more efficient than supervised learning. Efficiency gains lessen with increasing compute.
If you need to train a teacher, it may not be worth it, depending on other uses for the teacher.
If you have access to a decent teacher, distillation is more efficient than supervised learning. Efficiency gains lessen with increasing compute.
If you need to train a teacher, it may not be worth it, depending on other uses for the teacher.
February 13, 2025 at 9:50 PM
So, distillation does work.
If you have access to a decent teacher, distillation is more efficient than supervised learning. Efficiency gains lessen with increasing compute.
If you need to train a teacher, it may not be worth it, depending on other uses for the teacher.
If you have access to a decent teacher, distillation is more efficient than supervised learning. Efficiency gains lessen with increasing compute.
If you need to train a teacher, it may not be worth it, depending on other uses for the teacher.
Many more results and discussions can be found in the paper.
arxiv.org/abs/2502.08606
arxiv.org/abs/2502.08606

Distillation Scaling Laws
We provide a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings reduce the risks associated ...
arxiv.org
February 13, 2025 at 9:50 PM
Many more results and discussions can be found in the paper.
arxiv.org/abs/2502.08606
arxiv.org/abs/2502.08606
5. Using fixed aspect ratio (width/depth) models, enables using N as non-embedding model parameters, and allows a simple, accurate expression for FLOPs/token which works for large contexts. I think this would be useful for the community to adopt generally.
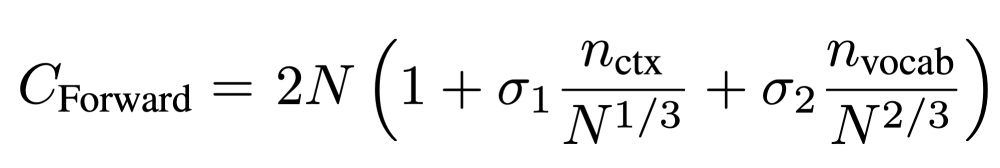
February 13, 2025 at 9:50 PM
5. Using fixed aspect ratio (width/depth) models, enables using N as non-embedding model parameters, and allows a simple, accurate expression for FLOPs/token which works for large contexts. I think this would be useful for the community to adopt generally.
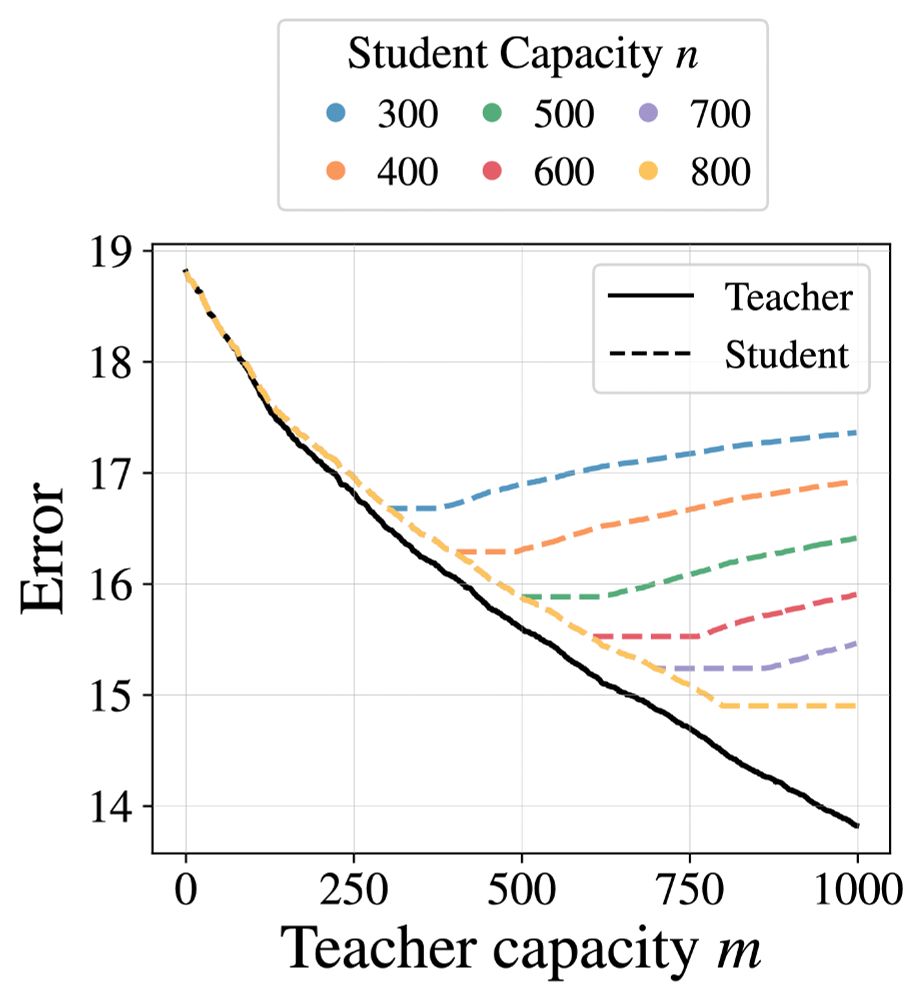
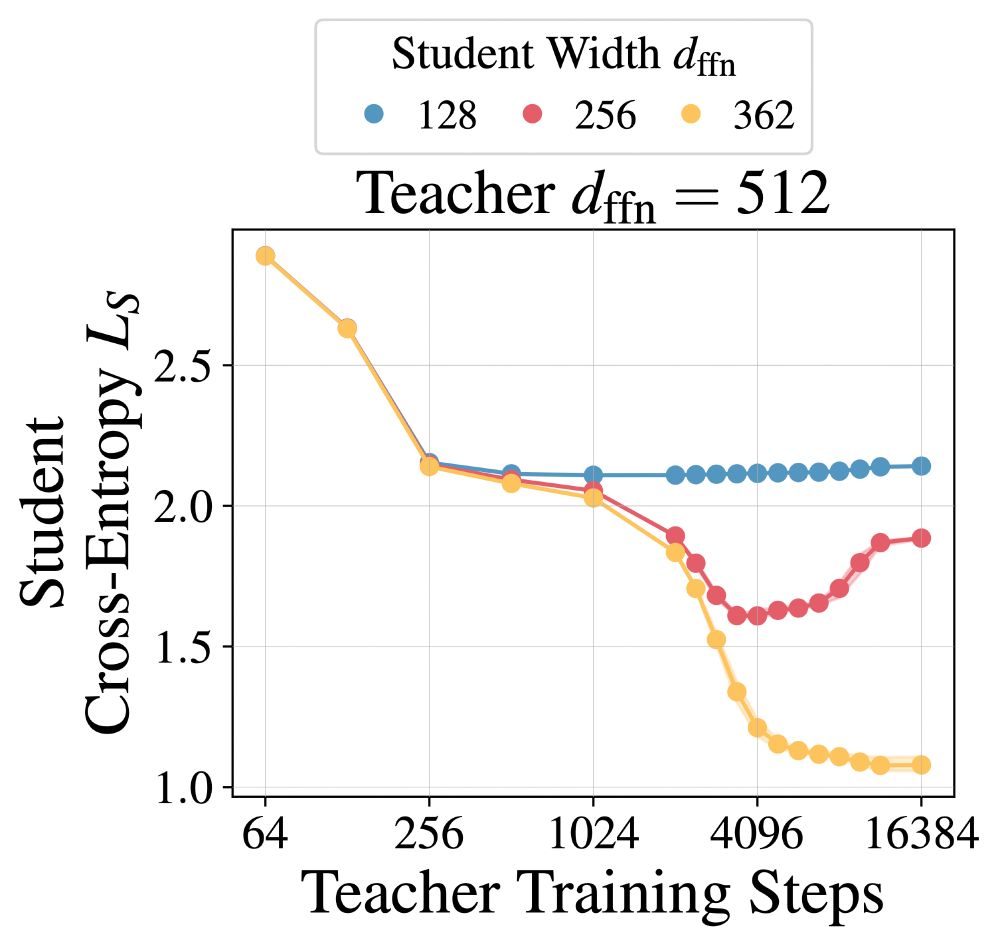
4. We present the first synthetic demonstrations of the distillation capacity gap phenomenon, using kernel regression (left) and pointer mapping problems (right). This will help us better understand why making a teacher too strong can harm student performance.
February 13, 2025 at 9:50 PM
4. We present the first synthetic demonstrations of the distillation capacity gap phenomenon, using kernel regression (left) and pointer mapping problems (right). This will help us better understand why making a teacher too strong can harm student performance.
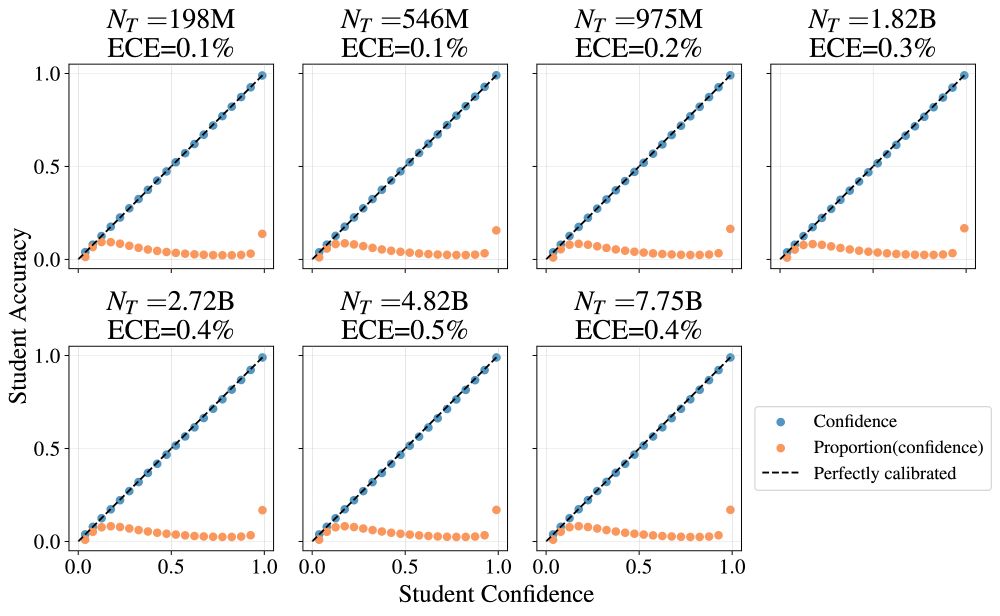
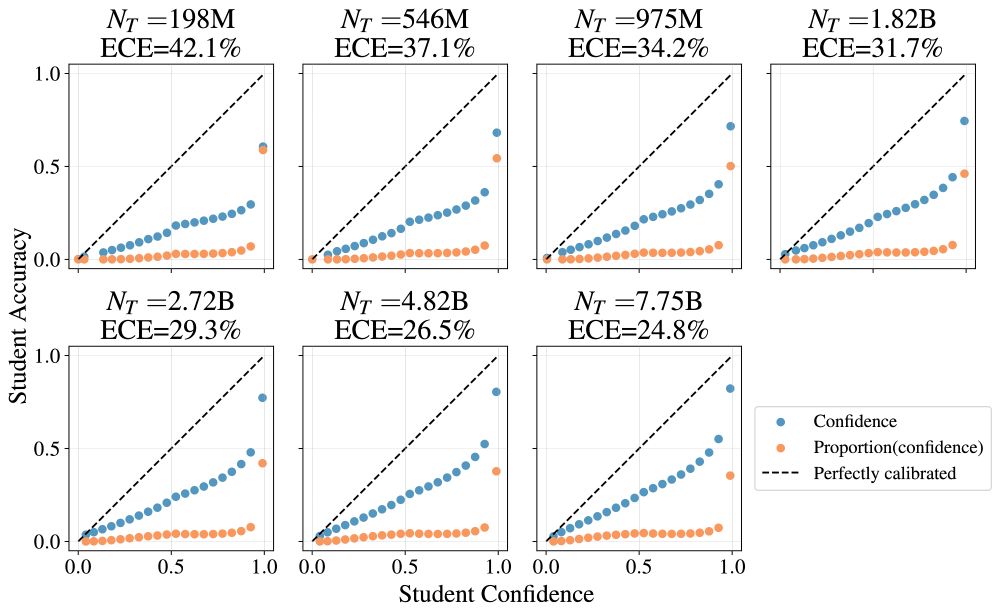
3. Training on the teacher logit signal produces a calibrated student (left) whereas training on the teacher top-1 does not (right). This can be understood using proper scoring metrics, but it is nice to observe clearly.
February 13, 2025 at 9:50 PM
3. Training on the teacher logit signal produces a calibrated student (left) whereas training on the teacher top-1 does not (right). This can be understood using proper scoring metrics, but it is nice to observe clearly.
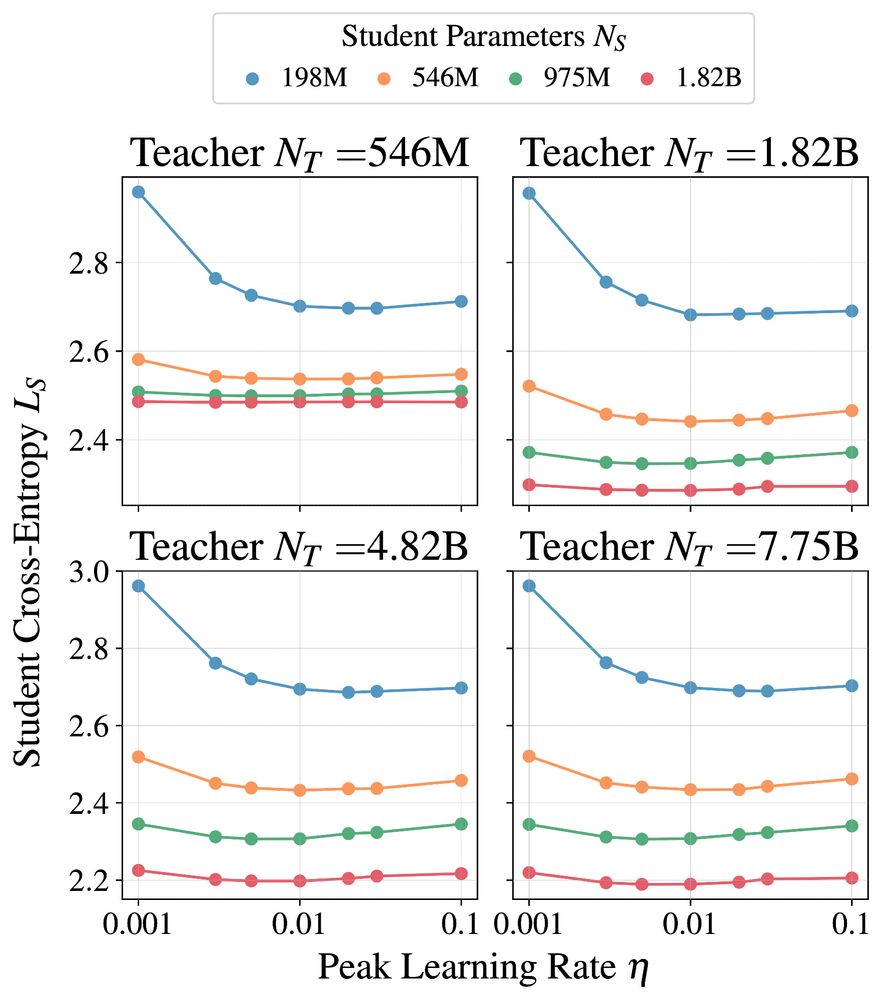
2. Maximum Update Parameterization (MuP, arxiv.org/abs/2011.14522) works out of the box for distillation. The distillation optimal learning rate is the same as the base learning rate for teacher training. This simplified our setup a lot.
February 13, 2025 at 9:50 PM
2. Maximum Update Parameterization (MuP, arxiv.org/abs/2011.14522) works out of the box for distillation. The distillation optimal learning rate is the same as the base learning rate for teacher training. This simplified our setup a lot.
We also investigated many other aspects of distillation that should be useful for the community.
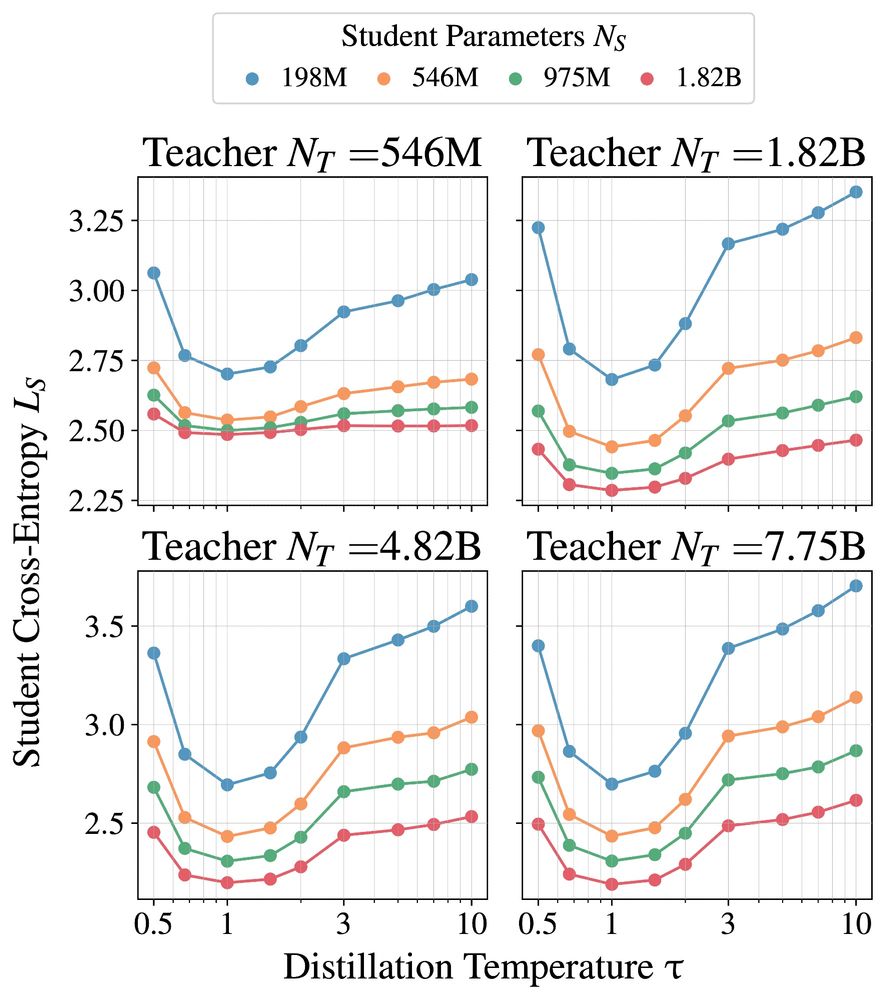
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
February 13, 2025 at 9:50 PM
We also investigated many other aspects of distillation that should be useful for the community.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
1. Language model distillation should use temperature = 1. Dark knowledge is less important, as the target distribution of natural language is already complex and multimodal.
When using an existing teacher, distillation overhead comes from generating student targets. Compute-optimal distillation shows It's better to choose a smaller teacher, slightly more capable than the target student capability, rather than a large, powerful teacher.
February 13, 2025 at 9:50 PM
When using an existing teacher, distillation overhead comes from generating student targets. Compute-optimal distillation shows It's better to choose a smaller teacher, slightly more capable than the target student capability, rather than a large, powerful teacher.
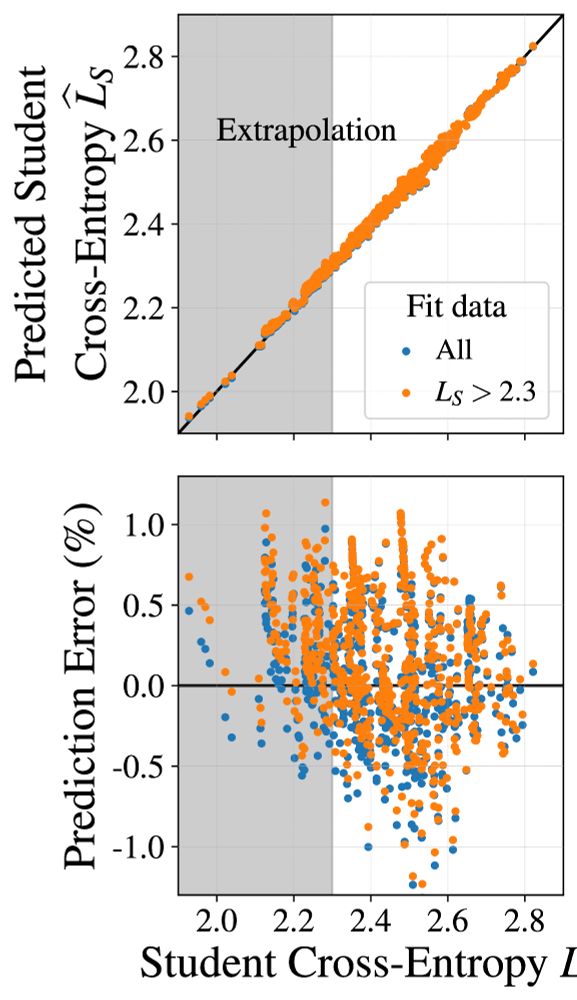
The distillation scaling law extrapolates with ~1% error in student cross-entropy prediction. We use our law in an extension Chinchilla, giving compute-optimal distillation for settings of interest to the community, and our conclusions about when distillation beneficial.
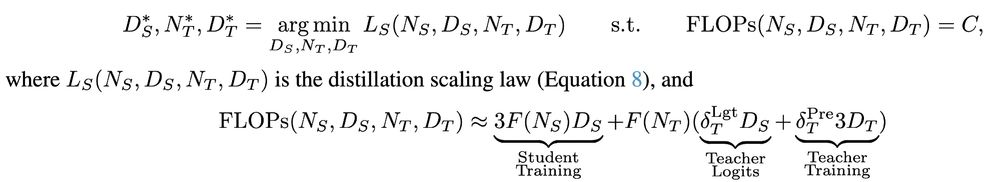
February 13, 2025 at 9:50 PM
The distillation scaling law extrapolates with ~1% error in student cross-entropy prediction. We use our law in an extension Chinchilla, giving compute-optimal distillation for settings of interest to the community, and our conclusions about when distillation beneficial.
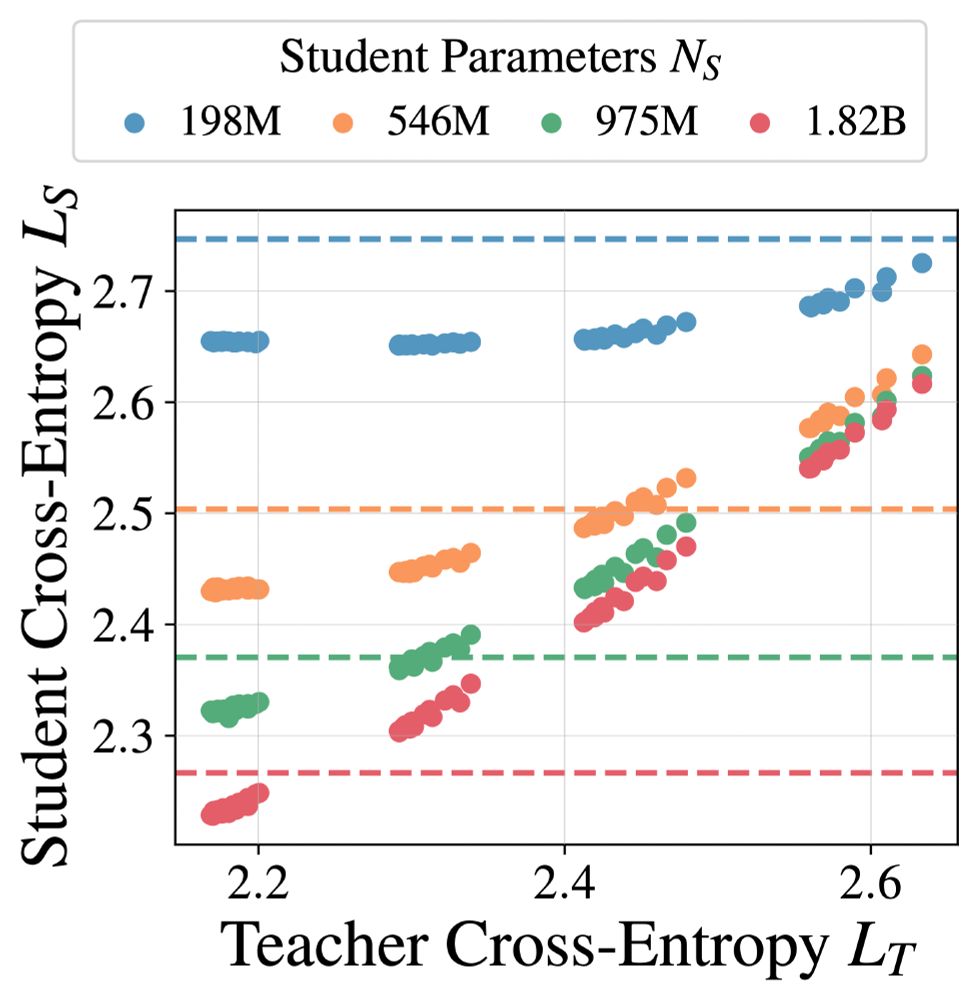
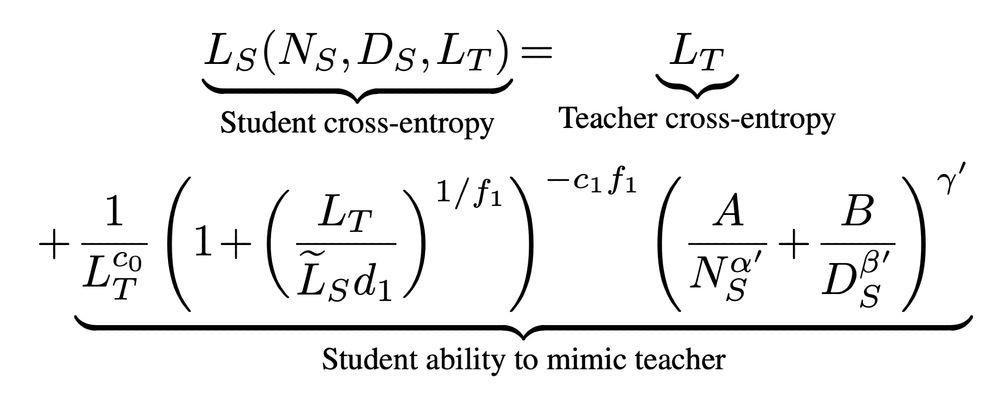
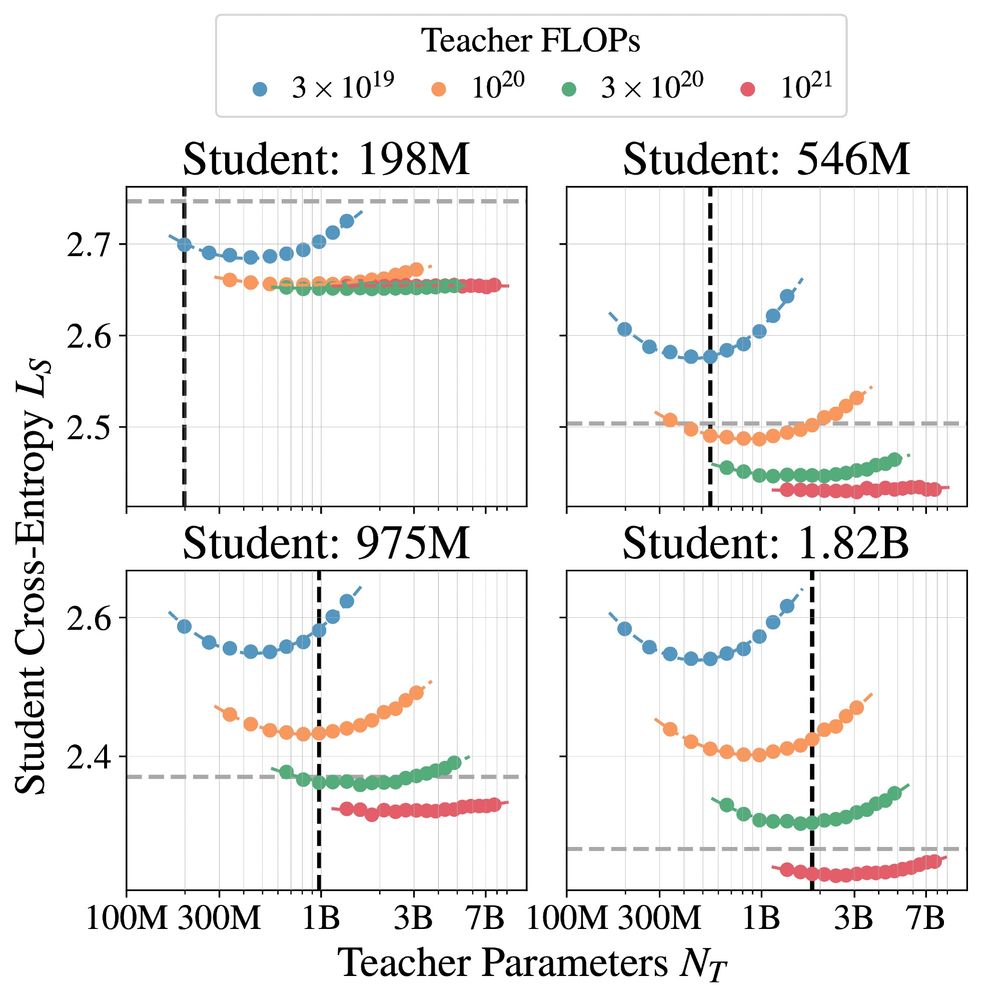
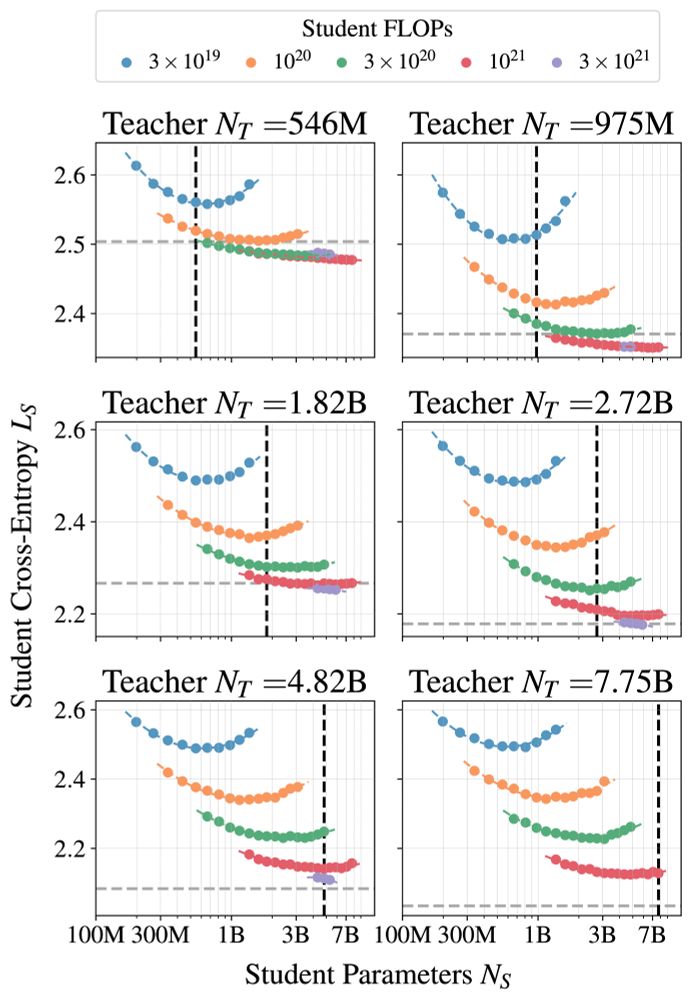
To arrive at our distillation scaling law, we noticed that teacher size influences student cross-entropy only through the teacher cross entropy, leading to a scaling law in student size, distillation tokens, and the teacher-cross entropy. Teacher size isn't directly important.
February 13, 2025 at 9:50 PM
To arrive at our distillation scaling law, we noticed that teacher size influences student cross-entropy only through the teacher cross entropy, leading to a scaling law in student size, distillation tokens, and the teacher-cross entropy. Teacher size isn't directly important.
These results follow the largest study of distillation we are aware of, with 100s of student/teacher/data combinations, with model sizes ranging from 143M to 12.6B parameters and number distillation tokens ranging from 2B to 512B tokens.
February 13, 2025 at 9:50 PM
These results follow the largest study of distillation we are aware of, with 100s of student/teacher/data combinations, with model sizes ranging from 143M to 12.6B parameters and number distillation tokens ranging from 2B to 512B tokens.
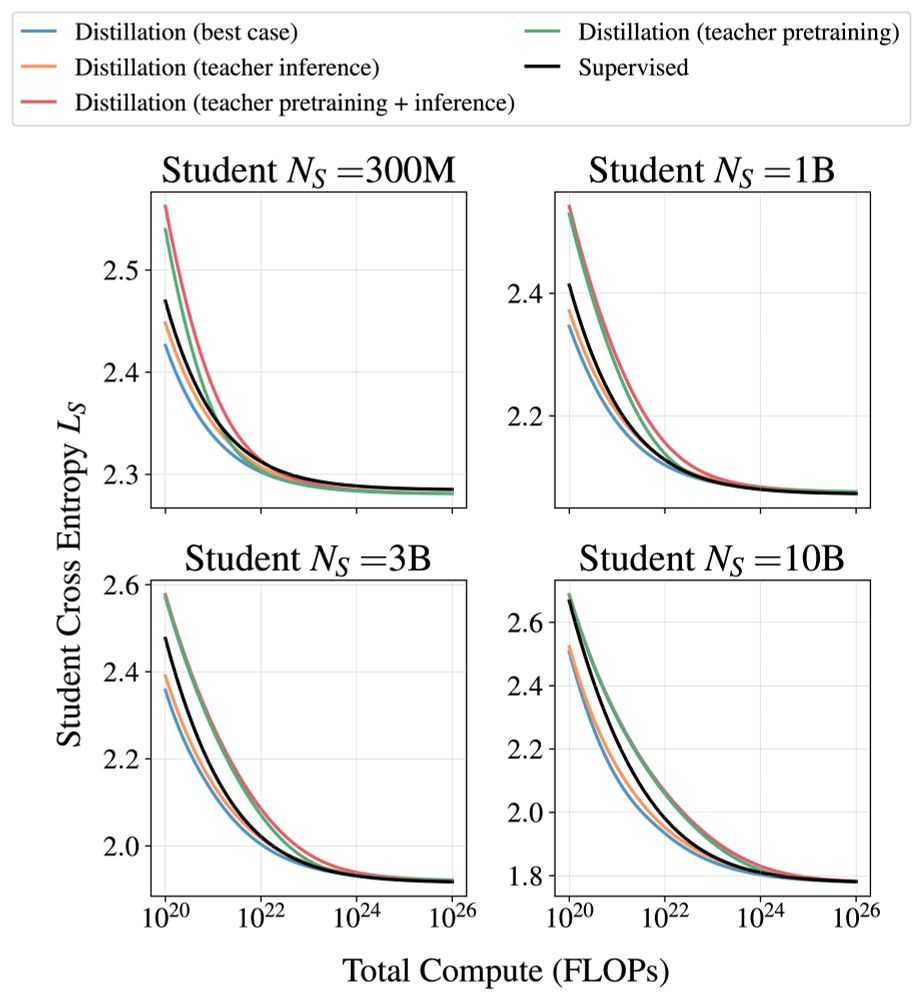
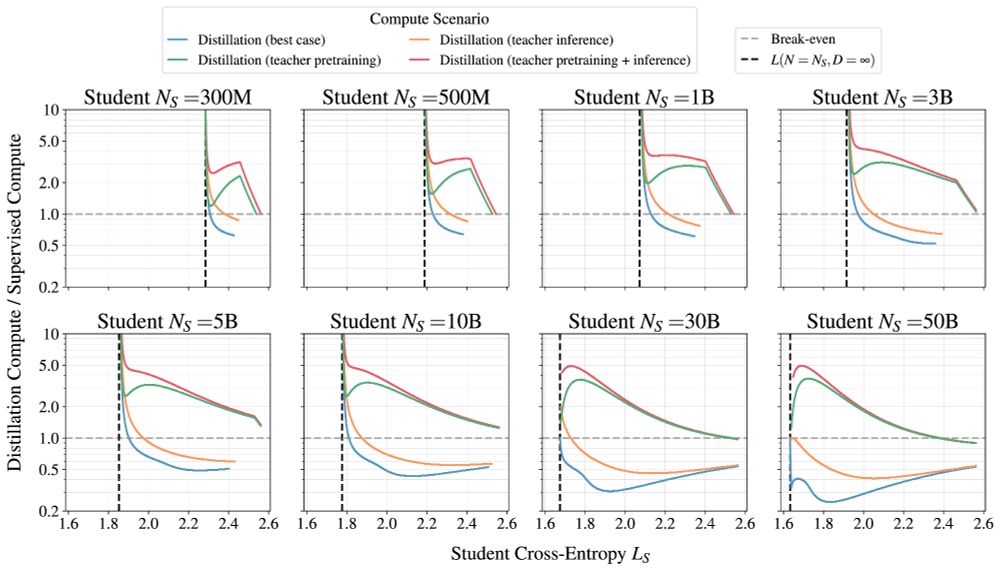
Compared to supervised training:
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
February 13, 2025 at 9:50 PM
Compared to supervised training:
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.
1. It is only more efficient to distill if the teacher training cost does not matter.
2. Efficiency benefits vanish when enough compute/data is available.
3. Distillation cannot produce lower cross-entropies when enough compute/data is available.