



Daniel Scalena
@danielsc4.it
PhDing @unimib 🇮🇹 & @gronlp.bsky.social 🇳🇱, interpretability et similia
danielsc4.it
danielsc4.it
Results: Across 3B-20B models, EAGer cuts budget by up to 80%, boosts perf 13% w/o labels & 37% w/ labels on AIME.
As M scales, EAGer consistently:
🚀 Achieves HIGHER Pass@k,
✂️ Uses FEWER tokens than baseline,
🕺 Shifts the Pareto frontier favorably across all tasks.
🧵5/
As M scales, EAGer consistently:
🚀 Achieves HIGHER Pass@k,
✂️ Uses FEWER tokens than baseline,
🕺 Shifts the Pareto frontier favorably across all tasks.
🧵5/

October 16, 2025 at 12:07 PM
Results: Across 3B-20B models, EAGer cuts budget by up to 80%, boosts perf 13% w/o labels & 37% w/ labels on AIME.
As M scales, EAGer consistently:
🚀 Achieves HIGHER Pass@k,
✂️ Uses FEWER tokens than baseline,
🕺 Shifts the Pareto frontier favorably across all tasks.
🧵5/
As M scales, EAGer consistently:
🚀 Achieves HIGHER Pass@k,
✂️ Uses FEWER tokens than baseline,
🕺 Shifts the Pareto frontier favorably across all tasks.
🧵5/
The fun part: EAGer-adapt reallocates saved budget to "saturating" prompts hitting the M cap, no labels needed! – Training & Verification-Free 🚀
Full EAGer uses labels to catch failing prompts, lowering threshold to branch or add sequences. Great for verifiable pipelines!
🧵4/
Full EAGer uses labels to catch failing prompts, lowering threshold to branch or add sequences. Great for verifiable pipelines!
🧵4/

October 16, 2025 at 12:07 PM
The fun part: EAGer-adapt reallocates saved budget to "saturating" prompts hitting the M cap, no labels needed! – Training & Verification-Free 🚀
Full EAGer uses labels to catch failing prompts, lowering threshold to branch or add sequences. Great for verifiable pipelines!
🧵4/
Full EAGer uses labels to catch failing prompts, lowering threshold to branch or add sequences. Great for verifiable pipelines!
🧵4/
EAGer works by monitoring token entropy during generation. High entropy token → It branches to explore new paths (reusing prefixes). Token with low entropy → It continues a single path.
We cap at M sequences/prompt, saving budget on easy ones without regen. Training-free!
🧵3/
We cap at M sequences/prompt, saving budget on easy ones without regen. Training-free!
🧵3/

October 16, 2025 at 12:07 PM
EAGer works by monitoring token entropy during generation. High entropy token → It branches to explore new paths (reusing prefixes). Token with low entropy → It continues a single path.
We cap at M sequences/prompt, saving budget on easy ones without regen. Training-free!
🧵3/
We cap at M sequences/prompt, saving budget on easy ones without regen. Training-free!
🧵3/
You can easily save up to 65% of compute while improving performance on reasoning tasks 🤯 👀
Meet EAGer: We show that monitoring token-level uncertainty lets LLMs allocate compute dynamically - spending MORE on hard problems, LESS on easy ones.
🧵👇
Meet EAGer: We show that monitoring token-level uncertainty lets LLMs allocate compute dynamically - spending MORE on hard problems, LESS on easy ones.
🧵👇

October 16, 2025 at 12:07 PM
You can easily save up to 65% of compute while improving performance on reasoning tasks 🤯 👀
Meet EAGer: We show that monitoring token-level uncertainty lets LLMs allocate compute dynamically - spending MORE on hard problems, LESS on easy ones.
🧵👇
Meet EAGer: We show that monitoring token-level uncertainty lets LLMs allocate compute dynamically - spending MORE on hard problems, LESS on easy ones.
🧵👇
🌍 Across 7 languages, our SAE-based method matches or outperforms traditional prompting methods! Our method obtains better human-like translations (H) personalization accuracy (P), and maintains translation quality (Comet ☄️ @nunonmg.bsky.social) especially for smaller LLMs. 5/

May 23, 2025 at 12:23 PM
🌍 Across 7 languages, our SAE-based method matches or outperforms traditional prompting methods! Our method obtains better human-like translations (H) personalization accuracy (P), and maintains translation quality (Comet ☄️ @nunonmg.bsky.social) especially for smaller LLMs. 5/
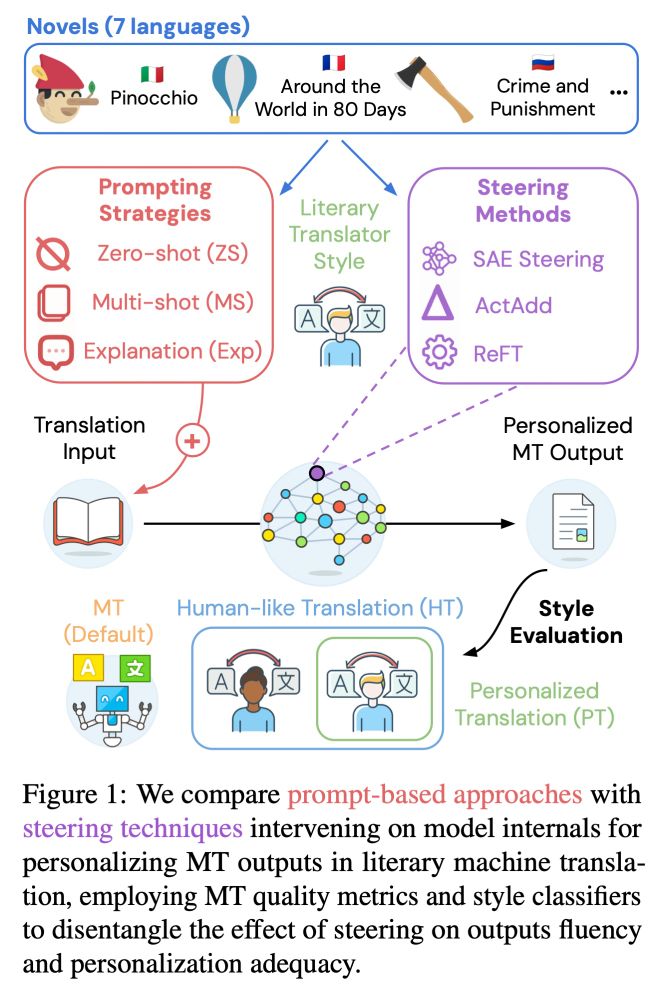
💡 We compare prompting (zero and multi-shot + explanations) and inference-time interventions (ActAdd, REFT and SAEs).
Following SpARE (@yuzhaouoe.bsky.social @alessiodevoto.bsky.social), we propose ✨ contrastive SAE steering ✨ with mutual info to personalize literary MT by tuning latent features 4/
Following SpARE (@yuzhaouoe.bsky.social @alessiodevoto.bsky.social), we propose ✨ contrastive SAE steering ✨ with mutual info to personalize literary MT by tuning latent features 4/
May 23, 2025 at 12:23 PM
💡 We compare prompting (zero and multi-shot + explanations) and inference-time interventions (ActAdd, REFT and SAEs).
Following SpARE (@yuzhaouoe.bsky.social @alessiodevoto.bsky.social), we propose ✨ contrastive SAE steering ✨ with mutual info to personalize literary MT by tuning latent features 4/
Following SpARE (@yuzhaouoe.bsky.social @alessiodevoto.bsky.social), we propose ✨ contrastive SAE steering ✨ with mutual info to personalize literary MT by tuning latent features 4/
📈 But can models recognize and replicate individual translator styles?:
✓ Classifiers can find styles with high acc. (humans kinda don’t)
✓ Multi-shot prompting boosts style a lot
✓ We can detect strong style traces in activations (esp. mid layers) 3/
✓ Classifiers can find styles with high acc. (humans kinda don’t)
✓ Multi-shot prompting boosts style a lot
✓ We can detect strong style traces in activations (esp. mid layers) 3/

May 23, 2025 at 12:23 PM
📈 But can models recognize and replicate individual translator styles?:
✓ Classifiers can find styles with high acc. (humans kinda don’t)
✓ Multi-shot prompting boosts style a lot
✓ We can detect strong style traces in activations (esp. mid layers) 3/
✓ Classifiers can find styles with high acc. (humans kinda don’t)
✓ Multi-shot prompting boosts style a lot
✓ We can detect strong style traces in activations (esp. mid layers) 3/
📢 New paper: Applied interpretability 🤝 MT personalization!
We steer LLM generations to mimic human translator styles on literary novels in 7 languages. 📚
SAE steering can beat few-shot prompting, leading to better personalization while maintaining quality.
🧵1/
We steer LLM generations to mimic human translator styles on literary novels in 7 languages. 📚
SAE steering can beat few-shot prompting, leading to better personalization while maintaining quality.
🧵1/

May 23, 2025 at 12:23 PM
📢 New paper: Applied interpretability 🤝 MT personalization!
We steer LLM generations to mimic human translator styles on literary novels in 7 languages. 📚
SAE steering can beat few-shot prompting, leading to better personalization while maintaining quality.
🧵1/
We steer LLM generations to mimic human translator styles on literary novels in 7 languages. 📚
SAE steering can beat few-shot prompting, leading to better personalization while maintaining quality.
🧵1/