



Daan van Esch
@daanvanesch.nl
I work on speech and language technologies at Google. I like languages, history, maps, traveling, cycling, and buying way too many books.
Reposted by Daan van Esch

VarDial 2026 will be colocated with @eaclmeeting.bsky.social! We're looking forward to your papers on NLP for similar languages, varieties and dialects :)
Deadline: Dec 19 (Jan 2 for pre-reviewed ARR papers)
sites.google.com/view/vardial...
Deadline: Dec 19 (Jan 2 for pre-reviewed ARR papers)
sites.google.com/view/vardial...

October 21, 2025 at 10:36 AM
VarDial 2026 will be colocated with @eaclmeeting.bsky.social! We're looking forward to your papers on NLP for similar languages, varieties and dialects :)
Deadline: Dec 19 (Jan 2 for pre-reviewed ARR papers)
sites.google.com/view/vardial...
Deadline: Dec 19 (Jan 2 for pre-reviewed ARR papers)
sites.google.com/view/vardial...
Reposted by Daan van Esch

The ConlangCrafter pipeline harnesses an LLM to generate a description of a constructed language and self refines it in the process. We decompose language creation into phonology, grammar, and lexicon, and then translate sentences while constructing new needed grammar points.

October 11, 2025 at 5:35 AM
The ConlangCrafter pipeline harnesses an LLM to generate a description of a constructed language and self refines it in the process. We decompose language creation into phonology, grammar, and lexicon, and then translate sentences while constructing new needed grammar points.
Great to see this highly multilingual model: 1,000+ languages!

EPFL, ETH Zurich & CSCS just released Apertus, Switzerland’s first fully open-source large language model.
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...

September 3, 2025 at 6:17 AM
Great to see this highly multilingual model: 1,000+ languages!
Reposted by Daan van Esch

AI efficiency is important. The median Gemini Apps text prompt in May 2025 used 0.24 Wh of energy (<9 seconds of TV watching) & 0.26 mL (~5 drops) of water. Over 12 months, we reduced the energy footprint of a median text prompt 33x, while improving quality:
cloud.google.com/blog/product...
cloud.google.com/blog/product...


August 21, 2025 at 1:39 PM
AI efficiency is important. The median Gemini Apps text prompt in May 2025 used 0.24 Wh of energy (<9 seconds of TV watching) & 0.26 mL (~5 drops) of water. Over 12 months, we reduced the energy footprint of a median text prompt 33x, while improving quality:
cloud.google.com/blog/product...
cloud.google.com/blog/product...
Reposted by Daan van Esch

⏳ Just 1 week to go! 🎉
#Interspeech2025 kicks off next week in Rotterdam, the Netherlands 🗣️🌍
We can’t wait to welcome everyone for a week full of talks, posters, workshops & networking.
📅 See you soon!
Comment below, are you joining? 🥰
#Interspeech2025 kicks off next week in Rotterdam, the Netherlands 🗣️🌍
We can’t wait to welcome everyone for a week full of talks, posters, workshops & networking.
📅 See you soon!
Comment below, are you joining? 🥰

August 10, 2025 at 11:14 AM
⏳ Just 1 week to go! 🎉
#Interspeech2025 kicks off next week in Rotterdam, the Netherlands 🗣️🌍
We can’t wait to welcome everyone for a week full of talks, posters, workshops & networking.
📅 See you soon!
Comment below, are you joining? 🥰
#Interspeech2025 kicks off next week in Rotterdam, the Netherlands 🗣️🌍
We can’t wait to welcome everyone for a week full of talks, posters, workshops & networking.
📅 See you soon!
Comment below, are you joining? 🥰
Reposted by Daan van Esch

🥳 Happy to open up the registrations for the CLIN conference! You can find more information here: clin35.ccl.kuleuven.be/registration The website has also been updated with more information for the presenters, with a programme, and with information about the venue. See you soon at #CLIN35!
August 8, 2025 at 1:14 PM
🥳 Happy to open up the registrations for the CLIN conference! You can find more information here: clin35.ccl.kuleuven.be/registration The website has also been updated with more information for the presenters, with a programme, and with information about the venue. See you soon at #CLIN35!
Reposted by Daan van Esch

Hi #NLP community, I'm urgently looking for an emergency reviewer for the ARR Linguistic Theories track. The paper investigates and measures orthography across many languages. Please shoot me a quick email if you can review!
June 21, 2025 at 10:34 AM
Hi #NLP community, I'm urgently looking for an emergency reviewer for the ARR Linguistic Theories track. The paper investigates and measures orthography across many languages. Please shoot me a quick email if you can review!
Reposted by Daan van Esch

The @interspeech.bsky.social early registration deadline is coming up in a few days!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!

Interpretability Techniques for Speech Models — Tutorial @ Interspeech 2025
interpretingdl.github.io
June 13, 2025 at 5:18 AM
The @interspeech.bsky.social early registration deadline is coming up in a few days!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Want to learn how to analyze the inner workings of speech processing models? 🔍 Check out the programme for our tutorial:
interpretingdl.github.io/speech-inter... & sign up through the conference registration form!
Reposted by Daan van Esch


Reposted by Daan van Esch

Now that @interspeech.bsky.social registration is open, time for some shameless promo!
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
https://www.interspeech2025.org/tutorials
Your cookies are disabled, please enable them.
www.interspeech2025.org
May 27, 2025 at 4:14 PM
Now that @interspeech.bsky.social registration is open, time for some shameless promo!
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
Reposted by Daan van Esch

And you can now register as well!
Don't hesitate, but sign up for @interspeech.bsky.social Interspeech 2025 now through www.interspeech2025.org/registration and be part of the largest speech science and technology conference in the world!
Don't hesitate, but sign up for @interspeech.bsky.social Interspeech 2025 now through www.interspeech2025.org/registration and be part of the largest speech science and technology conference in the world!
May 23, 2025 at 2:09 PM
And you can now register as well!
Don't hesitate, but sign up for @interspeech.bsky.social Interspeech 2025 now through www.interspeech2025.org/registration and be part of the largest speech science and technology conference in the world!
Don't hesitate, but sign up for @interspeech.bsky.social Interspeech 2025 now through www.interspeech2025.org/registration and be part of the largest speech science and technology conference in the world!
Reposted by Daan van Esch

Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
Stellen OBP - Georg-August-Universität Göttingen
Webseiten der Georg-August-Universität Göttingen
www.uni-goettingen.de
May 16, 2025 at 8:23 AM
Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
Reposted by Daan van Esch
Want to check out the source for the "AlexNet" paper? Google has made the code from Krizhevsky, Sutskever and Hinton's seminal "ImageNet Classification with Deep Convolutional
Neural Networks" paper open source, in partnership with the Computer History Museum.
computerhistory.org/press-releas...
Neural Networks" paper open source, in partnership with the Computer History Museum.
computerhistory.org/press-releas...

March 20, 2025 at 9:02 PM
Want to check out the source for the "AlexNet" paper? Google has made the code from Krizhevsky, Sutskever and Hinton's seminal "ImageNet Classification with Deep Convolutional
Neural Networks" paper open source, in partnership with the Computer History Museum.
computerhistory.org/press-releas...
Neural Networks" paper open source, in partnership with the Computer History Museum.
computerhistory.org/press-releas...
Reposted by Daan van Esch


March 17, 2025 at 3:15 AM
Reposted by Daan van Esch
Introducing our Gemma 3 open models, the most capable models that you can run on a single GPU or TPU. Multimodal, multilingual, 128k context length, and exceeds quality of other open models that are an order of magnitude larger in terms of hardware footprint. 🎉
blog.google/technology/d...
blog.google/technology/d...

Introducing Gemma 3: The most capable model you can run on a single GPU or TPU
Today, we're introducing Gemma 3, our most capable, portable and responsible open model yet.
blog.google
March 13, 2025 at 2:55 PM
Introducing our Gemma 3 open models, the most capable models that you can run on a single GPU or TPU. Multimodal, multilingual, 128k context length, and exceeds quality of other open models that are an order of magnitude larger in terms of hardware footprint. 🎉
blog.google/technology/d...
blog.google/technology/d...
Reposted by Daan van Esch

Tris, product lead for Gemma, on stage in Paris to introduce Gemma 3.
140 languages , Multi-modal, Best single GPU model
140 languages , Multi-modal, Best single GPU model

March 12, 2025 at 9:46 AM
Tris, product lead for Gemma, on stage in Paris to introduce Gemma 3.
140 languages , Multi-modal, Best single GPU model
140 languages , Multi-modal, Best single GPU model
Reposted by Daan van Esch
Introducing Gemma 3. The most capable model you can run on a single GPU. Cloud Run offers 1 GPU per instance, it is a perfect fit. Deploy it in one simple command.
Blog: cloud.google.com/blog/product...
Tutorial: cloud.google.com/run/docs/tut...
Blog: cloud.google.com/blog/product...
Tutorial: cloud.google.com/run/docs/tut...

March 12, 2025 at 7:49 AM
Introducing Gemma 3. The most capable model you can run on a single GPU. Cloud Run offers 1 GPU per instance, it is a perfect fit. Deploy it in one simple command.
Blog: cloud.google.com/blog/product...
Tutorial: cloud.google.com/run/docs/tut...
Blog: cloud.google.com/blog/product...
Tutorial: cloud.google.com/run/docs/tut...
Reposted by Daan van Esch

OK, every year I try to explain to my students how LLMs work, and every year I have to do a big trawl for good resources and activities. Here's this year's haul of *introductory* materials. (In-class activities + visualizations, not so much readings.)
March 6, 2025 at 6:42 PM
OK, every year I try to explain to my students how LLMs work, and every year I have to do a big trawl for good resources and activities. Here's this year's haul of *introductory* materials. (In-class activities + visualizations, not so much readings.)
Reposted by Daan van Esch

NEW: Gaelic language broadcasting will receive a £1.8 million funding boost to build on the success of BBC Alba’s crime thriller An t-Eilean

Kate Forbes announces £1.8m for Gaelic broadcasting after success of crime thriller
www.thenational.scot
February 28, 2025 at 8:15 AM
NEW: Gaelic language broadcasting will receive a £1.8 million funding boost to build on the success of BBC Alba’s crime thriller An t-Eilean
Reposted by Daan van Esch
🌍🎙️ Call for Participation – Multilingual Speech AI Challenge! 🤖🔊
Join our #Interspeech2025 workshop on Multilingual Conversational Speech Language Models! 🏆
💡 Tasks:
📌 Multilingual ASR 📝
📌 Speaker diarization + recognition 🎙️
🚀 Push the boundaries of speech AI!
🔗 www.nexdata.ai/competition
Join our #Interspeech2025 workshop on Multilingual Conversational Speech Language Models! 🏆
💡 Tasks:
📌 Multilingual ASR 📝
📌 Speaker diarization + recognition 🎙️
🚀 Push the boundaries of speech AI!
🔗 www.nexdata.ai/competition

February 28, 2025 at 4:12 PM
🌍🎙️ Call for Participation – Multilingual Speech AI Challenge! 🤖🔊
Join our #Interspeech2025 workshop on Multilingual Conversational Speech Language Models! 🏆
💡 Tasks:
📌 Multilingual ASR 📝
📌 Speaker diarization + recognition 🎙️
🚀 Push the boundaries of speech AI!
🔗 www.nexdata.ai/competition
Join our #Interspeech2025 workshop on Multilingual Conversational Speech Language Models! 🏆
💡 Tasks:
📌 Multilingual ASR 📝
📌 Speaker diarization + recognition 🎙️
🚀 Push the boundaries of speech AI!
🔗 www.nexdata.ai/competition
Reposted by Daan van Esch

Guess what? The jubilee 🎉 20th iteration of WMT General MT 🎉 is here, and we want you to participate - as the entry barrier to make an impact is so low!
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
February 20, 2025 at 9:31 PM
Guess what? The jubilee 🎉 20th iteration of WMT General MT 🎉 is here, and we want you to participate - as the entry barrier to make an impact is so low!
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
Reposted by Daan van Esch

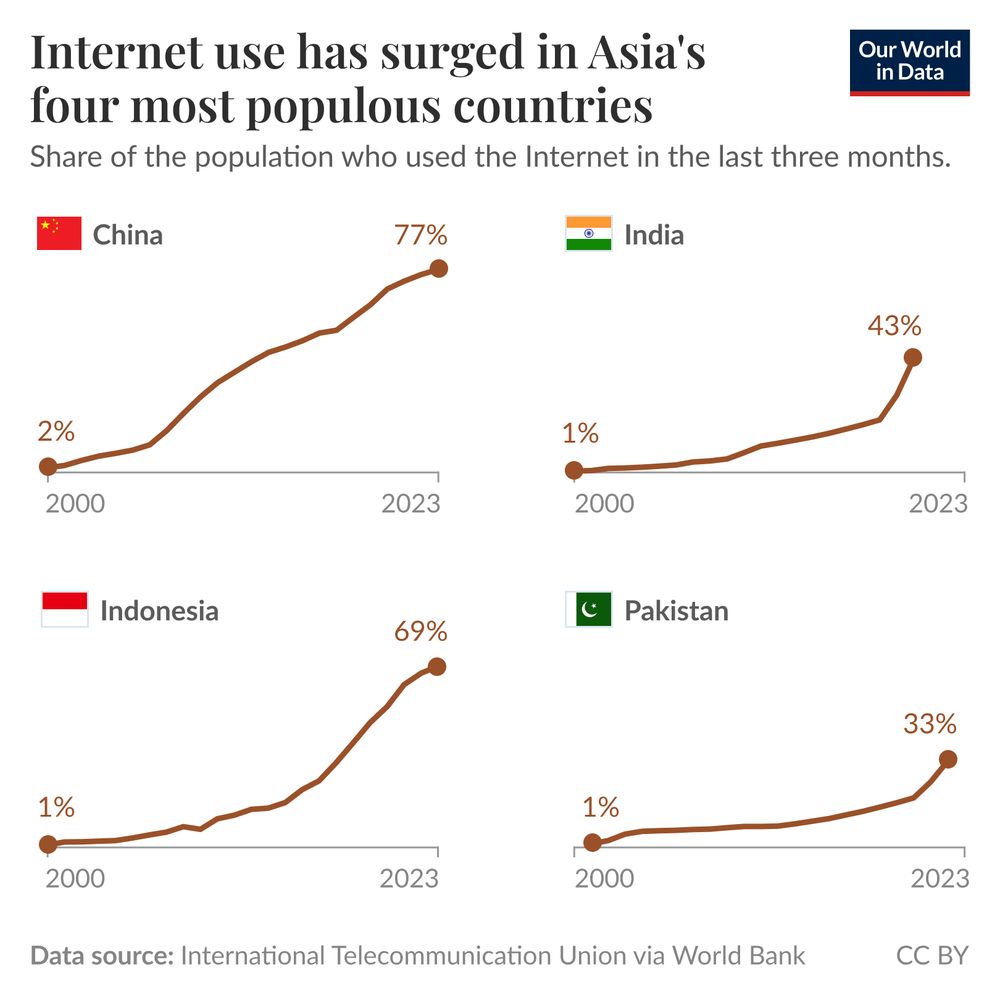
Internet use has grown rapidly but unevenly across Asia's largest countries
February 20, 2025 at 7:39 PM
Internet use has grown rapidly but unevenly across Asia's largest countries
Reposted by Daan van Esch

Interested in studying ancient, extinct and endangered languages from Akkadian and Aramaic to Xhosa and Zulu on the beautiful island of San Servolo in Venice this summer? Check out the fantatstic programme by the Université d’été en Langues de l’Orient of UNIL here: www.unil.ch/unil/fr/home...
Langues de l’Orient - UNIL
Cours de français durant les vacances, Summer et Winter schools pour vous mettre à niveau, acquérir des compétences transversales, multidisciplinaires et monter en compétence sur des sujets de fond.
www.unil.ch
February 19, 2025 at 2:38 PM
Interested in studying ancient, extinct and endangered languages from Akkadian and Aramaic to Xhosa and Zulu on the beautiful island of San Servolo in Venice this summer? Check out the fantatstic programme by the Université d’été en Langues de l’Orient of UNIL here: www.unil.ch/unil/fr/home...
Reposted by Daan van Esch

😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goo...
Huggingface: huggingface.co/datasets/goo...

February 19, 2025 at 5:36 PM
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goo...
Huggingface: huggingface.co/datasets/goo...
Reposted by Daan van Esch

PaliGemma 2 mix is out! This model can now handles short/long captioning, OCR, image Q&A, object detection, and segmentation. Available in 3B, 10B, and 28B parameter sizes and 224px/448px resolutions. Frameworks: Hugging Face Transformers, Keras, PyTorch, JAX, and Gemma.cpp.
goo.gle/4i1jOOU
goo.gle/4i1jOOU

Introducing PaliGemma 2 mix: A vision-language model for multiple tasks- Google Developers Blog
PaliGemma 2 mix, Google’s new vision-language model, solves tasks like image captioning, OCR, object detection, and segmentation.
goo.gle
February 19, 2025 at 5:51 PM
PaliGemma 2 mix is out! This model can now handles short/long captioning, OCR, image Q&A, object detection, and segmentation. Available in 3B, 10B, and 28B parameter sizes and 224px/448px resolutions. Frameworks: Hugging Face Transformers, Keras, PyTorch, JAX, and Gemma.cpp.
goo.gle/4i1jOOU
goo.gle/4i1jOOU