


Craig Schmidt
@craigschmidt.com
Interested in ML, AI, and NLP. Particularly interested in tokenization. Live in the Boston area and work in R&D at Kensho Technologies.
I believe he’s talking about Olin College of Engineering. Created from scratch as an undergraduate only school, with the first class in 2002. Kind of a Harvey Mudd of the east. Campus is near me, and they seem to attract great students.
October 2, 2025 at 9:34 PM
I believe he’s talking about Olin College of Engineering. Created from scratch as an undergraduate only school, with the first class in 2002. Kind of a Harvey Mudd of the east. Campus is near me, and they seem to attract great students.
The other is that is there isn't a way to specify an initial vocabulary with all 256 bytes including the continuation character ##. See github.com/huggingface/.... So in short, if you use their WordPiece you might get tokens.

WordPiece can't always avoid <unk> even with ByteLevel pretokenization. · Issue #1863 · huggingface/tokenizers
The ByteLevel pre-tokenizer is largely used to avoid the possibility of an <unk> token. However, there is a problem with the continuation characters in WordPiece that prevents you from adding all o...
github.com
September 18, 2025 at 3:42 PM
The other is that is there isn't a way to specify an initial vocabulary with all 256 bytes including the continuation character ##. See github.com/huggingface/.... So in short, if you use their WordPiece you might get tokens.
I've posted a few papers I missed including yours here bsky.app/profile/crai.... Thomas pointed that out about 5 seconds after I posted on the discord :-)
14) GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...

GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens, David Kaczér, Miryam De Lhoneux. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 3:17 PM
I've posted a few papers I missed including yours here bsky.app/profile/crai.... Thomas pointed that out about 5 seconds after I posted on the discord :-)


14) GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens, David Kaczér, Miryam De Lhoneux. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:22 PM
14) GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
13) Evaluating Tokenizer Adaptation Methods for Large Language Models on Low-Resource Programming Languages
Georgii Andriushchenko et al
aclanthology.org/2025.acl-srw...
Georgii Andriushchenko et al
aclanthology.org/2025.acl-srw...

Evaluating Tokenizer Adaptation Methods for Large Language Models on Low-Resource Programming Languages
Georgy Andryushchenko, Vladimir V. Ivanov. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
13) Evaluating Tokenizer Adaptation Methods for Large Language Models on Low-Resource Programming Languages
Georgii Andriushchenko et al
aclanthology.org/2025.acl-srw...
Georgii Andriushchenko et al
aclanthology.org/2025.acl-srw...
12) Retrofitting Large Language Models with Dynamic Tokenization
Darius Feher et al
aclanthology.org/2025.acl-lon...
Darius Feher et al
aclanthology.org/2025.acl-lon...

Retrofitting Large Language Models with Dynamic Tokenization
Darius Feher, Ivan Vulić, Benjamin Minixhofer. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
12) Retrofitting Large Language Models with Dynamic Tokenization
Darius Feher et al
aclanthology.org/2025.acl-lon...
Darius Feher et al
aclanthology.org/2025.acl-lon...
11) TokAlign: Efficient Vocabulary Adaptation via Token Alignment
Chong Li et al
aclanthology.org/2025.acl-lon...
Chong Li et al
aclanthology.org/2025.acl-lon...

TokAlign: Efficient Vocabulary Adaptation via Token Alignment
Chong Li, Jiajun Zhang, Chengqing Zong. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
11) TokAlign: Efficient Vocabulary Adaptation via Token Alignment
Chong Li et al
aclanthology.org/2025.acl-lon...
Chong Li et al
aclanthology.org/2025.acl-lon...
10) Sticking to the Mean: Detecting Sticky Tokens in Text Embedding Models
Kexin Chen et al
aclanthology.org/2025.acl-lon...
Kexin Chen et al
aclanthology.org/2025.acl-lon...

Sticking to the Mean: Detecting Sticky Tokens in Text Embedding Models
Kexin Chen, Dongxia Wang, Yi Liu, Haonan Zhang, Wenhai Wang. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
10) Sticking to the Mean: Detecting Sticky Tokens in Text Embedding Models
Kexin Chen et al
aclanthology.org/2025.acl-lon...
Kexin Chen et al
aclanthology.org/2025.acl-lon...
9) Inconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
Andrew Gambardella et al
aclanthology.org/2025.acl-sho...
Andrew Gambardella et al
aclanthology.org/2025.acl-sho...

Inconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
Andrew Gambardella, Takeshi Kojima, Yusuke Iwasawa, Yutaka Matsuo. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
9) Inconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
Andrew Gambardella et al
aclanthology.org/2025.acl-sho...
Andrew Gambardella et al
aclanthology.org/2025.acl-sho...

7) Incorporating Domain Knowledge into Materials Tokenization
Yerim Oh et al
aclanthology.org/2025.acl-lon...
Yerim Oh et al
aclanthology.org/2025.acl-lon...

Incorporating Domain Knowledge into Materials Tokenization
Yerim Oh, Jun-Hyung Park, Junho Kim, SungHo Kim, SangKeun Lee. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
7) Incorporating Domain Knowledge into Materials Tokenization
Yerim Oh et al
aclanthology.org/2025.acl-lon...
Yerim Oh et al
aclanthology.org/2025.acl-lon...
6) Beyond Text Compression: Evaluating Tokenizers Across Scales
Jonas F. Lotz et al
aclanthology.org/2025.acl-lon...
Jonas F. Lotz et al
aclanthology.org/2025.acl-lon...

Beyond Text Compression: Evaluating Tokenizers Across Scales
Jonas F. Lotz, António V. Lopes, Stephan Peitz, Hendra Setiawan, Leonardo Emili. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
6) Beyond Text Compression: Evaluating Tokenizers Across Scales
Jonas F. Lotz et al
aclanthology.org/2025.acl-lon...
Jonas F. Lotz et al
aclanthology.org/2025.acl-lon...
5) Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Zhu Xu et al
aclanthology.org/2025.acl-lon...
Zhu Xu et al
aclanthology.org/2025.acl-lon...

Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Zhu Xu, Zhiqiang Zhao, Zihan Zhang, Yuchi Liu, Quanwei Shen, Fei Liu, Yu Kuang, Jian He, Conglin Liu. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1:...
aclanthology.org
July 30, 2025 at 2:03 PM
5) Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Zhu Xu et al
aclanthology.org/2025.acl-lon...
Zhu Xu et al
aclanthology.org/2025.acl-lon...

3) Splintering Nonconcatenative Languages for Better Tokenization
Yuval Pinter et al
aclanthology.org/2025.finding...
Yuval Pinter et al
aclanthology.org/2025.finding...

Splintering Nonconcatenative Languages for Better Tokenization
Bar Gazit, Shaltiel Shmidman, Avi Shmidman, Yuval Pinter. Findings of the Association for Computational Linguistics: ACL 2025. 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
3) Splintering Nonconcatenative Languages for Better Tokenization
Yuval Pinter et al
aclanthology.org/2025.finding...
Yuval Pinter et al
aclanthology.org/2025.finding...
2) Tokenization is Sensitive to Language Variation
Anna Wegmann et al
aclanthology.org/2025.finding...
Anna Wegmann et al
aclanthology.org/2025.finding...

Tokenization is Sensitive to Language Variation
Anna Wegmann, Dong Nguyen, David Jurgens. Findings of the Association for Computational Linguistics: ACL 2025. 2025.
aclanthology.org
July 30, 2025 at 2:03 PM
2) Tokenization is Sensitive to Language Variation
Anna Wegmann et al
aclanthology.org/2025.finding...
Anna Wegmann et al
aclanthology.org/2025.finding...
1) Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...
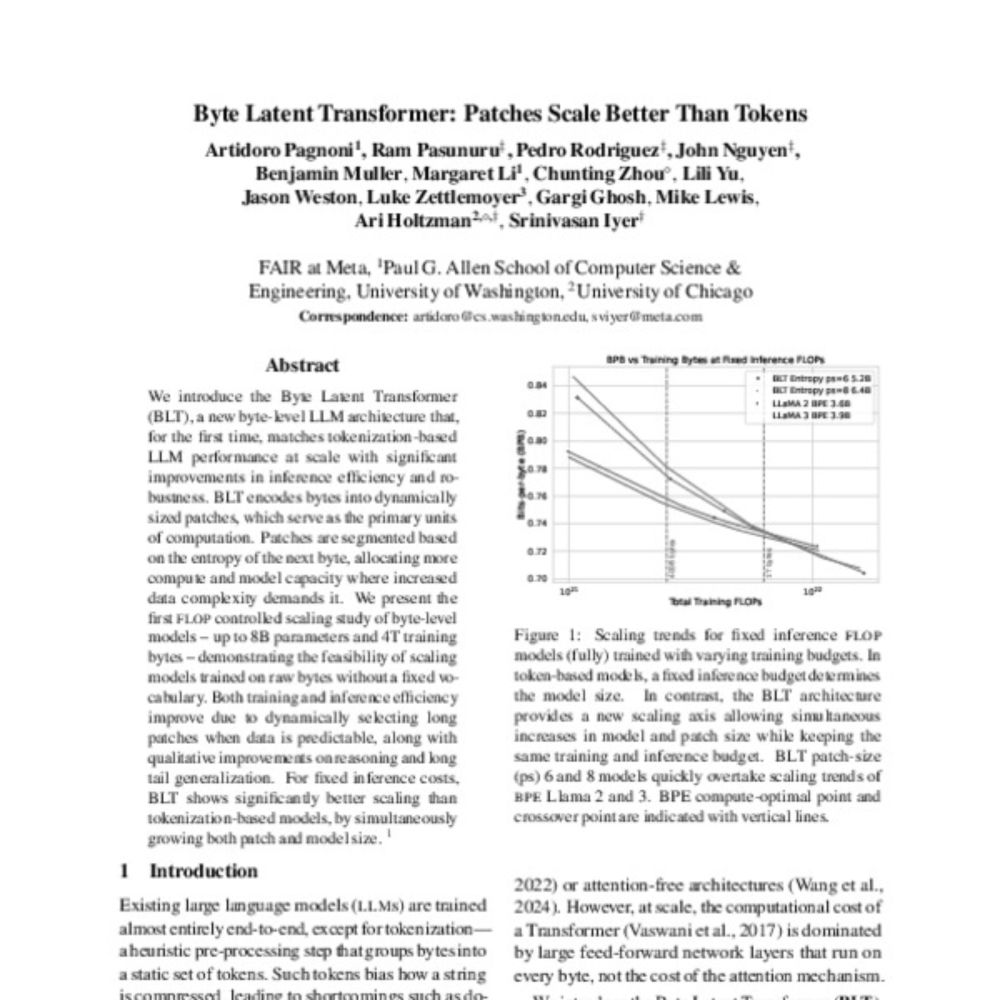
Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni, Ramakanth Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason E Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, Srini...
aclanthology.org
July 30, 2025 at 2:03 PM
1) Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...