




Christos Plachouras
@cplachouras.bsky.social
researcher & musician, phd student @c4dm (audio-language models), prev @mtg @nyu, chrispla.me, he/him
More in the paper and code: github.com/chrispla/syn.... Big thanks to my collaborators @juj-guinot.bsky.social, George Fazekas, Elio Quinton, @emmanouilb.bsky.social, and Johan Pauwels!
I’ll be at IJCNN 2025 in Rome in a month to present this - see you there!
I’ll be at IJCNN 2025 in Rome in a month to present this - see you there!
May 13, 2025 at 2:15 PM
More in the paper and code: github.com/chrispla/syn.... Big thanks to my collaborators @juj-guinot.bsky.social, George Fazekas, Elio Quinton, @emmanouilb.bsky.social, and Johan Pauwels!
I’ll be at IJCNN 2025 in Rome in a month to present this - see you there!
I’ll be at IJCNN 2025 in Rome in a month to present this - see you there!
We argue that downstream task evaluation cannot easily uncover these behaviors, and that equivariance, invariance, and disentanglement are critical components that enable a variety of real-world applications like retrieval, generation, and style transfer.
May 13, 2025 at 2:15 PM
We argue that downstream task evaluation cannot easily uncover these behaviors, and that equivariance, invariance, and disentanglement are critical components that enable a variety of real-world applications like retrieval, generation, and style transfer.
Additionally, model and data scale has different effects for different models on the equivariance, invariance, and disentanglement of concepts in their representations!
May 13, 2025 at 2:15 PM
Additionally, model and data scale has different effects for different models on the equivariance, invariance, and disentanglement of concepts in their representations!
Importantly, different pretraining paradigms and architectures exhibit different behavior in terms of these aspects, suggesting the underlying mechanisms for their downstream performance are different.
May 13, 2025 at 2:15 PM
Importantly, different pretraining paradigms and architectures exhibit different behavior in terms of these aspects, suggesting the underlying mechanisms for their downstream performance are different.
However, we show that representations differ in other important aspects, such as their equivariance (how predictably they change under input transformations), invariance (how stable they remain under them), and disentanglement (how separated different concepts are within them).
May 13, 2025 at 2:15 PM
However, we show that representations differ in other important aspects, such as their equivariance (how predictably they change under input transformations), invariance (how stable they remain under them), and disentanglement (how separated different concepts are within them).
There’s widespread suspicion that as model and data scale increases, model representations converge (e.g., the platonic representation hypothesis (arxiv.org/abs/2405.07987), in part supported by different architectures and pretraining paradigms leading to similar downstream performance.
May 13, 2025 at 2:15 PM
There’s widespread suspicion that as model and data scale increases, model representations converge (e.g., the platonic representation hypothesis (arxiv.org/abs/2405.07987), in part supported by different architectures and pretraining paradigms leading to similar downstream performance.
more at the audio coding and modeling poster sessions (AASP in poster area 2B) tomorrow (Friday) 8:30am to 10am!
paper link: tinyurl.com/4seckd2c
paper link: tinyurl.com/4seckd2c

Learning Music Audio Representations With Limited Data
Large deep-learning models for music, including those focused on learning general-purpose music audio representations, are often assumed to require substantial training data to achieve high performanc...
tinyurl.com
April 10, 2025 at 7:56 AM
more at the audio coding and modeling poster sessions (AASP in poster area 2B) tomorrow (Friday) 8:30am to 10am!
paper link: tinyurl.com/4seckd2c
paper link: tinyurl.com/4seckd2c
finally, we found that regardless of pretraining data scale, the inherent robustness of representations to relevant data perturbations is still concerning
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)

April 10, 2025 at 7:56 AM
finally, we found that regardless of pretraining data scale, the inherent robustness of representations to relevant data perturbations is still concerning
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
we also saw that handcrafted features are actually still outperforming learned representations in some tasks
(MFCCs 🩶, Chroma 🤎)
(MFCCs 🩶, Chroma 🤎)
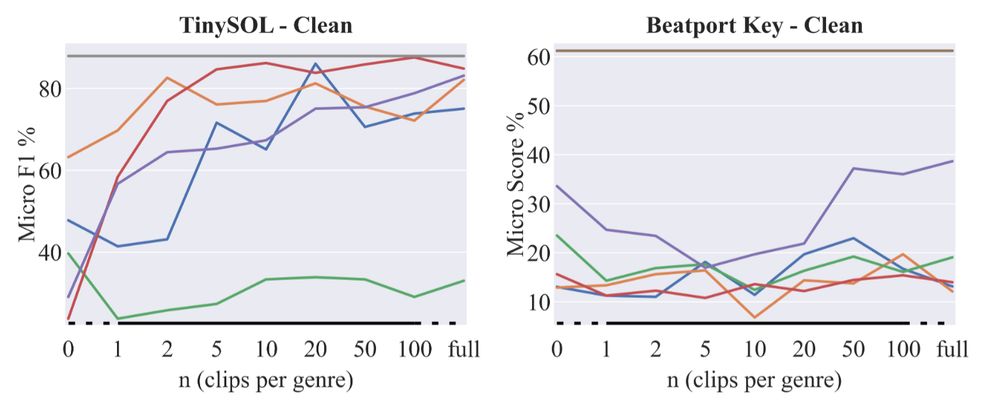
April 10, 2025 at 7:56 AM
we also saw that handcrafted features are actually still outperforming learned representations in some tasks
(MFCCs 🩶, Chroma 🤎)
(MFCCs 🩶, Chroma 🤎)
this could be somewhat attributable to larger-capacity downstream models (2-layer MLP) being able to recover more relevant information from a “bad” representation, hinting that more data could be contributing to relevant information becoming more accessible
(MusiCNN 🟠, VGG 🔵)
(MusiCNN 🟠, VGG 🔵)

April 10, 2025 at 7:56 AM
this could be somewhat attributable to larger-capacity downstream models (2-layer MLP) being able to recover more relevant information from a “bad” representation, hinting that more data could be contributing to relevant information becoming more accessible
(MusiCNN 🟠, VGG 🔵)
(MusiCNN 🟠, VGG 🔵)
we found that representations from some non-trained models perform surprisingly well in tagging, and that the tagging performance gap for different pretraining scales isn’t very large
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)

April 10, 2025 at 7:56 AM
we found that representations from some non-trained models perform surprisingly well in tagging, and that the tagging performance gap for different pretraining scales isn’t very large
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
we created subsets of MTAT ranging from 5 minutes to 8,000 minutes of audio and pretrained MusiCNN, a VGG, AST, CLMR, and a transformer-based MAE. we then extracted representations and trained SLPs and MLPs on music tagging, instrument recognition, and key detection

April 10, 2025 at 7:56 AM
we created subsets of MTAT ranging from 5 minutes to 8,000 minutes of audio and pretrained MusiCNN, a VGG, AST, CLMR, and a transformer-based MAE. we then extracted representations and trained SLPs and MLPs on music tagging, instrument recognition, and key detection