




Christos Plachouras
@cplachouras.bsky.social
researcher & musician, phd student @c4dm (audio-language models), prev @mtg @nyu, chrispla.me, he/him
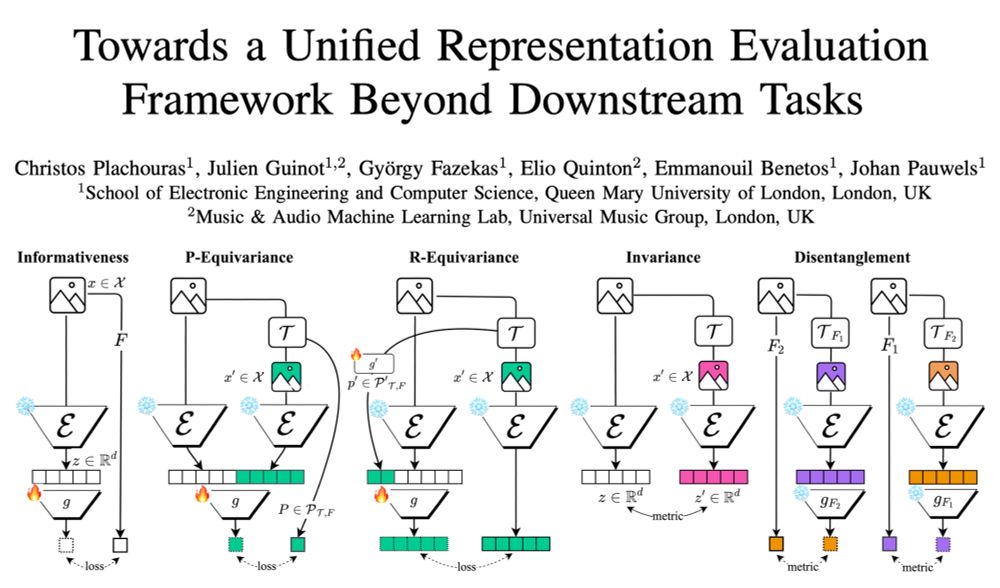
Excited to share our new paper: arxiv.org/abs/2505.06224! We introduce a unified framework for evaluating model representations beyond downstream tasks, and use it to uncover some interesting insights about the structure of representations that challenge conventional wisdom 🔍🧵
May 13, 2025 at 2:15 PM
Excited to share our new paper: arxiv.org/abs/2505.06224! We introduce a unified framework for evaluating model representations beyond downstream tasks, and use it to uncover some interesting insights about the structure of representations that challenge conventional wisdom 🔍🧵
finally, we found that regardless of pretraining data scale, the inherent robustness of representations to relevant data perturbations is still concerning
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)

April 10, 2025 at 7:56 AM
finally, we found that regardless of pretraining data scale, the inherent robustness of representations to relevant data perturbations is still concerning
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
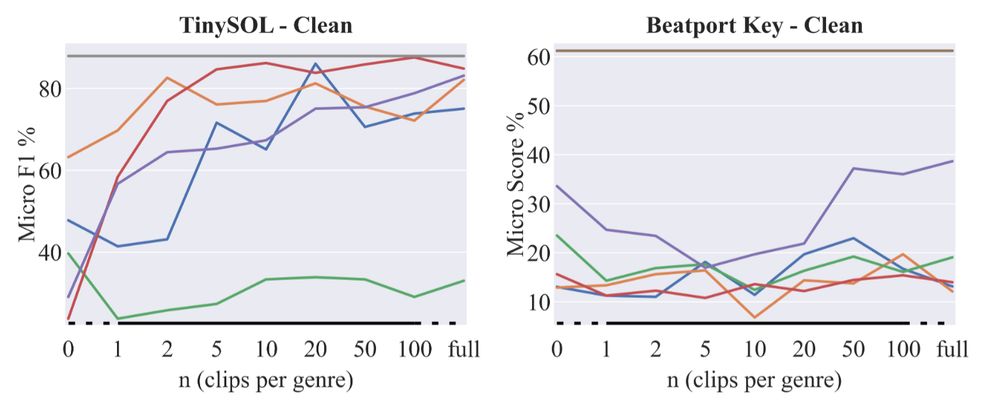
we also saw that handcrafted features are actually still outperforming learned representations in some tasks
(MFCCs 🩶, Chroma 🤎)
(MFCCs 🩶, Chroma 🤎)
April 10, 2025 at 7:56 AM
we also saw that handcrafted features are actually still outperforming learned representations in some tasks
(MFCCs 🩶, Chroma 🤎)
(MFCCs 🩶, Chroma 🤎)
this could be somewhat attributable to larger-capacity downstream models (2-layer MLP) being able to recover more relevant information from a “bad” representation, hinting that more data could be contributing to relevant information becoming more accessible
(MusiCNN 🟠, VGG 🔵)
(MusiCNN 🟠, VGG 🔵)

April 10, 2025 at 7:56 AM
this could be somewhat attributable to larger-capacity downstream models (2-layer MLP) being able to recover more relevant information from a “bad” representation, hinting that more data could be contributing to relevant information becoming more accessible
(MusiCNN 🟠, VGG 🔵)
(MusiCNN 🟠, VGG 🔵)
we found that representations from some non-trained models perform surprisingly well in tagging, and that the tagging performance gap for different pretraining scales isn’t very large
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)

April 10, 2025 at 7:56 AM
we found that representations from some non-trained models perform surprisingly well in tagging, and that the tagging performance gap for different pretraining scales isn’t very large
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
(MusiCNN 🟠, VGG 🔵, AST 🟢, CLMR 🔴, TMAE 🟣, MFCC 🩶)
we created subsets of MTAT ranging from 5 minutes to 8,000 minutes of audio and pretrained MusiCNN, a VGG, AST, CLMR, and a transformer-based MAE. we then extracted representations and trained SLPs and MLPs on music tagging, instrument recognition, and key detection

April 10, 2025 at 7:56 AM
we created subsets of MTAT ranging from 5 minutes to 8,000 minutes of audio and pretrained MusiCNN, a VGG, AST, CLMR, and a transformer-based MAE. we then extracted representations and trained SLPs and MLPs on music tagging, instrument recognition, and key detection
how much music data do we actually need to pretrain effective music representation learning models? we decided to systematically investigate this in our latest #ICASSP2025 paper with @emmanouilb.bsky.social and Johan Pauwels

April 10, 2025 at 7:56 AM
how much music data do we actually need to pretrain effective music representation learning models? we decided to systematically investigate this in our latest #ICASSP2025 paper with @emmanouilb.bsky.social and Johan Pauwels
🎶 5 years ago...
December 15, 2024 at 9:55 PM
🎶 5 years ago...