




Karsten Roth
@confusezius.bsky.social
Large Models, Multimodality, Continual Learning | ELLIS ML PhD with Oriol Vinyals & Zeynep Akata | Previously Google DeepMind, Meta AI, AWS, Vector, MILA
🔗 karroth.com
🔗 karroth.com
💫 After four PhD years on all things multimodal, pre- and post-training, I’m super excited for a new research chapter at Google DeepMind 🇨🇭!
Biggest thanks to @zeynepakata.bsky.social and Oriol Vinyals for all the guidance, support, and incredibly eventful and defining research years ♥️!
Biggest thanks to @zeynepakata.bsky.social and Oriol Vinyals for all the guidance, support, and incredibly eventful and defining research years ♥️!



August 4, 2025 at 2:59 PM
💫 After four PhD years on all things multimodal, pre- and post-training, I’m super excited for a new research chapter at Google DeepMind 🇨🇭!
Biggest thanks to @zeynepakata.bsky.social and Oriol Vinyals for all the guidance, support, and incredibly eventful and defining research years ♥️!
Biggest thanks to @zeynepakata.bsky.social and Oriol Vinyals for all the guidance, support, and incredibly eventful and defining research years ♥️!
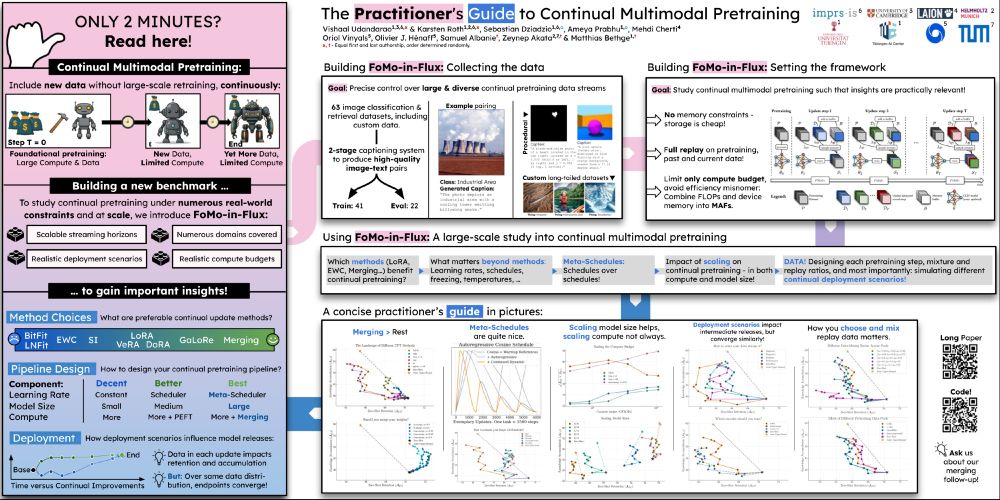
We will present on Wednesday - East Exhibit Hall A-C #3703 ☺️. We've also released the entire codebase with all the methods and 60+ dataloaders that can be mixed and matched in any fashion to study continual pretraining!

December 10, 2024 at 4:42 PM
We will present on Wednesday - East Exhibit Hall A-C #3703 ☺️. We've also released the entire codebase with all the methods and 60+ dataloaders that can be mixed and matched in any fashion to study continual pretraining!
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
December 10, 2024 at 4:42 PM
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
LIxP was carefully designed and tested for scalability!
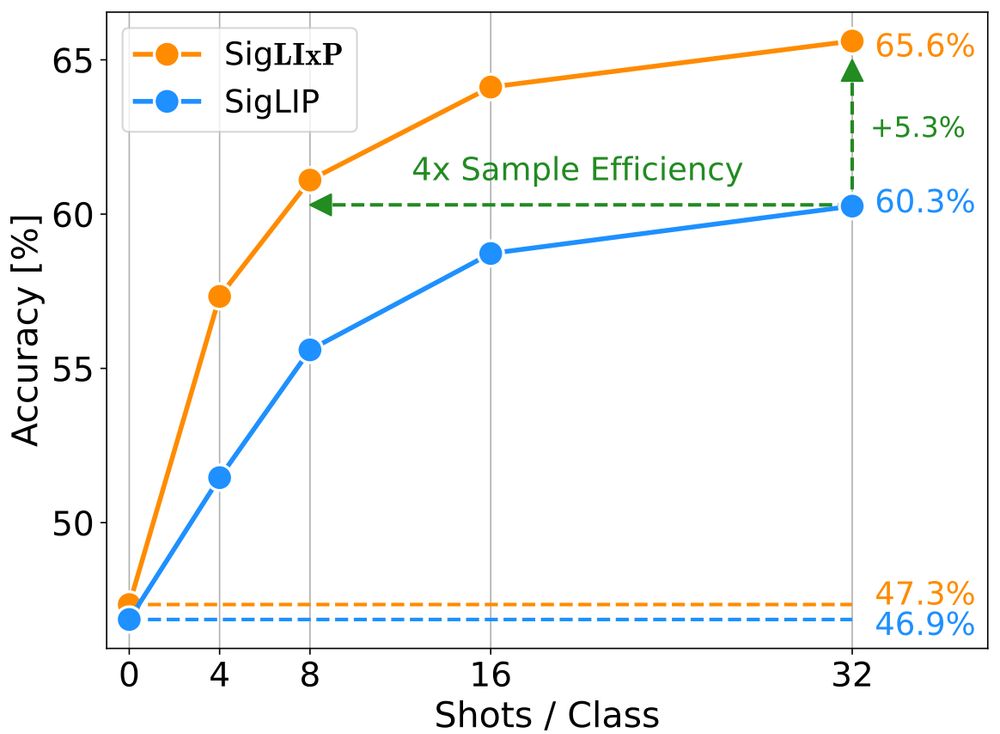
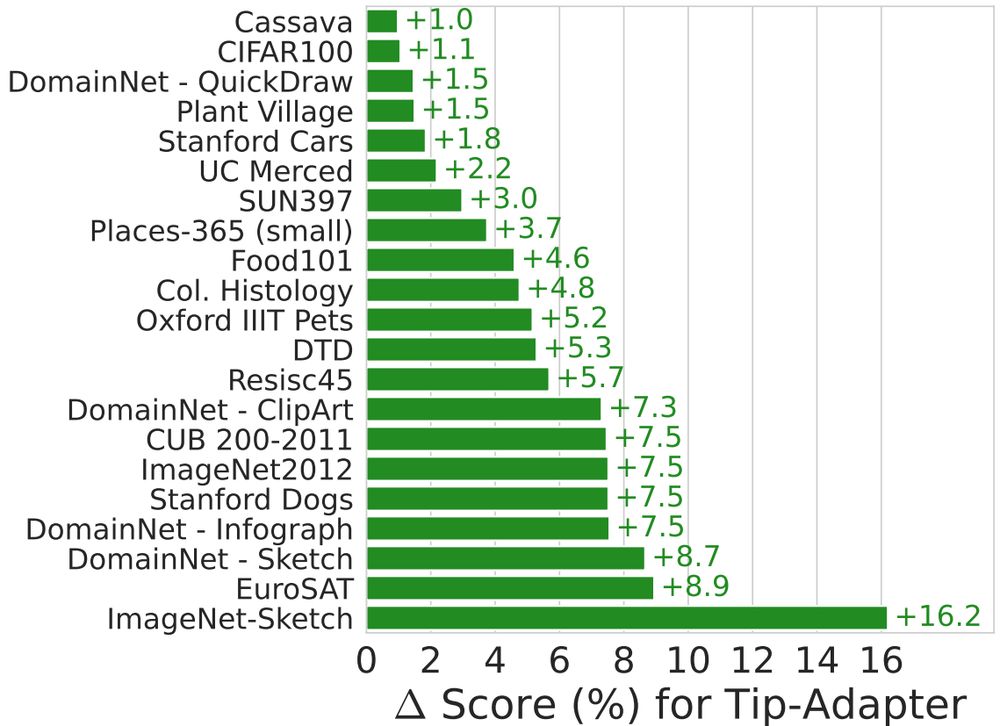
LIxP also maintains the strong zero-shot transfer of CLIP and SigLIP backbones across model sizes (S to L) and data (up to 15B), and allows up to 4x sample efficiency at test time, and up to +16% performance gains!
LIxP also maintains the strong zero-shot transfer of CLIP and SigLIP backbones across model sizes (S to L) and data (up to 15B), and allows up to 4x sample efficiency at test time, and up to +16% performance gains!


November 28, 2024 at 2:33 PM
LIxP was carefully designed and tested for scalability!
LIxP also maintains the strong zero-shot transfer of CLIP and SigLIP backbones across model sizes (S to L) and data (up to 15B), and allows up to 4x sample efficiency at test time, and up to +16% performance gains!
LIxP also maintains the strong zero-shot transfer of CLIP and SigLIP backbones across model sizes (S to L) and data (up to 15B), and allows up to 4x sample efficiency at test time, and up to +16% performance gains!
In LIxP, we utilize a learnable temperature separation and a simple cross-attention-based formalism to augment existing contrastive vision-language training.
We teach models what to expect at test-time in few-shot scenarios.
We teach models what to expect at test-time in few-shot scenarios.


November 28, 2024 at 2:33 PM
In LIxP, we utilize a learnable temperature separation and a simple cross-attention-based formalism to augment existing contrastive vision-language training.
We teach models what to expect at test-time in few-shot scenarios.
We teach models what to expect at test-time in few-shot scenarios.
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread: