



Reposted by Chiao Cheng 🇹🇼 🇸🇬 🇺🇸

I still don’t understand why it can be that distillation works, given the same data.
Is it a way to smuggle more computation into smaller model without looking at the data much more times?
Is it a way to smuggle more computation into smaller model without looking at the data much more times?
December 21, 2024 at 3:23 PM
I still don’t understand why it can be that distillation works, given the same data.
Is it a way to smuggle more computation into smaller model without looking at the data much more times?
Is it a way to smuggle more computation into smaller model without looking at the data much more times?
Reposted by Chiao Cheng 🇹🇼 🇸🇬 🇺🇸

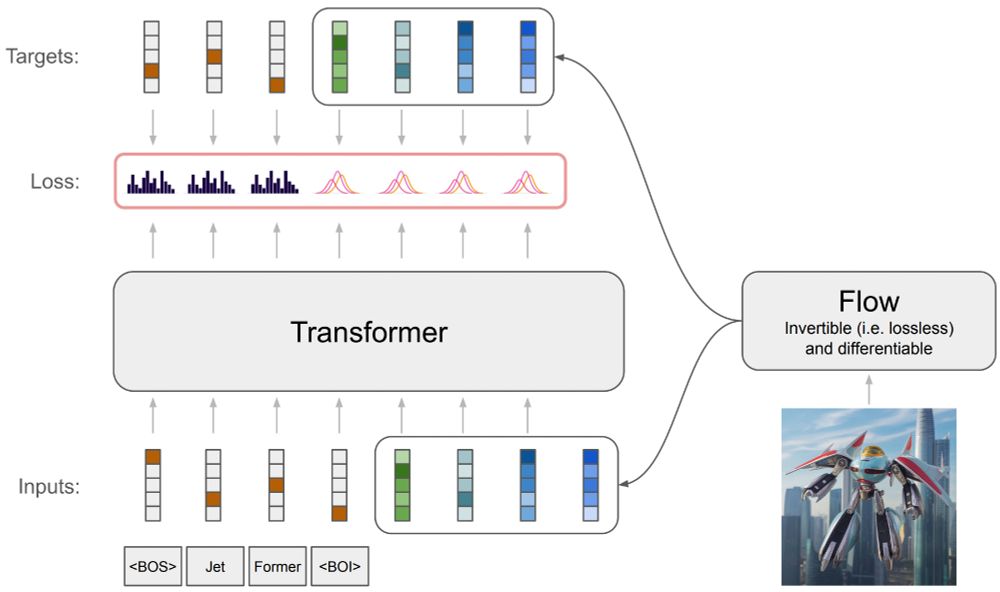
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/