



Chaitanya K. Joshi
@chaitjo.bsky.social
PhD student at University of Cambridge. Intern at FAIR, Meta & Prescient Design, Genentech. Deep Learning for Biomolecule Design.
https://chaitjo.com
https://chaitjo.com
The 3D structure of biomolecules are nature's 'thinking tokens' enroute to the output that we actually truly want to understand: Function.
(Slide from Denny Zhou's Stanford talk on LLM Reasoning)
(Slide from Denny Zhou's Stanford talk on LLM Reasoning)

September 5, 2025 at 4:01 AM
The 3D structure of biomolecules are nature's 'thinking tokens' enroute to the output that we actually truly want to understand: Function.
(Slide from Denny Zhou's Stanford talk on LLM Reasoning)
(Slide from Denny Zhou's Stanford talk on LLM Reasoning)
RosettaFold 3 is here! 🧬🚀
AtomWorks (the foundational data pipeline powering it) is perhaps the really most exciting part of this release!
Congratulations @simonmathis.bsky.social and team!!! ❤️
bioRxiv preprint: www.biorxiv.org/content/10.1...
AtomWorks (the foundational data pipeline powering it) is perhaps the really most exciting part of this release!
Congratulations @simonmathis.bsky.social and team!!! ❤️
bioRxiv preprint: www.biorxiv.org/content/10.1...

August 15, 2025 at 1:26 PM
RosettaFold 3 is here! 🧬🚀
AtomWorks (the foundational data pipeline powering it) is perhaps the really most exciting part of this release!
Congratulations @simonmathis.bsky.social and team!!! ❤️
bioRxiv preprint: www.biorxiv.org/content/10.1...
AtomWorks (the foundational data pipeline powering it) is perhaps the really most exciting part of this release!
Congratulations @simonmathis.bsky.social and team!!! ❤️
bioRxiv preprint: www.biorxiv.org/content/10.1...
🧬 Protein designers: we keep saying we're getting really good at making static, rock-like proteins...
Introducing Dynamic MPNN - our first step towards truly multi-state and 'programmable' protein design! Great collaboration led by Alex Abrudan and Sebastian Pujalte!
Introducing Dynamic MPNN - our first step towards truly multi-state and 'programmable' protein design! Great collaboration led by Alex Abrudan and Sebastian Pujalte!

July 31, 2025 at 6:11 PM
🧬 Protein designers: we keep saying we're getting really good at making static, rock-like proteins...
Introducing Dynamic MPNN - our first step towards truly multi-state and 'programmable' protein design! Great collaboration led by Alex Abrudan and Sebastian Pujalte!
Introducing Dynamic MPNN - our first step towards truly multi-state and 'programmable' protein design! Great collaboration led by Alex Abrudan and Sebastian Pujalte!
Needing a permanent doi was a forcing function to revisit this article on Transformers and Graph Neural Networks: arxiv.org/abs/2506.22084
This is (very) old news, so what's new?
This is (very) old news, so what's new?

June 30, 2025 at 9:22 AM
Needing a permanent doi was a forcing function to revisit this article on Transformers and Graph Neural Networks: arxiv.org/abs/2506.22084
This is (very) old news, so what's new?
This is (very) old news, so what's new?
This was posed by a VC (@dreidco.bsky.social ) on LinkedIn.
Just a thought: Maybe Boltz-2 is also a moment similar to GPT-3 where a sizeable part of the community moves on from academic publishing
and to the world of capabilities, tech reports, and shipping models
Just a thought: Maybe Boltz-2 is also a moment similar to GPT-3 where a sizeable part of the community moves on from academic publishing
and to the world of capabilities, tech reports, and shipping models

June 28, 2025 at 2:30 PM
This was posed by a VC (@dreidco.bsky.social ) on LinkedIn.
Just a thought: Maybe Boltz-2 is also a moment similar to GPT-3 where a sizeable part of the community moves on from academic publishing
and to the world of capabilities, tech reports, and shipping models
Just a thought: Maybe Boltz-2 is also a moment similar to GPT-3 where a sizeable part of the community moves on from academic publishing
and to the world of capabilities, tech reports, and shipping models
Have you ever been frustrated by how hard it is to tinker with AlphaFold 3?
Here's a (hopefully) simple repo to instal locally on laptop/single-GPU and a handy notebook to play around with!
github.com/chaitjo/alph...
Here's a (hopefully) simple repo to instal locally on laptop/single-GPU and a handy notebook to play around with!
github.com/chaitjo/alph...

June 13, 2025 at 7:10 PM
Have you ever been frustrated by how hard it is to tinker with AlphaFold 3?
Here's a (hopefully) simple repo to instal locally on laptop/single-GPU and a handy notebook to play around with!
github.com/chaitjo/alph...
Here's a (hopefully) simple repo to instal locally on laptop/single-GPU and a handy notebook to play around with!
github.com/chaitjo/alph...
Sharing a surprising result on AI molecule generation with Transformers:
All-atom DiT with minimal molecular inductive bias is on par with SOTA equivariant diffusion (SemlaFlow, a very strong and optimized model)
Scaling pure Transformers can alleviate explicit bond prediction!
All-atom DiT with minimal molecular inductive bias is on par with SOTA equivariant diffusion (SemlaFlow, a very strong and optimized model)
Scaling pure Transformers can alleviate explicit bond prediction!

May 22, 2025 at 9:26 AM
Sharing a surprising result on AI molecule generation with Transformers:
All-atom DiT with minimal molecular inductive bias is on par with SOTA equivariant diffusion (SemlaFlow, a very strong and optimized model)
Scaling pure Transformers can alleviate explicit bond prediction!
All-atom DiT with minimal molecular inductive bias is on par with SOTA equivariant diffusion (SemlaFlow, a very strong and optimized model)
Scaling pure Transformers can alleviate explicit bond prediction!
Thanks to everyone involved in the AI for Nucleic Acids Workshop at #ICLR2025! And oh my god - the panel was a 🌶️🌶️🌶️ finish to an exciting day of science, discussions, and community!
@pranam.bsky.social @kishwar.bsky.social @bunnech.bsky.social and many others!
@pranam.bsky.social @kishwar.bsky.social @bunnech.bsky.social and many others!

April 30, 2025 at 10:40 AM
Thanks to everyone involved in the AI for Nucleic Acids Workshop at #ICLR2025! And oh my god - the panel was a 🌶️🌶️🌶️ finish to an exciting day of science, discussions, and community!
@pranam.bsky.social @kishwar.bsky.social @bunnech.bsky.social and many others!
@pranam.bsky.social @kishwar.bsky.social @bunnech.bsky.social and many others!
Here are some recommendations for first timers in Singapore for #ICLR2025 that I’ve been sharing with friends! 🇸🇬
So excited that the ML world will gather in Singapore - And hoping to help people have a great time here! 🤗
So excited that the ML world will gather in Singapore - And hoping to help people have a great time here! 🤗




April 23, 2025 at 5:47 PM
Here are some recommendations for first timers in Singapore for #ICLR2025 that I’ve been sharing with friends! 🇸🇬
So excited that the ML world will gather in Singapore - And hoping to help people have a great time here! 🤗
So excited that the ML world will gather in Singapore - And hoping to help people have a great time here! 🤗
Sharing slides for All-atom Diffusion Transformers
- briefly summarises the big ideas and key takeaways
Link - www.chaitjo.com/publication/...
- briefly summarises the big ideas and key takeaways
Link - www.chaitjo.com/publication/...

April 4, 2025 at 5:40 PM
Sharing slides for All-atom Diffusion Transformers
- briefly summarises the big ideas and key takeaways
Link - www.chaitjo.com/publication/...
- briefly summarises the big ideas and key takeaways
Link - www.chaitjo.com/publication/...
Excited to be a keynote speaker at the Netherlands Society on Biomolecule Modelling annual meeting tomorrow!
I'll be speaking about All Atom Diffusion Transformers for the first time publicly!
Thank you @erikjbekkers.bsky.social for the invitation 🙏
www.nsbm.nl
I'll be speaking about All Atom Diffusion Transformers for the first time publicly!
Thank you @erikjbekkers.bsky.social for the invitation 🙏
www.nsbm.nl

April 1, 2025 at 4:00 PM
Excited to be a keynote speaker at the Netherlands Society on Biomolecule Modelling annual meeting tomorrow!
I'll be speaking about All Atom Diffusion Transformers for the first time publicly!
Thank you @erikjbekkers.bsky.social for the invitation 🙏
www.nsbm.nl
I'll be speaking about All Atom Diffusion Transformers for the first time publicly!
Thank you @erikjbekkers.bsky.social for the invitation 🙏
www.nsbm.nl
Floored by the interest in the All-atom Diffusion Transformers codebase already: github.com/facebookrese...
I've fixed a lot of small issues and tested on two different GPU clusters to ensure everything should now work out of the box.
PS. lightning-hydra template makes for very modular code :)
I've fixed a lot of small issues and tested on two different GPU clusters to ensure everything should now work out of the box.
PS. lightning-hydra template makes for very modular code :)

March 24, 2025 at 9:27 AM
Floored by the interest in the All-atom Diffusion Transformers codebase already: github.com/facebookrese...
I've fixed a lot of small issues and tested on two different GPU clusters to ensure everything should now work out of the box.
PS. lightning-hydra template makes for very modular code :)
I've fixed a lot of small issues and tested on two different GPU clusters to ensure everything should now work out of the box.
PS. lightning-hydra template makes for very modular code :)
Excited to be hosting Bobby Ranjan from @ebi.embl.org at @cst.cam.ac.uk next week for an in-person seminar!
**Modelling microbiome-mediated epigenetic inheritance of disease risk**
💻 Calendar invite, virtual link, and all the details: talks.cam.ac.uk/talk/index/2...
**Modelling microbiome-mediated epigenetic inheritance of disease risk**
💻 Calendar invite, virtual link, and all the details: talks.cam.ac.uk/talk/index/2...

March 12, 2025 at 11:57 AM
Excited to be hosting Bobby Ranjan from @ebi.embl.org at @cst.cam.ac.uk next week for an in-person seminar!
**Modelling microbiome-mediated epigenetic inheritance of disease risk**
💻 Calendar invite, virtual link, and all the details: talks.cam.ac.uk/talk/index/2...
**Modelling microbiome-mediated epigenetic inheritance of disease risk**
💻 Calendar invite, virtual link, and all the details: talks.cam.ac.uk/talk/index/2...
🚀 The next step is to scale up ADiTs with biomolecules, organic crystals, MOFs, and beyond!
There’s huge excitement for universal interatomic ML potentials rn — we’re trying to think about the equivalent for universal generative foundation models and inverse molecular design!
There’s huge excitement for universal interatomic ML potentials rn — we’re trying to think about the equivalent for universal generative foundation models and inverse molecular design!

March 10, 2025 at 4:20 PM
🚀 The next step is to scale up ADiTs with biomolecules, organic crystals, MOFs, and beyond!
There’s huge excitement for universal interatomic ML potentials rn — we’re trying to think about the equivalent for universal generative foundation models and inverse molecular design!
There’s huge excitement for universal interatomic ML potentials rn — we’re trying to think about the equivalent for universal generative foundation models and inverse molecular design!
Doing the expts myself formed new intuitions + broke old ones:
A. We don’t necessarily need SO3 equivariance for generative models, if we scale data/denoiser/compute
B. Similar for math-y discrete + continuous diffusion, as unified generative modelling in latent space is simple
A. We don’t necessarily need SO3 equivariance for generative models, if we scale data/denoiser/compute
B. Similar for math-y discrete + continuous diffusion, as unified generative modelling in latent space is simple

March 10, 2025 at 4:20 PM
Doing the expts myself formed new intuitions + broke old ones:
A. We don’t necessarily need SO3 equivariance for generative models, if we scale data/denoiser/compute
B. Similar for math-y discrete + continuous diffusion, as unified generative modelling in latent space is simple
A. We don’t necessarily need SO3 equivariance for generative models, if we scale data/denoiser/compute
B. Similar for math-y discrete + continuous diffusion, as unified generative modelling in latent space is simple
Idea 2 — Latent diffusion! 🎨
Latent diffusion transformers can sample new, realistic latents -- which we decode to valid molecules/crystals.
ADiT can be told whether to sample a molecule or crystal using classifier-free guidance with class tokens (+ other properties possible)
Latent diffusion transformers can sample new, realistic latents -- which we decode to valid molecules/crystals.
ADiT can be told whether to sample a molecule or crystal using classifier-free guidance with class tokens (+ other properties possible)

March 10, 2025 at 4:20 PM
Idea 2 — Latent diffusion! 🎨
Latent diffusion transformers can sample new, realistic latents -- which we decode to valid molecules/crystals.
ADiT can be told whether to sample a molecule or crystal using classifier-free guidance with class tokens (+ other properties possible)
Latent diffusion transformers can sample new, realistic latents -- which we decode to valid molecules/crystals.
ADiT can be told whether to sample a molecule or crystal using classifier-free guidance with class tokens (+ other properties possible)
Idea 1 — Its all atoms! ⚛️
We can embed molecules and materials to the same latent embedding space, where we hope to learn shared representations of atomic interactions.
Its simple to train a joint autoencoder for all-atom reconstruction of molecules, crystals, and beyond.
We can embed molecules and materials to the same latent embedding space, where we hope to learn shared representations of atomic interactions.
Its simple to train a joint autoencoder for all-atom reconstruction of molecules, crystals, and beyond.

March 10, 2025 at 4:20 PM
Idea 1 — Its all atoms! ⚛️
We can embed molecules and materials to the same latent embedding space, where we hope to learn shared representations of atomic interactions.
Its simple to train a joint autoencoder for all-atom reconstruction of molecules, crystals, and beyond.
We can embed molecules and materials to the same latent embedding space, where we hope to learn shared representations of atomic interactions.
Its simple to train a joint autoencoder for all-atom reconstruction of molecules, crystals, and beyond.
We generalized Diffusion Transformers to all possible 3D atomic systems, and obtained very strong results for molecule and crystal generation using **one** jointly trained model.
An amazing collaboration w/ Xiang Fu, Yi-Lun Liao, Vahe Garekhanyan, Ben Miller, Anuroop Sriram and Zack Ulissi 👊
An amazing collaboration w/ Xiang Fu, Yi-Lun Liao, Vahe Garekhanyan, Ben Miller, Anuroop Sriram and Zack Ulissi 👊

March 10, 2025 at 4:20 PM
We generalized Diffusion Transformers to all possible 3D atomic systems, and obtained very strong results for molecule and crystal generation using **one** jointly trained model.
An amazing collaboration w/ Xiang Fu, Yi-Lun Liao, Vahe Garekhanyan, Ben Miller, Anuroop Sriram and Zack Ulissi 👊
An amazing collaboration w/ Xiang Fu, Yi-Lun Liao, Vahe Garekhanyan, Ben Miller, Anuroop Sriram and Zack Ulissi 👊
Introducing All-atom Diffusion Transformers
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇

March 10, 2025 at 4:20 PM
Introducing All-atom Diffusion Transformers
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
— towards Foundation Models for generative chemistry, from my internship with the FAIR Chemistry team
There are a couple ML ideas which I think are new and exciting in here 👇
Feeling mostly very relieved to share that gRNAde was accepted at @iclr-conf.bsky.social as a Spotlight!
What started as a side project over 2 years ago has lead to a spotlight paper and a new scientific journey for me --
Here I am learning how to pipette :D
What started as a side project over 2 years ago has lead to a spotlight paper and a new scientific journey for me --
Here I am learning how to pipette :D

March 4, 2025 at 12:12 PM
Feeling mostly very relieved to share that gRNAde was accepted at @iclr-conf.bsky.social as a Spotlight!
What started as a side project over 2 years ago has lead to a spotlight paper and a new scientific journey for me --
Here I am learning how to pipette :D
What started as a side project over 2 years ago has lead to a spotlight paper and a new scientific journey for me --
Here I am learning how to pipette :D
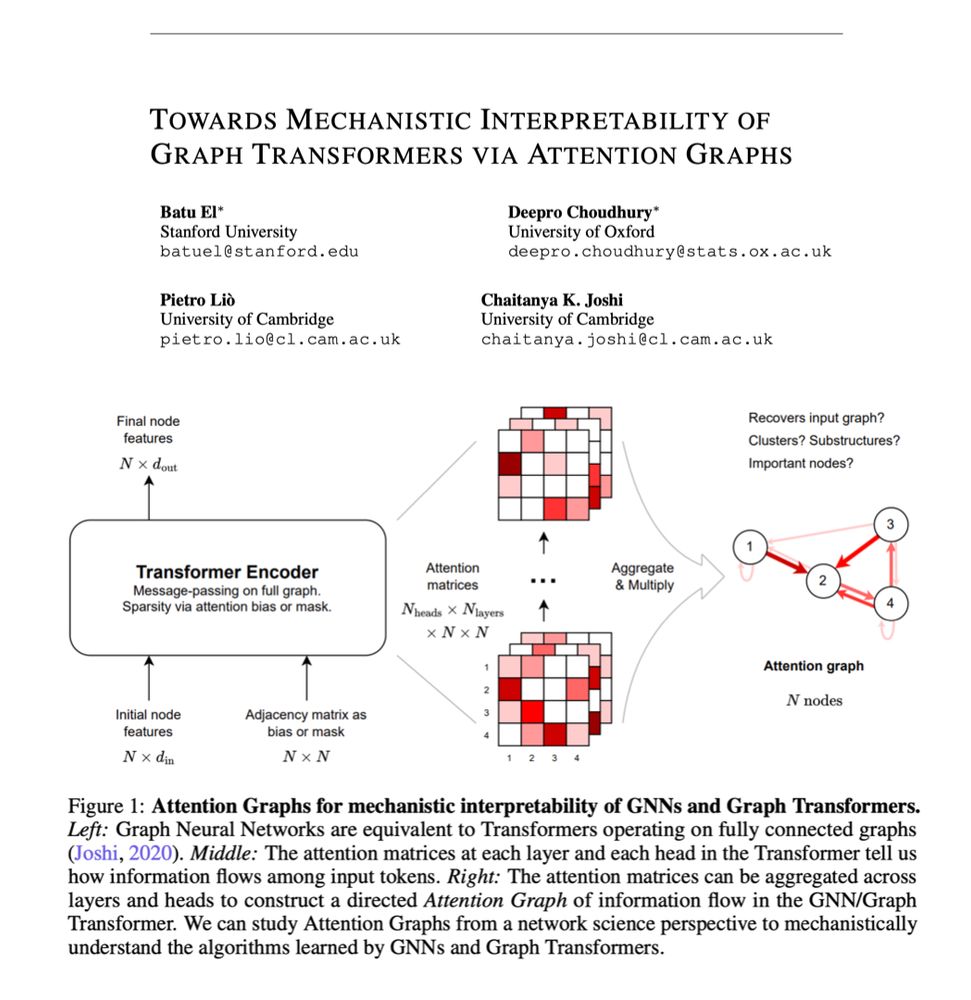
The key ideas are:
- Attention across multi-heads and layers can be seen as a heterogenous, dynamically evolving graph.
- Attention graphs are complex systems represent information flow in Transformers.
- We can use network science to extract mechanistic insights from them!
- Attention across multi-heads and layers can be seen as a heterogenous, dynamically evolving graph.
- Attention graphs are complex systems represent information flow in Transformers.
- We can use network science to extract mechanistic insights from them!

February 19, 2025 at 11:57 AM
The key ideas are:
- Attention across multi-heads and layers can be seen as a heterogenous, dynamically evolving graph.
- Attention graphs are complex systems represent information flow in Transformers.
- We can use network science to extract mechanistic insights from them!
- Attention across multi-heads and layers can be seen as a heterogenous, dynamically evolving graph.
- Attention graphs are complex systems represent information flow in Transformers.
- We can use network science to extract mechanistic insights from them!
Our first attempts at mechanistic interpretability of Transformers from the perspective of network science and graph theory!
A wonderful collaboration with superstar MPhil students Batu El, Deepro Choudhury, as well as Pietro Liò as part of the Geometric Deep Learning class at @cst.cam.ac.uk
A wonderful collaboration with superstar MPhil students Batu El, Deepro Choudhury, as well as Pietro Liò as part of the Geometric Deep Learning class at @cst.cam.ac.uk
February 19, 2025 at 11:57 AM
Our first attempts at mechanistic interpretability of Transformers from the perspective of network science and graph theory!
A wonderful collaboration with superstar MPhil students Batu El, Deepro Choudhury, as well as Pietro Liò as part of the Geometric Deep Learning class at @cst.cam.ac.uk
A wonderful collaboration with superstar MPhil students Batu El, Deepro Choudhury, as well as Pietro Liò as part of the Geometric Deep Learning class at @cst.cam.ac.uk
Trying to copy the greats Pietro and @petar-v.bsky.social giving a guest lecture for the GDL class today!

February 10, 2025 at 9:25 PM
Trying to copy the greats Pietro and @petar-v.bsky.social giving a guest lecture for the GDL class today!
I've started visiting Phil Holliger's lab at @mrclmb.bsky.social this week - its been inspiring and challenging in the best way!
A short journey from JJ Thomson Avenue (electrons) to Francis Crick Avenue (nucleic acids) :)
A short journey from JJ Thomson Avenue (electrons) to Francis Crick Avenue (nucleic acids) :)

February 8, 2025 at 11:02 AM
I've started visiting Phil Holliger's lab at @mrclmb.bsky.social this week - its been inspiring and challenging in the best way!
A short journey from JJ Thomson Avenue (electrons) to Francis Crick Avenue (nucleic acids) :)
A short journey from JJ Thomson Avenue (electrons) to Francis Crick Avenue (nucleic acids) :)
I’ve now had Lao Gan Ma chilly oil with peanuts in Singapore, US, UK
— and I must say there is something really addictive about the product sold in UK which is so obviously more tasty than the one in Sg or US. Just by frequency of how much I’m consuming it.
— and I must say there is something really addictive about the product sold in UK which is so obviously more tasty than the one in Sg or US. Just by frequency of how much I’m consuming it.

January 31, 2025 at 8:23 PM
I’ve now had Lao Gan Ma chilly oil with peanuts in Singapore, US, UK
— and I must say there is something really addictive about the product sold in UK which is so obviously more tasty than the one in Sg or US. Just by frequency of how much I’m consuming it.
— and I must say there is something really addictive about the product sold in UK which is so obviously more tasty than the one in Sg or US. Just by frequency of how much I’m consuming it.