




CATH-Gene3D
@cathgene3d.bsky.social
CATH/Gene3D at University College London
Evolutionary relationships and classification of protein domains.
https://cathdb.info
https://ted.cathdb.info
Evolutionary relationships and classification of protein domains.
https://cathdb.info
https://ted.cathdb.info
Now Maria Martín from UniProt is telling us how AI-based tools are shaping the future of one of the key resources for protein sequences and function.

September 16, 2025 at 1:34 PM
Now Maria Martín from UniProt is telling us how AI-based tools are shaping the future of one of the key resources for protein sequences and function.
From structures to sequences, now Alex Bateman and the quest to annotate and classify all proteins!

September 16, 2025 at 1:07 PM
From structures to sequences, now Alex Bateman and the quest to annotate and classify all proteins!
Starting our afternoon session with a talk by Sameer Velankar, of PDBe and AFDB fame among other endeavours!

September 16, 2025 at 12:46 PM
Starting our afternoon session with a talk by Sameer Velankar, of PDBe and AFDB fame among other endeavours!
And now @gonzaparra.bsky.social on his first talk on protein frustration as a PI! Well done!

September 16, 2025 at 11:32 AM
And now @gonzaparra.bsky.social on his first talk on protein frustration as a PI! Well done!
David Jones, on novel folds in AFDB and CATH’s founding being celebrated at a now-closed Pizza place in Euston Station

September 16, 2025 at 11:09 AM
David Jones, on novel folds in AFDB and CATH’s founding being celebrated at a now-closed Pizza place in Euston Station
From CATH to Computational Enzymology, Dame Janet Thornton on the birth of CATH and beyond!

September 16, 2025 at 10:44 AM
From CATH to Computational Enzymology, Dame Janet Thornton on the birth of CATH and beyond!
First Keynote by Burkhard Rost, on the impact of protein language models on the field of structural biology

September 16, 2025 at 10:19 AM
First Keynote by Burkhard Rost, on the impact of protein language models on the field of structural biology
Kickstarting our symposium “Protein Annotations in the age of AI” at UCL!

September 16, 2025 at 10:19 AM
Kickstarting our symposium “Protein Annotations in the age of AI” at UCL!
Another CATH outing at Greenwich Park after a lovely cruise along the Thames and a pub lunch!

August 20, 2025 at 6:18 PM
Another CATH outing at Greenwich Park after a lovely cruise along the Thames and a pub lunch!
CATHmas lunch 2024!


December 18, 2024 at 2:21 PM
CATHmas lunch 2024!
For those without access to the Science article, we added a full access link on the TED website (ted.cathdb.info) landing page!
6/6
6/6

November 16, 2024 at 3:05 PM
For those without access to the Science article, we added a full access link on the TED website (ted.cathdb.info) landing page!
6/6
6/6
All data and code to reproduce TED and TED-web are available in Zenodo
zenodo.org/records/1390...
Here you can find per-chain and per-domain annotations, domain interaction data and model weights
4/6 🧵⤵️
zenodo.org/records/1390...
Here you can find per-chain and per-domain annotations, domain interaction data and model weights
4/6 🧵⤵️

November 16, 2024 at 3:05 PM
All data and code to reproduce TED and TED-web are available in Zenodo
zenodo.org/records/1390...
Here you can find per-chain and per-domain annotations, domain interaction data and model weights
4/6 🧵⤵️
zenodo.org/records/1390...
Here you can find per-chain and per-domain annotations, domain interaction data and model weights
4/6 🧵⤵️
Ian Sillitoe made a beautiful web interface for TED (ted.cathdb.info), which allows the community to look up their favourite UniProt Identifier, visualise domain annotations and associated metadata on quality and interactions.
3/6 🧵⤵️
3/6 🧵⤵️

November 16, 2024 at 3:05 PM
Ian Sillitoe made a beautiful web interface for TED (ted.cathdb.info), which allows the community to look up their favourite UniProt Identifier, visualise domain annotations and associated metadata on quality and interactions.
3/6 🧵⤵️
3/6 🧵⤵️
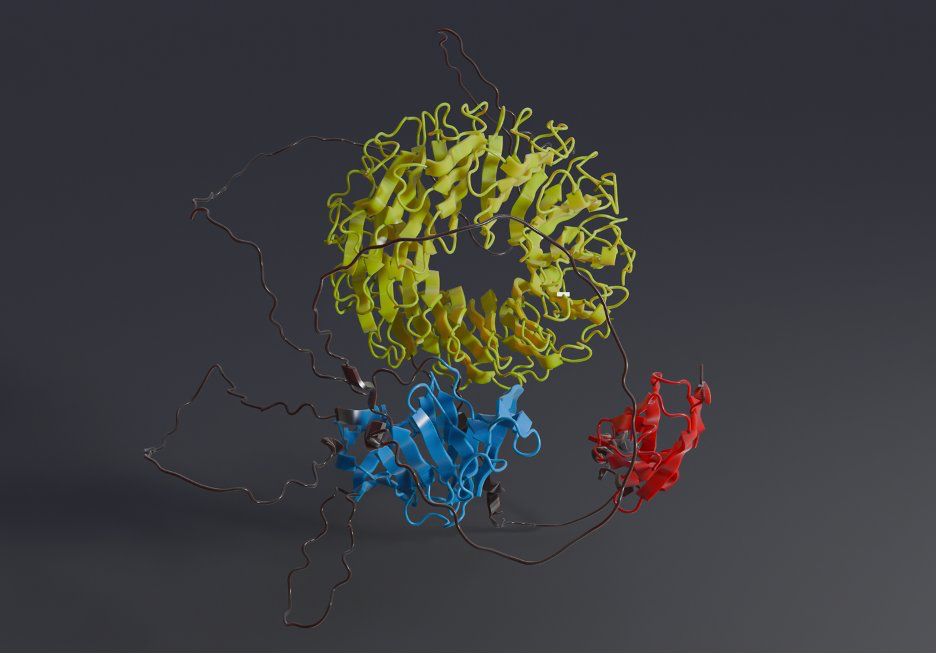
Compared to our bioRxiv version, we processed TED redundant in the same fashion as TED100, swapping the previous multi-chain approach with a single-chain approach.
Each of the 214M chains in TED is now being treated equally, identifying 365 million protein domains.
2/6 🧵⤵️
Each of the 214M chains in TED is now being treated equally, identifying 365 million protein domains.
2/6 🧵⤵️
November 16, 2024 at 3:05 PM
Compared to our bioRxiv version, we processed TED redundant in the same fashion as TED100, swapping the previous multi-chain approach with a single-chain approach.
Each of the 214M chains in TED is now being treated equally, identifying 365 million protein domains.
2/6 🧵⤵️
Each of the 214M chains in TED is now being treated equally, identifying 365 million protein domains.
2/6 🧵⤵️