




Cansu Sancaktar
@cansusancaktar.bsky.social
PhD Student @ Max Planck Institute for Intelligent Systems & University of Tübingen | Working on intrinsically motivated open-ended reinforcement learning 🤖
Want to find out more about SENSEI?
🗣️ICML Poster West Exhibition Hall, 16 Jul, 11a.m. PDT, No. W-707
📜arxiv.org/abs/2503.01584
🌐sites.google.com/view/sensei-paper
Work done with @cgumbsch.bsky.social (co-first), @zadaianchuk.bsky.social, @pavelkolevbg.bsky.social and @gmartius.bsky.social
8/8
🗣️ICML Poster West Exhibition Hall, 16 Jul, 11a.m. PDT, No. W-707
📜arxiv.org/abs/2503.01584
🌐sites.google.com/view/sensei-paper
Work done with @cgumbsch.bsky.social (co-first), @zadaianchuk.bsky.social, @pavelkolevbg.bsky.social and @gmartius.bsky.social
8/8
July 14, 2025 at 8:02 AM
Want to find out more about SENSEI?
🗣️ICML Poster West Exhibition Hall, 16 Jul, 11a.m. PDT, No. W-707
📜arxiv.org/abs/2503.01584
🌐sites.google.com/view/sensei-paper
Work done with @cgumbsch.bsky.social (co-first), @zadaianchuk.bsky.social, @pavelkolevbg.bsky.social and @gmartius.bsky.social
8/8
🗣️ICML Poster West Exhibition Hall, 16 Jul, 11a.m. PDT, No. W-707
📜arxiv.org/abs/2503.01584
🌐sites.google.com/view/sensei-paper
Work done with @cgumbsch.bsky.social (co-first), @zadaianchuk.bsky.social, @pavelkolevbg.bsky.social and @gmartius.bsky.social
8/8
SENSEI can also guide exploration in combination with task rewards. When playing Pokémon Red from pixels, we achieve superior performance to Dreamer (pure task rewards) and Plan2Explore. Only SENSEI manages to obtain the first Gym Badge within 2M steps of exploration 🥇
7/8
7/8

July 14, 2025 at 8:02 AM
SENSEI can also guide exploration in combination with task rewards. When playing Pokémon Red from pixels, we achieve superior performance to Dreamer (pure task rewards) and Plan2Explore. Only SENSEI manages to obtain the first Gym Badge within 2M steps of exploration 🥇
7/8
7/8
The agent learns a world model during exploration that can later be re-used to solve downstream tasks. We demonstrate more sample-efficient policy learning with SENSEI compared to exploration via Plan2Explore.
6/8
6/8
July 14, 2025 at 8:02 AM
The agent learns a world model during exploration that can later be re-used to solve downstream tasks. We demonstrate more sample-efficient policy learning with SENSEI compared to exploration via Plan2Explore.
6/8
6/8
Through the combination of semantic exploration with epistemic uncertainty, the agent unlocks a variety of interesting behaviors during task-free exploration. For example, in Robodesk the agent focuses on interacting with all available objects 🦾
5/8
5/8
July 14, 2025 at 8:02 AM
Through the combination of semantic exploration with epistemic uncertainty, the agent unlocks a variety of interesting behaviors during task-free exploration. For example, in Robodesk the agent focuses on interacting with all available objects 🦾
5/8
5/8
To continuously push the frontier of experience, we combine semantic rewards with epistemic uncertainty deploying an adaptive go-explore strategy. The agent first tries to reach interesting situations (🔝 semantic reward) and then tries new things from there (🔝 uncertainty)
4/8
4/8

July 14, 2025 at 8:02 AM
To continuously push the frontier of experience, we combine semantic rewards with epistemic uncertainty deploying an adaptive go-explore strategy. The agent first tries to reach interesting situations (🔝 semantic reward) and then tries new things from there (🔝 uncertainty)
4/8
4/8
How do we get a signal for meaningful behavior?🤔
Our approach is to use human priors found in foundation models. We extend MOTIF to VLMs: A VLM compares observation pairs, collected through self-supervised exploration. This ranking is distilled into a reward function.
3/8
Our approach is to use human priors found in foundation models. We extend MOTIF to VLMs: A VLM compares observation pairs, collected through self-supervised exploration. This ranking is distilled into a reward function.
3/8

July 14, 2025 at 8:02 AM
How do we get a signal for meaningful behavior?🤔
Our approach is to use human priors found in foundation models. We extend MOTIF to VLMs: A VLM compares observation pairs, collected through self-supervised exploration. This ranking is distilled into a reward function.
3/8
Our approach is to use human priors found in foundation models. We extend MOTIF to VLMs: A VLM compares observation pairs, collected through self-supervised exploration. This ranking is distilled into a reward function.
3/8
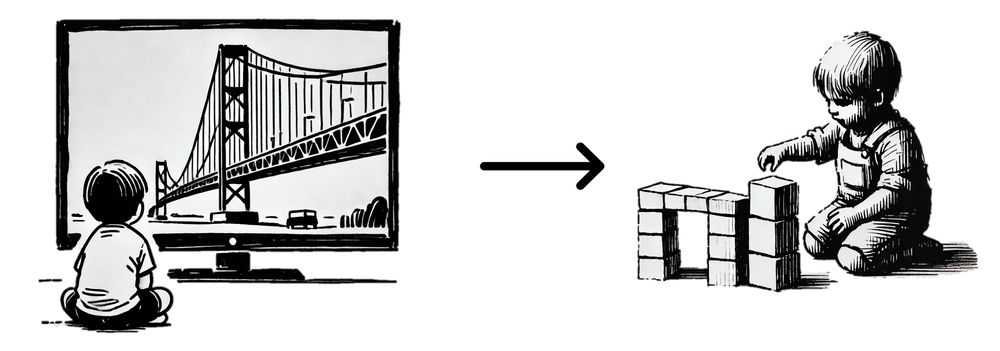
Intrinsically motivated exploration faces a chicken-or-egg problem: how do you know what’s worth exploring before trying it out and experiencing the consequences?
Children solve this by observing and imitating adults. We bring such semantic exploration to artificial agents.
2/8
Children solve this by observing and imitating adults. We bring such semantic exploration to artificial agents.
2/8
July 14, 2025 at 8:02 AM
Intrinsically motivated exploration faces a chicken-or-egg problem: how do you know what’s worth exploring before trying it out and experiencing the consequences?
Children solve this by observing and imitating adults. We bring such semantic exploration to artificial agents.
2/8
Children solve this by observing and imitating adults. We bring such semantic exploration to artificial agents.
2/8