



Camomille5000
@camomille5000.bsky.social
I like computer vision 2d, 3d and machine learning.
Reposted by Camomille5000

The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465

January 22, 2025 at 9:11 AM
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465
Reposted by Camomille5000

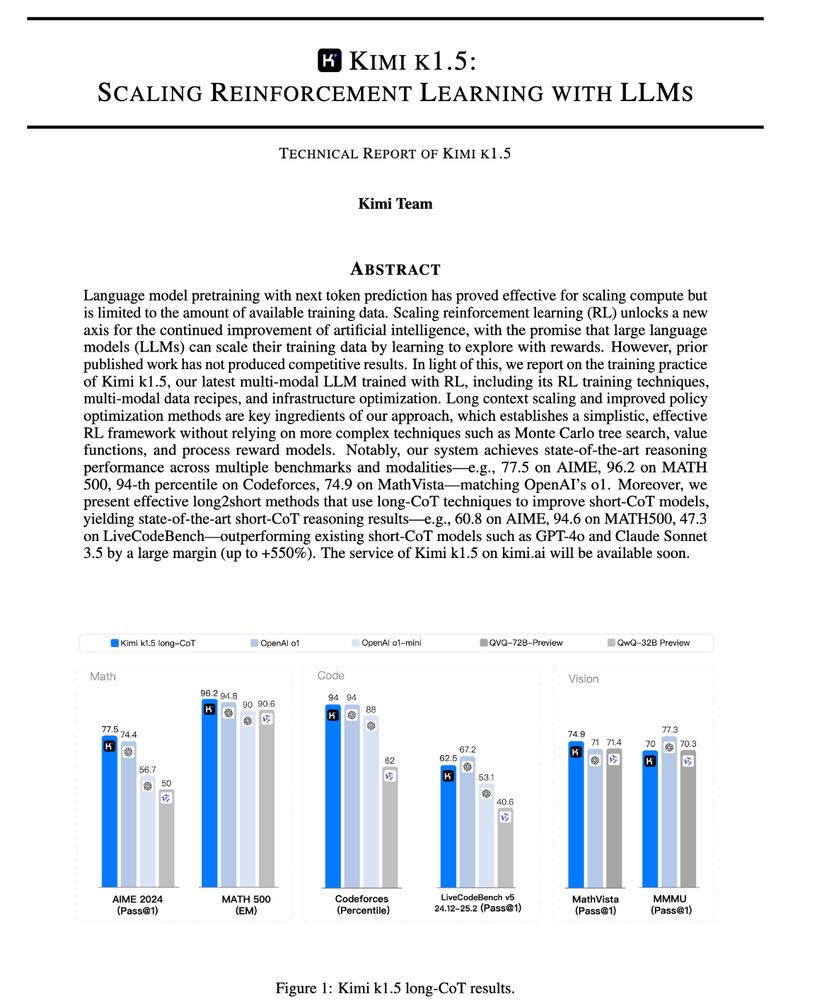
hahahahah there were actually two technical reports for RL reasoning models today, kimi 1.5 also has good stuff on reward shaping + RL infra
kimi 1.5 report: https://buff.ly/4jqgCOa
kimi 1.5 report: https://buff.ly/4jqgCOa
January 20, 2025 at 3:55 PM
hahahahah there were actually two technical reports for RL reasoning models today, kimi 1.5 also has good stuff on reward shaping + RL infra
kimi 1.5 report: https://buff.ly/4jqgCOa
kimi 1.5 report: https://buff.ly/4jqgCOa
Reposted by Camomille5000
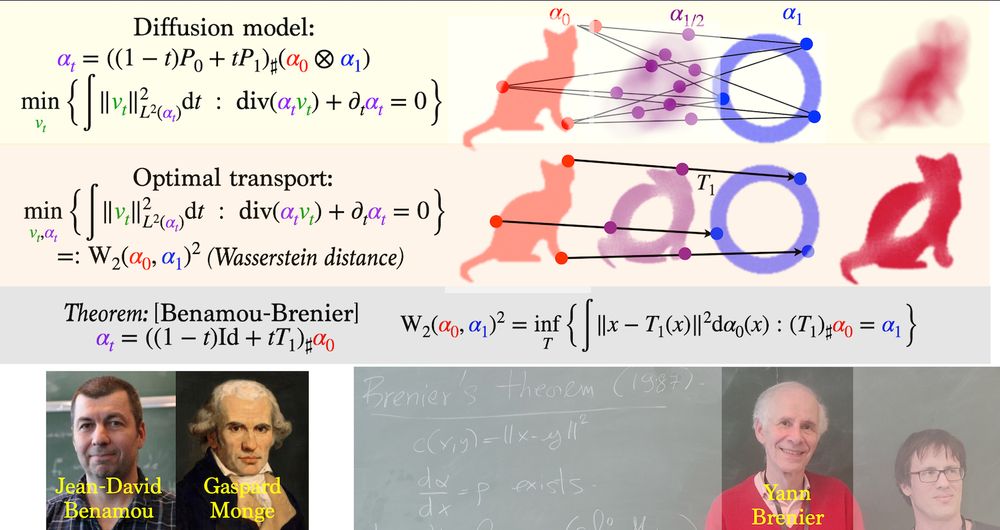
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
January 15, 2025 at 7:08 PM
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
Reposted by Camomille5000

Another nail in the coffin of cosine similarity!
I started disliking cossim some years ago due to multiple reasons such as the non-linearity around 0.0 and the loss of certainty-information due to the normalization of feature vectors but this study seems to give another good reason to abandon it.
I started disliking cossim some years ago due to multiple reasons such as the non-linearity around 0.0 and the loss of certainty-information due to the normalization of feature vectors but this study seems to give another good reason to abandon it.

Cosine Similarity: Not the Silver Bullet We Thought It Was | Shaped Blog
In the world of machine learning and data science, cosine similarity has long been a go-to metric for measuring the semantic similarity between high-dimensional objects. However, a new study by resear...
www.shaped.ai
January 14, 2025 at 6:26 AM
Another nail in the coffin of cosine similarity!
I started disliking cossim some years ago due to multiple reasons such as the non-linearity around 0.0 and the loss of certainty-information due to the normalization of feature vectors but this study seems to give another good reason to abandon it.
I started disliking cossim some years ago due to multiple reasons such as the non-linearity around 0.0 and the loss of certainty-information due to the normalization of feature vectors but this study seems to give another good reason to abandon it.
Reposted by Camomille5000

MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
The authors propose a pre-training framework using synthetic cross-modal data to enhance LoFTR and RoMa for matching across medical imaging modalities like CT, MR, PET, and SPECT.
zju3dv.github.io/MatchAnything/
The authors propose a pre-training framework using synthetic cross-modal data to enhance LoFTR and RoMa for matching across medical imaging modalities like CT, MR, PET, and SPECT.
zju3dv.github.io/MatchAnything/
January 14, 2025 at 6:46 AM
MatchAnything: Universal Cross-Modality Image Matching with Large-Scale Pre-Training
The authors propose a pre-training framework using synthetic cross-modal data to enhance LoFTR and RoMa for matching across medical imaging modalities like CT, MR, PET, and SPECT.
zju3dv.github.io/MatchAnything/
The authors propose a pre-training framework using synthetic cross-modal data to enhance LoFTR and RoMa for matching across medical imaging modalities like CT, MR, PET, and SPECT.
zju3dv.github.io/MatchAnything/
Reposted by Camomille5000

The GAN is dead; long live the GAN! A Modern Baseline GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN

January 10, 2025 at 10:15 AM
The GAN is dead; long live the GAN! A Modern Baseline GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
Reposted by Camomille5000

Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
ChatGPT and Image Matching – Wide baseline stereo meets deep learning
Are we done yet?
ducha-aiki.github.io
January 2, 2025 at 9:01 PM
Image matching and ChatGPT - new post in the wide baseline stereo blog.
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
tl;dr: it is good, even feels like human, but not perfect.
ducha-aiki.github.io/wide-baselin...
Reposted by Camomille5000

Introducing ASAL: Automating the Search for Artificial Life with Foundation Models
Blog: sakana.ai/asal/
We propose a new method called Automated Search for Artificial Life (ASAL) which uses foundation models to automate the discovery of the most interesting and open-ended artificial lifeforms!
Blog: sakana.ai/asal/
We propose a new method called Automated Search for Artificial Life (ASAL) which uses foundation models to automate the discovery of the most interesting and open-ended artificial lifeforms!
December 24, 2024 at 2:58 AM
Introducing ASAL: Automating the Search for Artificial Life with Foundation Models
Blog: sakana.ai/asal/
We propose a new method called Automated Search for Artificial Life (ASAL) which uses foundation models to automate the discovery of the most interesting and open-ended artificial lifeforms!
Blog: sakana.ai/asal/
We propose a new method called Automated Search for Artificial Life (ASAL) which uses foundation models to automate the discovery of the most interesting and open-ended artificial lifeforms!
Reposted by Camomille5000

My book is (at last) out, just in time for Christmas!
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
A blog post to celebrate and present it: francisbach.com/my-book-is-o...

December 21, 2024 at 3:23 PM
My book is (at last) out, just in time for Christmas!
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
Reposted by Camomille5000

This paper looks interesting - it argues that you don’t need adaptive systems like Adam to get good gradient-based training, instead you can just set a learning rate for different groups of units based on initialization:
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
arxiv.org/abs/2412.11768
#MLSky #NeuroAI

No More Adam: Learning Rate Scaling at Initialization is All You Need
In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM...
arxiv.org
December 20, 2024 at 7:00 PM
This paper looks interesting - it argues that you don’t need adaptive systems like Adam to get good gradient-based training, instead you can just set a learning rate for different groups of units based on initialization:
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
arxiv.org/abs/2412.11768
#MLSky #NeuroAI
Reposted by Camomille5000

Nouvelle vidéo ! Je reviens sur deux articles paru récemment au sujet des capacités des LLM à mentir et manipuler.
Au-delà des annonces spectaculaire du type : "o1 a réussi à s'échapper !!!", que disent vraiment ces articles ? Eh bien nous allons voir.
(lien dans la réponse)
Au-delà des annonces spectaculaire du type : "o1 a réussi à s'échapper !!!", que disent vraiment ces articles ? Eh bien nous allons voir.
(lien dans la réponse)

December 21, 2024 at 11:01 AM
Nouvelle vidéo ! Je reviens sur deux articles paru récemment au sujet des capacités des LLM à mentir et manipuler.
Au-delà des annonces spectaculaire du type : "o1 a réussi à s'échapper !!!", que disent vraiment ces articles ? Eh bien nous allons voir.
(lien dans la réponse)
Au-delà des annonces spectaculaire du type : "o1 a réussi à s'échapper !!!", que disent vraiment ces articles ? Eh bien nous allons voir.
(lien dans la réponse)
Reposted by Camomille5000

Excited to announce ScanNet++ v2!🎉
@awhiteguitar.bsky.social & Yueh-Cheng Liu have been working tirelessly to bring:
🔹1006 high-fidelity 3D scans
🔹+ DSLR & iPhone captures
🔹+ rich semantics
Elevating 3D scene understanding to the next level!🚀
w/ @niessner.bsky.social
kaldir.vc.in.tum.de/scannetpp
@awhiteguitar.bsky.social & Yueh-Cheng Liu have been working tirelessly to bring:
🔹1006 high-fidelity 3D scans
🔹+ DSLR & iPhone captures
🔹+ rich semantics
Elevating 3D scene understanding to the next level!🚀
w/ @niessner.bsky.social
kaldir.vc.in.tum.de/scannetpp
December 20, 2024 at 3:02 PM
Excited to announce ScanNet++ v2!🎉
@awhiteguitar.bsky.social & Yueh-Cheng Liu have been working tirelessly to bring:
🔹1006 high-fidelity 3D scans
🔹+ DSLR & iPhone captures
🔹+ rich semantics
Elevating 3D scene understanding to the next level!🚀
w/ @niessner.bsky.social
kaldir.vc.in.tum.de/scannetpp
@awhiteguitar.bsky.social & Yueh-Cheng Liu have been working tirelessly to bring:
🔹1006 high-fidelity 3D scans
🔹+ DSLR & iPhone captures
🔹+ rich semantics
Elevating 3D scene understanding to the next level!🚀
w/ @niessner.bsky.social
kaldir.vc.in.tum.de/scannetpp
Reposted by Camomille5000

Mon setup d'attaque en boîte noire détaillé ici : mathishammel.com/share/Advers...
mathishammel.com
December 19, 2024 at 2:49 PM
Mon setup d'attaque en boîte noire détaillé ici : mathishammel.com/share/Advers...
Reposted by Camomille5000

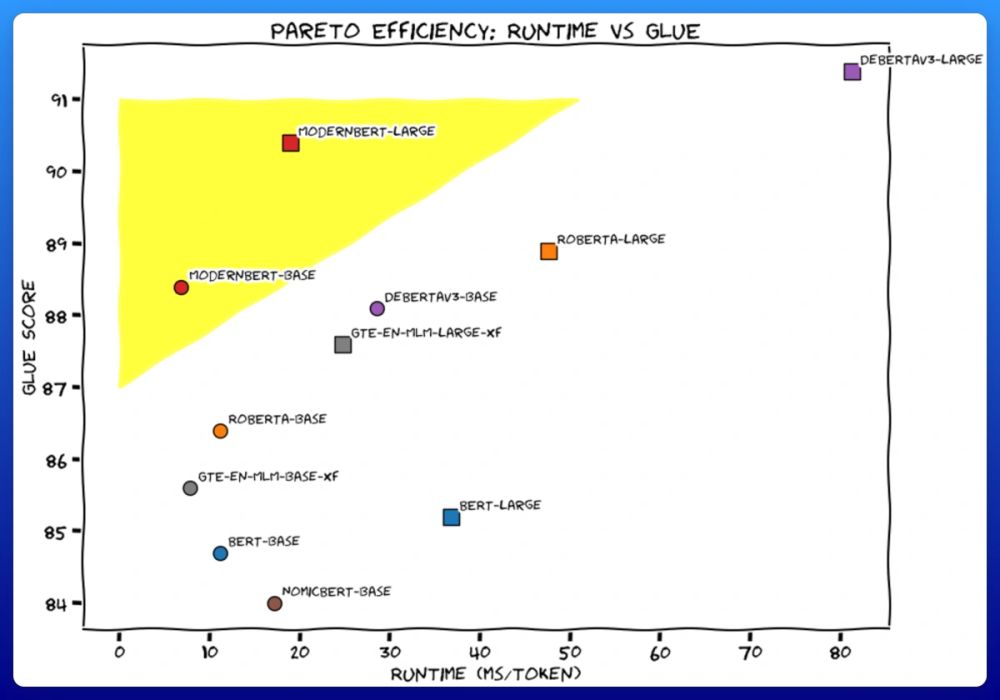
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
December 19, 2024 at 4:45 PM
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
Reposted by Camomille5000

Libraries and tools that every deep learning project should use: loguru, tqdm, torchmetrics, einops, python 3.11, black. Optional: prettytable. Good for debugging: lovely_tensors. Any other ones I've missed?
Below a few words on each of them:
Below a few words on each of them:

December 18, 2024 at 5:40 AM
Libraries and tools that every deep learning project should use: loguru, tqdm, torchmetrics, einops, python 3.11, black. Optional: prettytable. Good for debugging: lovely_tensors. Any other ones I've missed?
Below a few words on each of them:
Below a few words on each of them:
Reposted by Camomille5000

(1/2)
📢📢𝐆𝐀𝐅: 𝐆𝐚𝐮𝐬𝐬𝐢𝐚𝐧 𝐀𝐯𝐚𝐭𝐚𝐫 𝐑𝐞𝐜𝐨𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐟𝐫𝐨𝐦 𝐌𝐨𝐧𝐨𝐜𝐮𝐥𝐚𝐫 𝐕𝐢𝐝𝐞𝐨𝐬 𝐯𝐢𝐚 𝐌𝐮𝐥𝐭𝐢-𝐯𝐢𝐞𝐰 𝐃𝐢𝐟𝐟𝐮𝐬𝐢𝐨𝐧📢📢
We reconstruct animatable Gaussian head avatars from monocular videos captured by commodity devices such as smartphones.
📢📢𝐆𝐀𝐅: 𝐆𝐚𝐮𝐬𝐬𝐢𝐚𝐧 𝐀𝐯𝐚𝐭𝐚𝐫 𝐑𝐞𝐜𝐨𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐟𝐫𝐨𝐦 𝐌𝐨𝐧𝐨𝐜𝐮𝐥𝐚𝐫 𝐕𝐢𝐝𝐞𝐨𝐬 𝐯𝐢𝐚 𝐌𝐮𝐥𝐭𝐢-𝐯𝐢𝐞𝐰 𝐃𝐢𝐟𝐟𝐮𝐬𝐢𝐨𝐧📢📢
We reconstruct animatable Gaussian head avatars from monocular videos captured by commodity devices such as smartphones.
December 17, 2024 at 1:00 PM
(1/2)
📢📢𝐆𝐀𝐅: 𝐆𝐚𝐮𝐬𝐬𝐢𝐚𝐧 𝐀𝐯𝐚𝐭𝐚𝐫 𝐑𝐞𝐜𝐨𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐟𝐫𝐨𝐦 𝐌𝐨𝐧𝐨𝐜𝐮𝐥𝐚𝐫 𝐕𝐢𝐝𝐞𝐨𝐬 𝐯𝐢𝐚 𝐌𝐮𝐥𝐭𝐢-𝐯𝐢𝐞𝐰 𝐃𝐢𝐟𝐟𝐮𝐬𝐢𝐨𝐧📢📢
We reconstruct animatable Gaussian head avatars from monocular videos captured by commodity devices such as smartphones.
📢📢𝐆𝐀𝐅: 𝐆𝐚𝐮𝐬𝐬𝐢𝐚𝐧 𝐀𝐯𝐚𝐭𝐚𝐫 𝐑𝐞𝐜𝐨𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐟𝐫𝐨𝐦 𝐌𝐨𝐧𝐨𝐜𝐮𝐥𝐚𝐫 𝐕𝐢𝐝𝐞𝐨𝐬 𝐯𝐢𝐚 𝐌𝐮𝐥𝐭𝐢-𝐯𝐢𝐞𝐰 𝐃𝐢𝐟𝐟𝐮𝐬𝐢𝐨𝐧📢📢
We reconstruct animatable Gaussian head avatars from monocular videos captured by commodity devices such as smartphones.
Reposted by Camomille5000

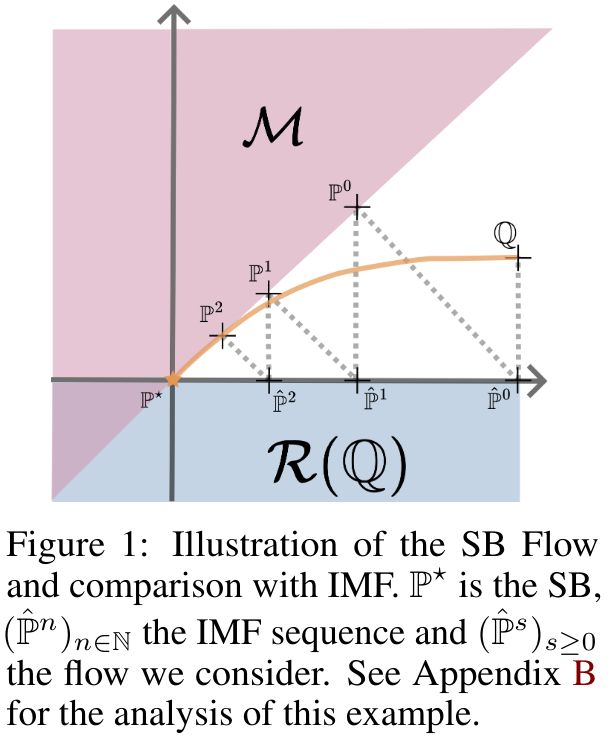
Schrödinger Bridge Flow for Unpaired Data Translation (by @vdebortoli.bsky.social et al.)
It will take me some time to digest this article fully, but it's important to follow the authors' advice and read the appendices, as the examples are helpful and well-illustrated.
📄 arxiv.org/abs/2409.09347
It will take me some time to digest this article fully, but it's important to follow the authors' advice and read the appendices, as the examples are helpful and well-illustrated.
📄 arxiv.org/abs/2409.09347

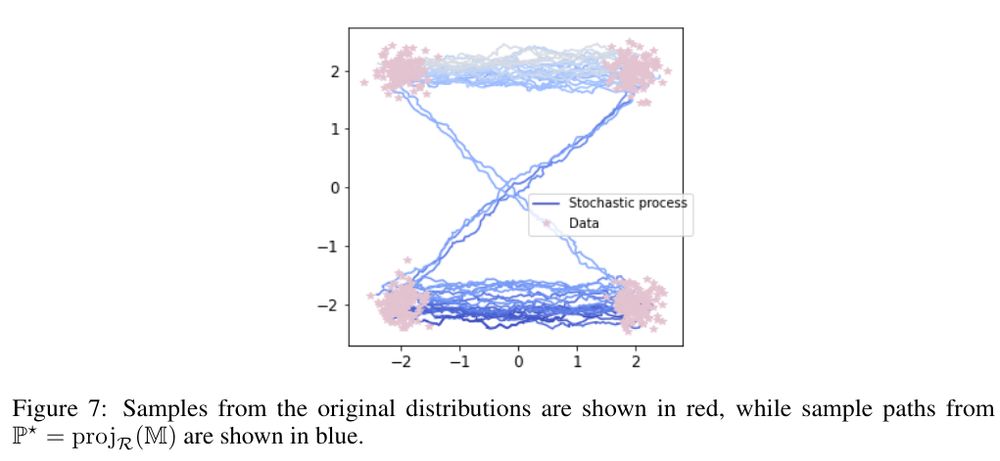
December 17, 2024 at 4:53 PM
Schrödinger Bridge Flow for Unpaired Data Translation (by @vdebortoli.bsky.social et al.)
It will take me some time to digest this article fully, but it's important to follow the authors' advice and read the appendices, as the examples are helpful and well-illustrated.
📄 arxiv.org/abs/2409.09347
It will take me some time to digest this article fully, but it's important to follow the authors' advice and read the appendices, as the examples are helpful and well-illustrated.
📄 arxiv.org/abs/2409.09347
Reposted by Camomille5000
The code for Simplified and Generalized Masked Diffusion for Discrete Data (Jiaxin Shi et al) has been released and a lecture by @arnauddoucet.bsky.social on this topic is also available!
🐍 Code: github.com/google-deepm...
📄 Article: arxiv.org/abs/2406.04329
📼 Video: www.youtube.com/watch?v=qj9B...
🐍 Code: github.com/google-deepm...
📄 Article: arxiv.org/abs/2406.04329
📼 Video: www.youtube.com/watch?v=qj9B...



December 14, 2024 at 12:47 PM
The code for Simplified and Generalized Masked Diffusion for Discrete Data (Jiaxin Shi et al) has been released and a lecture by @arnauddoucet.bsky.social on this topic is also available!
🐍 Code: github.com/google-deepm...
📄 Article: arxiv.org/abs/2406.04329
📼 Video: www.youtube.com/watch?v=qj9B...
🐍 Code: github.com/google-deepm...
📄 Article: arxiv.org/abs/2406.04329
📼 Video: www.youtube.com/watch?v=qj9B...
Reposted by Camomille5000

3D content creation with touch!
We exploit tactile sensing to enhance geometric details for text- and image-to-3D generation.
Check out our #NeurIPS2024 work on Tactile DreamFusion: Exploiting Tactile Sensing for 3D Generation: ruihangao.github.io/TactileDream...
1/3
We exploit tactile sensing to enhance geometric details for text- and image-to-3D generation.
Check out our #NeurIPS2024 work on Tactile DreamFusion: Exploiting Tactile Sensing for 3D Generation: ruihangao.github.io/TactileDream...
1/3
December 11, 2024 at 9:08 AM
3D content creation with touch!
We exploit tactile sensing to enhance geometric details for text- and image-to-3D generation.
Check out our #NeurIPS2024 work on Tactile DreamFusion: Exploiting Tactile Sensing for 3D Generation: ruihangao.github.io/TactileDream...
1/3
We exploit tactile sensing to enhance geometric details for text- and image-to-3D generation.
Check out our #NeurIPS2024 work on Tactile DreamFusion: Exploiting Tactile Sensing for 3D Generation: ruihangao.github.io/TactileDream...
1/3
Reposted by Camomille5000



December 11, 2024 at 12:37 AM
Reposted by Camomille5000
(1/n) My favorite "optimizer" work of 2024:
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
December 10, 2024 at 12:53 PM
(1/n) My favorite "optimizer" work of 2024:
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
📢 Introducing APOLLO! 🚀: SGD-like memory cost, yet AdamW-level performance (or better!).
❓ How much memory do we need for optimization states in LLM training ? 🧐
Almost zero.
📜 Paper: arxiv.org/abs/2412.05270
🔗 GitHub: github.com/zhuhanqing/A...
Reposted by Camomille5000
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329

Normalizing Flows are Capable Generative Models
Normalizing Flows (NFs) are likelihood-based models for continuous inputs.
They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relati...
arxiv.org
December 10, 2024 at 8:06 AM
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Reposted by Camomille5000
📢 𝐏𝐫𝐄𝐝𝐢𝐭𝐨𝐫𝟑𝐃: 𝐅𝐚𝐬𝐭 𝐚𝐧𝐝 𝐏𝐫𝐞𝐜𝐢𝐬𝐞 𝟑𝐃 𝐒𝐡𝐚𝐩𝐞 𝐄𝐝𝐢𝐭𝐢𝐧𝐠 📢
We propose a training-free 3D shape editing approach that rapidly and precisely edits the regions intended by the user and keeps the rest as is.
We propose a training-free 3D shape editing approach that rapidly and precisely edits the regions intended by the user and keeps the rest as is.
December 10, 2024 at 1:06 PM
📢 𝐏𝐫𝐄𝐝𝐢𝐭𝐨𝐫𝟑𝐃: 𝐅𝐚𝐬𝐭 𝐚𝐧𝐝 𝐏𝐫𝐞𝐜𝐢𝐬𝐞 𝟑𝐃 𝐒𝐡𝐚𝐩𝐞 𝐄𝐝𝐢𝐭𝐢𝐧𝐠 📢
We propose a training-free 3D shape editing approach that rapidly and precisely edits the regions intended by the user and keeps the rest as is.
We propose a training-free 3D shape editing approach that rapidly and precisely edits the regions intended by the user and keeps the rest as is.
Reposted by Camomille5000
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264

December 10, 2024 at 8:35 AM
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Reposted by Camomille5000

What better time to announce a new paper than during NeurIPS and ACCV?
happy happy happy to introduce NADA, our latest work on object detection in art! 🎨
with amazing collaborators:
@patrick-ramos.bsky.social, @nicaogr.bsky.social, Selina Khan, Yuta Nakashima
happy happy happy to introduce NADA, our latest work on object detection in art! 🎨
with amazing collaborators:
@patrick-ramos.bsky.social, @nicaogr.bsky.social, Selina Khan, Yuta Nakashima
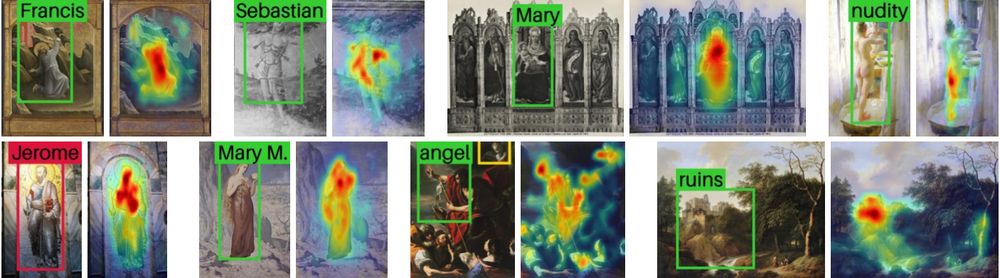
December 10, 2024 at 8:08 AM
What better time to announce a new paper than during NeurIPS and ACCV?
happy happy happy to introduce NADA, our latest work on object detection in art! 🎨
with amazing collaborators:
@patrick-ramos.bsky.social, @nicaogr.bsky.social, Selina Khan, Yuta Nakashima
happy happy happy to introduce NADA, our latest work on object detection in art! 🎨
with amazing collaborators:
@patrick-ramos.bsky.social, @nicaogr.bsky.social, Selina Khan, Yuta Nakashima