



"How NOT To Program
an Out-of-order Vector
Processor" slides are public.
static.sched.com/hosted_files...
an Out-of-order Vector
Processor" slides are public.
static.sched.com/hosted_files...




October 23, 2025 at 10:51 AM
"How NOT To Program
an Out-of-order Vector
Processor" slides are public.
static.sched.com/hosted_files...
an Out-of-order Vector
Processor" slides are public.
static.sched.com/hosted_files...
Fuzzing tip: use VLA instead of fixed-size buffers or malloc
1. with fixed-size buffers asan won't catch everything.
2. VLAs are faster than malloc, in my case I get 15% faster fuzzing.
If VLAs aren't portable enough, just check __STDC_NO_VLA__ and select between the other options.
1. with fixed-size buffers asan won't catch everything.
2. VLAs are faster than malloc, in my case I get 15% faster fuzzing.
If VLAs aren't portable enough, just check __STDC_NO_VLA__ and select between the other options.
October 12, 2025 at 9:45 AM
Fuzzing tip: use VLA instead of fixed-size buffers or malloc
1. with fixed-size buffers asan won't catch everything.
2. VLAs are faster than malloc, in my case I get 15% faster fuzzing.
If VLAs aren't portable enough, just check __STDC_NO_VLA__ and select between the other options.
1. with fixed-size buffers asan won't catch everything.
2. VLAs are faster than malloc, in my case I get 15% faster fuzzing.
If VLAs aren't portable enough, just check __STDC_NO_VLA__ and select between the other options.
Tenstorrent decided to publish the first benchmark data for Ascalon's RVV implementation using the instruction throughput benchmark of my rvv-bench benchmark suite. <3
camel-cdr.github.io/rvv-bench-re...
Overall, the results look really good so far:
camel-cdr.github.io/rvv-bench-re...
Overall, the results look really good so far:

September 25, 2025 at 5:49 PM
Tenstorrent decided to publish the first benchmark data for Ascalon's RVV implementation using the instruction throughput benchmark of my rvv-bench benchmark suite. <3
camel-cdr.github.io/rvv-bench-re...
Overall, the results look really good so far:
camel-cdr.github.io/rvv-bench-re...
Overall, the results look really good so far:
Reposted

So if you are currently involved with ISA-level decisions about inclusion of any pext/pdep-like instructions:
Please consider including SAG/inverse-SAG with bit-reversal of the goats.
No matter which of the two implementation methods you are using: All you need to do is not mask the goat bits.
Please consider including SAG/inverse-SAG with bit-reversal of the goats.
No matter which of the two implementation methods you are using: All you need to do is not mask the goat bits.
July 25, 2025 at 11:30 PM
So if you are currently involved with ISA-level decisions about inclusion of any pext/pdep-like instructions:
Please consider including SAG/inverse-SAG with bit-reversal of the goats.
No matter which of the two implementation methods you are using: All you need to do is not mask the goat bits.
Please consider including SAG/inverse-SAG with bit-reversal of the goats.
No matter which of the two implementation methods you are using: All you need to do is not mask the goat bits.
TIL about Trace Cache: www.realworldtech.com/forum/?threa... (thread on Apples Trace Cache)
Ventanas Veyron V2/V3 seem to also use something like a trace cache.
Ventanas Veyron V2/V3 seem to also use something like a trace cache.
RWT Forums - Real World Tech
content overridden
www.realworldtech.com
July 11, 2025 at 8:59 PM
TIL about Trace Cache: www.realworldtech.com/forum/?threa... (thread on Apples Trace Cache)
Ventanas Veyron V2/V3 seem to also use something like a trace cache.
Ventanas Veyron V2/V3 seem to also use something like a trace cache.
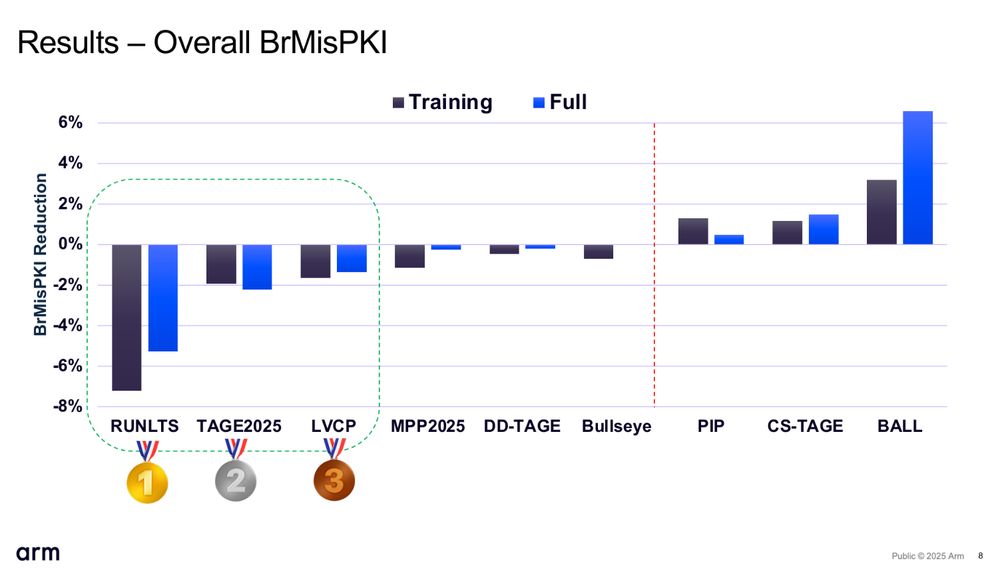
The sixth Championship of Branch Prediction (CBP2025) happened a week ago: ericrotenberg.wordpress.ncsu.edu/cbp2025-work...
June 28, 2025 at 6:36 AM
The sixth Championship of Branch Prediction (CBP2025) happened a week ago: ericrotenberg.wordpress.ncsu.edu/cbp2025-work...
Reposted
I wrote a reference implementation for a SAG without bit reflection: github.com/clairexen/ed..., and I wrote a parametric SAG core for any bit width: github.com/clairexen/ed...
edu-sag/param.v at main · clairexen/edu-sag
Educational 8-Bit Sheep-And-Goats (SAG) Verilog Reference IP - clairexen/edu-sag
github.com
June 20, 2025 at 4:04 PM
I wrote a reference implementation for a SAG without bit reflection: github.com/clairexen/ed..., and I wrote a parametric SAG core for any bit width: github.com/clairexen/ed...
SiFive X280 RVV benchmarks: camel-cdr.github.io/rvv-bench-re...
Civil was so nice run my RVV benchmark on the SiFive X280 cores on the Tenstorrent Blackhole.
Civil was so nice run my RVV benchmark on the SiFive X280 cores on the Tenstorrent Blackhole.
RVV benchmark SiFive X280
camel-cdr.github.io
June 6, 2025 at 10:57 PM
SiFive X280 RVV benchmarks: camel-cdr.github.io/rvv-bench-re...
Civil was so nice run my RVV benchmark on the SiFive X280 cores on the Tenstorrent Blackhole.
Civil was so nice run my RVV benchmark on the SiFive X280 cores on the Tenstorrent Blackhole.
TIL you can't do forward compatible syscalls with inline assembly because the kernel can decide to clobber architectural state that was added after you wrote the code.
If you use svc with inline assembly, you have to explicitly clobber SVE registers.
Good luck doing this back in 2015 when you wrote
If you use svc with inline assembly, you have to explicitly clobber SVE registers.
Good luck doing this back in 2015 when you wrote
June 6, 2025 at 6:31 PM
TIL you can't do forward compatible syscalls with inline assembly because the kernel can decide to clobber architectural state that was added after you wrote the code.
If you use svc with inline assembly, you have to explicitly clobber SVE registers.
Good luck doing this back in 2015 when you wrote
If you use svc with inline assembly, you have to explicitly clobber SVE registers.
Good luck doing this back in 2015 when you wrote
@clairexen.bsky.social Hi Claire, we are trying to propose some of the dropped bitmanip instructions for RVV: lists.riscv.org/g/sig-vector...
Since you were deeply involved in the development of the bitmanip spec, I was wondering if you could answer some questions about your bextdep implementation.
Since you were deeply involved in the development of the bitmanip spec, I was wondering if you could answer some questions about your bextdep implementation.
[Proposal] Bit Compress & Bit Decompress Instructions for RVV
For Spark/Flink workloads in data centers, reading large-scale Parquet files is often a performance bottleneck. Therefore, adding support for these instructions can effectively fill this gap, ensuring RISC-V's competitiveness with other ISAs.
lists.riscv.org
June 3, 2025 at 4:15 PM
@clairexen.bsky.social Hi Claire, we are trying to propose some of the dropped bitmanip instructions for RVV: lists.riscv.org/g/sig-vector...
Since you were deeply involved in the development of the bitmanip spec, I was wondering if you could answer some questions about your bextdep implementation.
Since you were deeply involved in the development of the bitmanip spec, I was wondering if you could answer some questions about your bextdep implementation.
oh no
> When source and destination registers overlap and have different EEW, the instruction is mask- and tail-agnostic, regardless of the setting of the vta and vma bits in vtype.
> When source and destination registers overlap and have different EEW, the instruction is mask- and tail-agnostic, regardless of the setting of the vta and vma bits in vtype.

May 26, 2025 at 9:39 PM
oh no
> When source and destination registers overlap and have different EEW, the instruction is mask- and tail-agnostic, regardless of the setting of the vta and vma bits in vtype.
> When source and destination registers overlap and have different EEW, the instruction is mask- and tail-agnostic, regardless of the setting of the vta and vma bits in vtype.
"Efficient Implementation of RISC-V Vector Permutation Instructions" -- arxiv.org/abs/2505.07112
"Efficient Architecture for RISC-V Vector Memory Access" -- arxiv.org/abs/2504.08334
I love how these two were released so close to each other.
"Efficient Architecture for RISC-V Vector Memory Access" -- arxiv.org/abs/2504.08334
I love how these two were released so close to each other.
May 13, 2025 at 8:17 PM
"Efficient Implementation of RISC-V Vector Permutation Instructions" -- arxiv.org/abs/2505.07112
"Efficient Architecture for RISC-V Vector Memory Access" -- arxiv.org/abs/2504.08334
I love how these two were released so close to each other.
"Efficient Architecture for RISC-V Vector Memory Access" -- arxiv.org/abs/2504.08334
I love how these two were released so close to each other.

I recently learned that the godbolt executor for Arm has Neoverse V1 cores, with 256-bit SVE.
Here is a SVE vs NEON benchmark with 1/2/4x unrolled for each: godbolt.org/z/47T9oaf97
SVE is faster across the board, with the fastest SVE version being about 30% faster than the fastest NEON version.
Here is a SVE vs NEON benchmark with 1/2/4x unrolled for each: godbolt.org/z/47T9oaf97
SVE is faster across the board, with the fastest SVE version being about 30% faster than the fastest NEON version.

Compiler Explorer
Compiler Explorer is an interactive online compiler which shows the assembly output of compiled C++, Rust, Go (and many more) code.
godbolt.org
April 28, 2025 at 9:08 PM
I recently learned that the godbolt executor for Arm has Neoverse V1 cores, with 256-bit SVE.
Here is a SVE vs NEON benchmark with 1/2/4x unrolled for each: godbolt.org/z/47T9oaf97
SVE is faster across the board, with the fastest SVE version being about 30% faster than the fastest NEON version.
Here is a SVE vs NEON benchmark with 1/2/4x unrolled for each: godbolt.org/z/47T9oaf97
SVE is faster across the board, with the fastest SVE version being about 30% faster than the fastest NEON version.
Reposted

Hello you fine Internet folks,
Today's article is on Alibaba/T-Head's Xuantie C910 core which has in part been open sourced and is T-Head's first out of order core.
Hope y'all enjoy!
open.substack.com/pub/chipsand...
old.chipsandcheese.com/2025/02/03/a...
Today's article is on Alibaba/T-Head's Xuantie C910 core which has in part been open sourced and is T-Head's first out of order core.
Hope y'all enjoy!
open.substack.com/pub/chipsand...
old.chipsandcheese.com/2025/02/03/a...

Alibaba/T-HEAD's Xuantie C910
T-HEAD is a wholly owned subsidiary of Alibaba, one of China's largest tech companies.
open.substack.com
February 4, 2025 at 5:36 AM
Hello you fine Internet folks,
Today's article is on Alibaba/T-Head's Xuantie C910 core which has in part been open sourced and is T-Head's first out of order core.
Hope y'all enjoy!
open.substack.com/pub/chipsand...
old.chipsandcheese.com/2025/02/03/a...
Today's article is on Alibaba/T-Head's Xuantie C910 core which has in part been open sourced and is T-Head's first out of order core.
Hope y'all enjoy!
open.substack.com/pub/chipsand...
old.chipsandcheese.com/2025/02/03/a...
"Using the Ziggurat Method for Sampling Random Coordinates From a Unit Circle"
gist.github.com/camel-cdr/d1...
I got inspired yesterday, after I saw the article "When Greedy Algorithms Can Be Faster" (16bpp.net/blog/post/wh...)
It ended up about 2x faster then the simple rejection sampling.
gist.github.com/camel-cdr/d1...
I got inspired yesterday, after I saw the article "When Greedy Algorithms Can Be Faster" (16bpp.net/blog/post/wh...)
It ended up about 2x faster then the simple rejection sampling.

Using the Ziggurat Method for Sampling Random Coordinates From a Unit Circle
Using the Ziggurat Method for Sampling Random Coordinates From a Unit Circle - dist_circle.h
gist.github.com
February 1, 2025 at 8:59 PM
"Using the Ziggurat Method for Sampling Random Coordinates From a Unit Circle"
gist.github.com/camel-cdr/d1...
I got inspired yesterday, after I saw the article "When Greedy Algorithms Can Be Faster" (16bpp.net/blog/post/wh...)
It ended up about 2x faster then the simple rejection sampling.
gist.github.com/camel-cdr/d1...
I got inspired yesterday, after I saw the article "When Greedy Algorithms Can Be Faster" (16bpp.net/blog/post/wh...)
It ended up about 2x faster then the simple rejection sampling.
Reposted

Some neat tricks for computing bit-wise prefix-or and segmented-prefix-or within scalar registers.

December 29, 2024 at 1:57 AM
Some neat tricks for computing bit-wise prefix-or and segmented-prefix-or within scalar registers.
Reposted
I've taken a look at the problem: github.com/natmaurice/s...
(code on master branch also handle quotes)
The segmented scan is done in scalar/SWP to avoid inter-lane overheads.
I've tested it, but not benchmarked it yet.
(code on master branch also handle quotes)
The segmented scan is done in scalar/SWP to avoid inter-lane overheads.
I've tested it, but not benchmarked it yet.

GitHub - natmaurice/simd-comment at comment-simple
Contribute to natmaurice/simd-comment development by creating an account on GitHub.
github.com
December 27, 2024 at 11:30 PM
I've taken a look at the problem: github.com/natmaurice/s...
(code on master branch also handle quotes)
The segmented scan is done in scalar/SWP to avoid inter-lane overheads.
I've tested it, but not benchmarked it yet.
(code on master branch also handle quotes)
The segmented scan is done in scalar/SWP to avoid inter-lane overheads.
I've tested it, but not benchmarked it yet.
Removing single line comments in multiple lines in parallel with RVV.
If anyone has a good AVX512 solution, please share.
Inspired by this reddit post: www.reddit.com/r/simd/comme...
#RVV #RISC-V #SIMD
If anyone has a good AVX512 solution, please share.
Inspired by this reddit post: www.reddit.com/r/simd/comme...
#RVV #RISC-V #SIMD

December 27, 2024 at 1:19 AM
Removing single line comments in multiple lines in parallel with RVV.
If anyone has a good AVX512 solution, please share.
Inspired by this reddit post: www.reddit.com/r/simd/comme...
#RVV #RISC-V #SIMD
If anyone has a good AVX512 solution, please share.
Inspired by this reddit post: www.reddit.com/r/simd/comme...
#RVV #RISC-V #SIMD
For my fellow GFNI fans. Here is Knuth introducing the MMIX instruction MXOR, which Intel later defined on vector registers under the name vgf2p8affineqb.
www.youtube.com/watch?v=r_pP... (55:00)
www.youtube.com/watch?v=r_pP... (55:00)
www.youtube.com
December 14, 2024 at 6:56 PM
For my fellow GFNI fans. Here is Knuth introducing the MMIX instruction MXOR, which Intel later defined on vector registers under the name vgf2p8affineqb.
www.youtube.com/watch?v=r_pP... (55:00)
www.youtube.com/watch?v=r_pP... (55:00)
Reposted
There's been a lot of discourse on fixed-length SIMD (e.g. SSE, AVX512, NEON) vs variable-length/vector (SVE, RVV) ISAs.
It's probably too early for a definite answer. But as I've designed SIMD image processing algorithms, I'll share a few results.
It's probably too early for a definite answer. But as I've designed SIMD image processing algorithms, I'll share a few results.
December 6, 2024 at 1:48 AM
There's been a lot of discourse on fixed-length SIMD (e.g. SSE, AVX512, NEON) vs variable-length/vector (SVE, RVV) ISAs.
It's probably too early for a definite answer. But as I've designed SIMD image processing algorithms, I'll share a few results.
It's probably too early for a definite answer. But as I've designed SIMD image processing algorithms, I'll share a few results.
rvv-bench now has RSS feeds: camel-cdr.github.io/rvv-bench-re...
New articles feed: camel-cdr.github.io/rvv-bench-re...
Benchmark updates feed: camel-cdr.github.io/rvv-bench-re...
New articles feed: camel-cdr.github.io/rvv-bench-re...
Benchmark updates feed: camel-cdr.github.io/rvv-bench-re...
December 5, 2024 at 8:27 PM
rvv-bench now has RSS feeds: camel-cdr.github.io/rvv-bench-re...
New articles feed: camel-cdr.github.io/rvv-bench-re...
Benchmark updates feed: camel-cdr.github.io/rvv-bench-re...
New articles feed: camel-cdr.github.io/rvv-bench-re...
Benchmark updates feed: camel-cdr.github.io/rvv-bench-re...
Here are some slightly tricky RVV mask patterns.

December 3, 2024 at 9:37 PM
Here are some slightly tricky RVV mask patterns.