




Ben Miller
@bkmi.bsky.social
FAIR Chemistry. Simulation-based Inference.
This was a significant community effort, so thank you to LBNL, Princeton, Genentech, Stanford, U. of Cambridge, CMU, NYU, LANL, the Roche Group and Berkeley for helping make this happen!
May 14, 2025 at 6:13 PM
This was a significant community effort, so thank you to LBNL, Princeton, Genentech, Stanford, U. of Cambridge, CMU, NYU, LANL, the Roche Group and Berkeley for helping make this happen!
UMA, without fine-tuning to specific tasks, performs similarly or better in both accuracy and inference-speed/memory-efficiency than specialized models on a wide-range of material, molecular and catalysis benchmarks.

May 14, 2025 at 6:13 PM
UMA, without fine-tuning to specific tasks, performs similarly or better in both accuracy and inference-speed/memory-efficiency than specialized models on a wide-range of material, molecular and catalysis benchmarks.
With all these large diverse datasets, we ask whether it’s possible to train a single model that performs well across several domains without the need for additional finetuning?
Introducing UMA - our latest model trained on over 30 billion atoms across our open-science datasets.
Introducing UMA - our latest model trained on over 30 billion atoms across our open-science datasets.

May 14, 2025 at 6:13 PM
With all these large diverse datasets, we ask whether it’s possible to train a single model that performs well across several domains without the need for additional finetuning?
Introducing UMA - our latest model trained on over 30 billion atoms across our open-science datasets.
Introducing UMA - our latest model trained on over 30 billion atoms across our open-science datasets.
Baseline models are released and evaluated on OOD evaluation tasks. Metrics that go beyond just a structure’s energy and forces are important for understanding how well models perform on downstream applications.
We hope to release a public leaderboard in the near future!
We hope to release a public leaderboard in the near future!

May 14, 2025 at 6:13 PM
Baseline models are released and evaluated on OOD evaluation tasks. Metrics that go beyond just a structure’s energy and forces are important for understanding how well models perform on downstream applications.
We hope to release a public leaderboard in the near future!
We hope to release a public leaderboard in the near future!
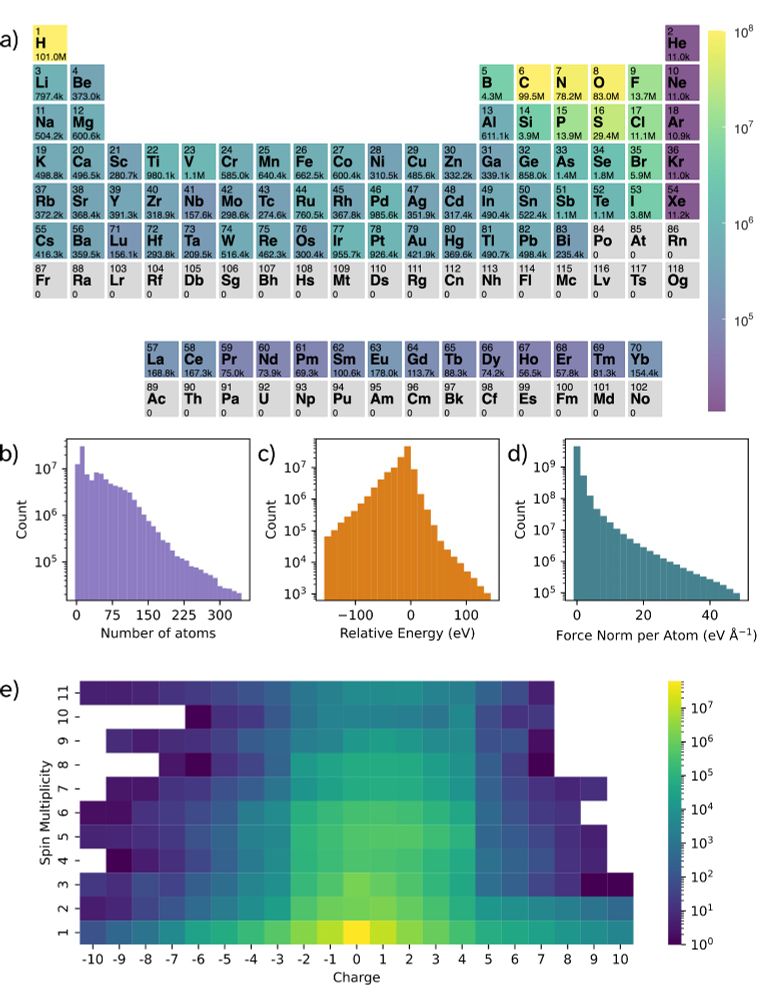
With over 100M structures calculated at ωB97M-V/def2-TZVPD, with variable charge+spin, and spanning biomolecules, electrolytes, metal complexes, and community datasets, OMol25 represents the largest most diverse dataset of its kind.
May 14, 2025 at 6:13 PM
With over 100M structures calculated at ωB97M-V/def2-TZVPD, with variable charge+spin, and spanning biomolecules, electrolytes, metal complexes, and community datasets, OMol25 represents the largest most diverse dataset of its kind.
While our earlier datasets (OC20, OC22, OMat24) focused on catalysts and materials, it was evident the community lacked a large, high quality, diverse molecular DFT dataset for training ML models. The Open Molecules 2025 (OMol25) Dataset hopes to accomplish just that.

May 14, 2025 at 6:13 PM
While our earlier datasets (OC20, OC22, OMat24) focused on catalysts and materials, it was evident the community lacked a large, high quality, diverse molecular DFT dataset for training ML models. The Open Molecules 2025 (OMol25) Dataset hopes to accomplish just that.
Doesn't the timing of this not make sense?
February 2, 2025 at 8:11 AM
Doesn't the timing of this not make sense?