



Benjamin Wee
@bennywee.bsky.social
I like statistics, programming and reproducible workflows. Mostly Bayesian stats, #Rstats, #Python
🌐 bennywee.github.io
🌐 bennywee.github.io
Used to do problem sets but now sometimes do brief summaries of chapters in a reading group (learning is best with other people I find!)
bsky.app/profile/benn...
bsky.app/profile/benn...
I can summarise how I learn things with a single comic, especially as a new parent:
Source: www.facebook.com/webcomicname...
Source: www.facebook.com/webcomicname...
December 15, 2024 at 11:30 PM
Used to do problem sets but now sometimes do brief summaries of chapters in a reading group (learning is best with other people I find!)
bsky.app/profile/benn...
bsky.app/profile/benn...
1. Is hard to do with less time (lin algebra was during lockdown)
2. Is fine but less problem solving ➡️ weaker learning outcomes
I think I learn best with 2. when engaging and talking with other people. So I just have a discord server now where I summarise textbook chapters for ad-hoc discussion
2. Is fine but less problem solving ➡️ weaker learning outcomes
I think I learn best with 2. when engaging and talking with other people. So I just have a discord server now where I summarise textbook chapters for ad-hoc discussion
December 15, 2024 at 11:26 PM
1. Is hard to do with less time (lin algebra was during lockdown)
2. Is fine but less problem solving ➡️ weaker learning outcomes
I think I learn best with 2. when engaging and talking with other people. So I just have a discord server now where I summarise textbook chapters for ad-hoc discussion
2. Is fine but less problem solving ➡️ weaker learning outcomes
I think I learn best with 2. when engaging and talking with other people. So I just have a discord server now where I summarise textbook chapters for ad-hoc discussion
I've done it Stan! Very convenient and the docs are very informative. Just use default HMC and sidestep the Kalman filter step (although I think you can still use the KF if you need it!)
December 7, 2024 at 8:35 AM
I've done it Stan! Very convenient and the docs are very informative. Just use default HMC and sidestep the Kalman filter step (although I think you can still use the KF if you need it!)
Any examples of lessons learned? I've worked with SS time series on some volatility models but not much else.
December 6, 2024 at 10:12 PM
Any examples of lessons learned? I've worked with SS time series on some volatility models but not much else.
I omitted many details in this thread, but this hopefully gives a good overview of my research. Referenced papers can be found here.
Talts et al (2020): arxiv.org/abs/1804.06788
Kim et al (1998): apps.olin.wustl.edu/faculty/chib...
/end 🧵
Talts et al (2020): arxiv.org/abs/1804.06788
Kim et al (1998): apps.olin.wustl.edu/faculty/chib...
/end 🧵

Validating Bayesian Inference Algorithms with Simulation-Based Calibration
Verifying the correctness of Bayesian computation is challenging. This is especially true for complex models that are common in practice, as these require sophisticated model implementations and algor...
arxiv.org
December 2, 2024 at 7:10 AM
I omitted many details in this thread, but this hopefully gives a good overview of my research. Referenced papers can be found here.
Talts et al (2020): arxiv.org/abs/1804.06788
Kim et al (1998): apps.olin.wustl.edu/faculty/chib...
/end 🧵
Talts et al (2020): arxiv.org/abs/1804.06788
Kim et al (1998): apps.olin.wustl.edu/faculty/chib...
/end 🧵
Overall my research suggests that Stan's default HMC produces the most calibrated estimates, although model parameterisation plays an important role. There are also limitations again on what is a "fair" comparison (e.g. diff number of posterior samples).
December 2, 2024 at 7:10 AM
Overall my research suggests that Stan's default HMC produces the most calibrated estimates, although model parameterisation plays an important role. There are also limitations again on what is a "fair" comparison (e.g. diff number of posterior samples).
5000 SBC simulations were performed for each experiment. Stan's algo used 999 post warmup posterior samples whereas Kim et al's used 9,999 (diff due to concerns around convergence). The original number of draws (~750k) for Kim et al's algorithm was not done due to constraints.
December 2, 2024 at 7:10 AM
5000 SBC simulations were performed for each experiment. Stan's algo used 999 post warmup posterior samples whereas Kim et al's used 9,999 (diff due to concerns around convergence). The original number of draws (~750k) for Kim et al's algorithm was not done due to constraints.
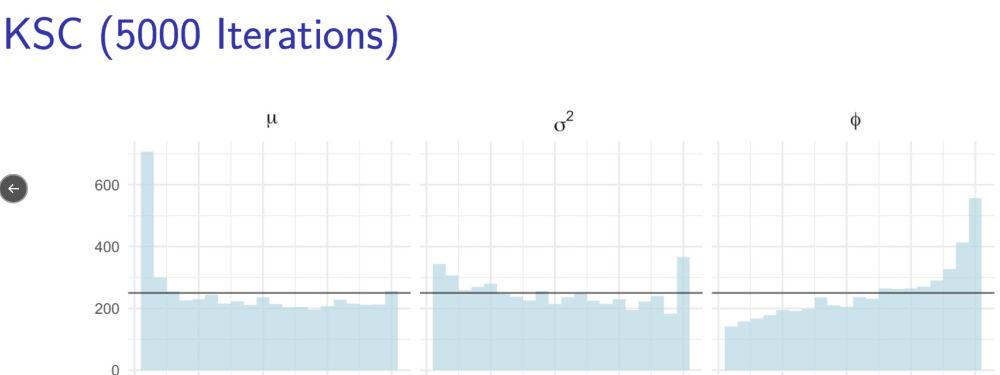
The best SBC results for Stan's algorithm uses a uncentered parameterisation of SV. The rank stats appear uniform across all static parameters. Kim et al's bespoke algorithm performed best on a centered SV. But their rank statistics are less uniform and therefore less calibrated.

December 2, 2024 at 7:10 AM
The best SBC results for Stan's algorithm uses a uncentered parameterisation of SV. The rank stats appear uniform across all static parameters. Kim et al's bespoke algorithm performed best on a centered SV. But their rank statistics are less uniform and therefore less calibrated.
SV is expressed as a state space model - there is a latent conditional variance to be estimated for each data point (which means k parameters > n observations). For brevity I'll show the SBC results for only the static parameters (mu, phi, sigma).

December 2, 2024 at 7:10 AM
SV is expressed as a state space model - there is a latent conditional variance to be estimated for each data point (which means k parameters > n observations). For brevity I'll show the SBC results for only the static parameters (mu, phi, sigma).
My research applies SBC on a vanilla SV model using @mcmc_stan's default Hamiltonian Monte Carlo (no U-turn sampler) and Kim et al's estimation strategy using conjugate priors, MH within Gibbs and the Kalman Filter (under both centered and uncentered parameterisations of the SV).
December 2, 2024 at 7:10 AM
My research applies SBC on a vanilla SV model using @mcmc_stan's default Hamiltonian Monte Carlo (no U-turn sampler) and Kim et al's estimation strategy using conjugate priors, MH within Gibbs and the Kalman Filter (under both centered and uncentered parameterisations of the SV).
Talts et al (2020) prove the rank statistics from a calibrated analysis is uniformly distributed. If rank statistics has a large left peak, then the avg posterior is overestimating the prior. Two peaks on either side suggests under dispersion relative to the prior.


December 2, 2024 at 7:10 AM
Talts et al (2020) prove the rank statistics from a calibrated analysis is uniformly distributed. If rank statistics has a large left peak, then the avg posterior is overestimating the prior. Two peaks on either side suggests under dispersion relative to the prior.
The true parameter in SBC is a sample from the prior dist. Calibration also implies the posterior averaged over the data and true parameters equals the prior. Therefore, if MCMC is calibrated, rank stats should be uniform which implies the avg posterior equals the prior.

December 2, 2024 at 7:10 AM
The true parameter in SBC is a sample from the prior dist. Calibration also implies the posterior averaged over the data and true parameters equals the prior. Therefore, if MCMC is calibrated, rank stats should be uniform which implies the avg posterior equals the prior.
SBC runs many simulations and checks if the rank statistics (definition in slides) of each parameter follow a uniform distribution. A calibrated analysis means that the correct posterior estimate is returned _on average_ over these simulations.


December 2, 2024 at 7:10 AM
SBC runs many simulations and checks if the rank statistics (definition in slides) of each parameter follow a uniform distribution. A calibrated analysis means that the correct posterior estimate is returned _on average_ over these simulations.
In this example, I know my code and analysis is correct. A single simulation may conclude a correctly coded analysis is a failure. So what can we do instead? It turns out we can understand algorithmic inference better when we run the simulation multiple times. Enter SBC.
December 2, 2024 at 7:10 AM
In this example, I know my code and analysis is correct. A single simulation may conclude a correctly coded analysis is a failure. So what can we do instead? It turns out we can understand algorithmic inference better when we run the simulation multiple times. Enter SBC.
This is a good check that the model and code is working as expected. However, results form a single simulation are insufficient. There is a small chance the true parameter (solid vertical line) exists in the tails of the marginal posterior distribution (phi).

December 2, 2024 at 7:10 AM
This is a good check that the model and code is working as expected. However, results form a single simulation are insufficient. There is a small chance the true parameter (solid vertical line) exists in the tails of the marginal posterior distribution (phi).
An important step in Bayesian workflow is validating computation. A way to do this is to simulate data from a model with known parameters and checking if MCMC can recover the true values. If this fails, we can't be certain the analysis will return reliable inference on real data.
December 2, 2024 at 7:10 AM
An important step in Bayesian workflow is validating computation. A way to do this is to simulate data from a model with known parameters and checking if MCMC can recover the true values. If this fails, we can't be certain the analysis will return reliable inference on real data.
First and forecast, a big shout out to Prof Catherine Forbes and Dr Lauren Kennedy who jointly supervised my research. I had the best time working with them and learned _so_ much from their mentorship. I'll always be grateful for the time they invested in me.
December 2, 2024 at 7:10 AM
First and forecast, a big shout out to Prof Catherine Forbes and Dr Lauren Kennedy who jointly supervised my research. I had the best time working with them and learned _so_ much from their mentorship. I'll always be grateful for the time they invested in me.
Reading with whatever free time I can get together is basically all I can handle.
November 28, 2024 at 11:31 PM
Reading with whatever free time I can get together is basically all I can handle.