




Benjamin Gagl
@benjamingagl.bsky.social
Assistant Professor for Self Learning Systems @UniCologne
#Reading #NeuroCognition #ComputationalModels
https://selflearningsystems.uni-koeln.de/
#Reading #NeuroCognition #ComputationalModels
https://selflearningsystems.uni-koeln.de/

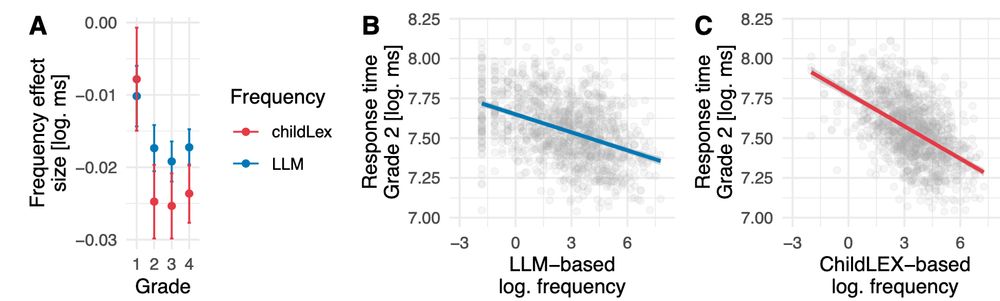
Inspecting the size of the word frequency effect, we found a smaller estimate for LLM- compared to the book-based frequency, potentially indicating an overestimation in that age range. Also, the effect size was comparable between kids and adults when comparing the best-fitting frequency measures.
December 4, 2024 at 1:19 PM
Inspecting the size of the word frequency effect, we found a smaller estimate for LLM- compared to the book-based frequency, potentially indicating an overestimation in that age range. Also, the effect size was comparable between kids and adults when comparing the best-fitting frequency measures.
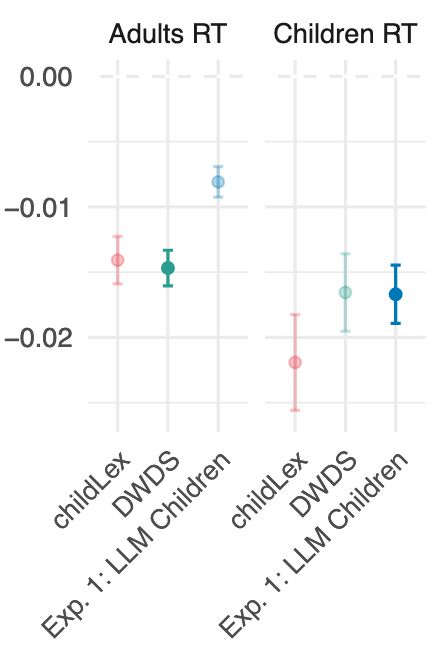
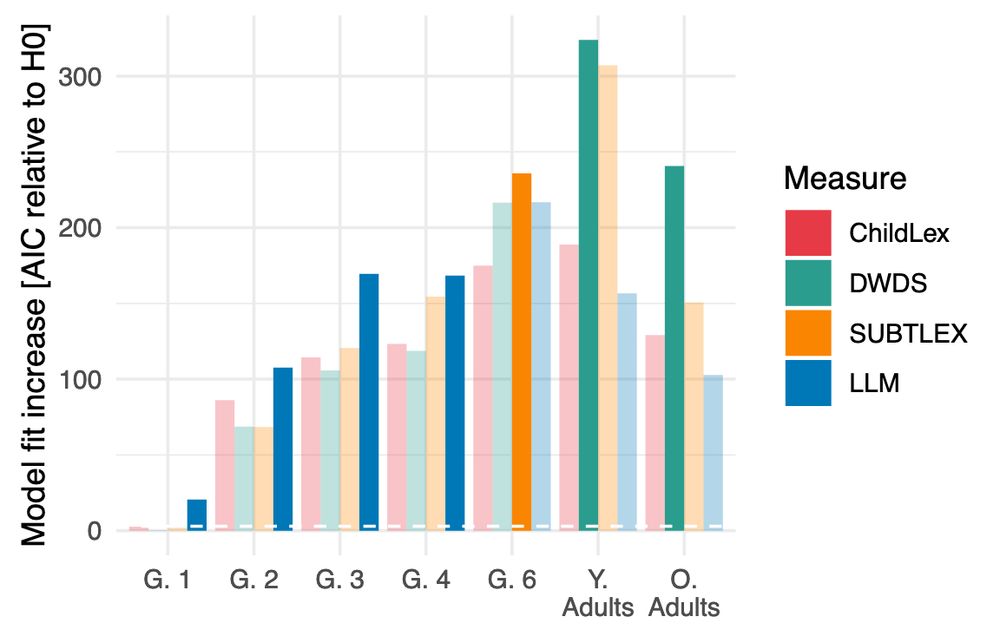
When estimating the word frequency effect on reading performance, we find that the model fit is higher for the group for which we generated the corpus. So, LLM-generated text for children better explained the effect in young readers, and adult-generated text better explained the effect in adults.
December 4, 2024 at 1:19 PM
When estimating the word frequency effect on reading performance, we find that the model fit is higher for the group for which we generated the corpus. So, LLM-generated text for children better explained the effect in young readers, and adult-generated text better explained the effect in adults.
Still, the LLM-based word frequency measures are highly correlated with book-based measures

December 4, 2024 at 1:19 PM
Still, the LLM-based word frequency measures are highly correlated with book-based measures
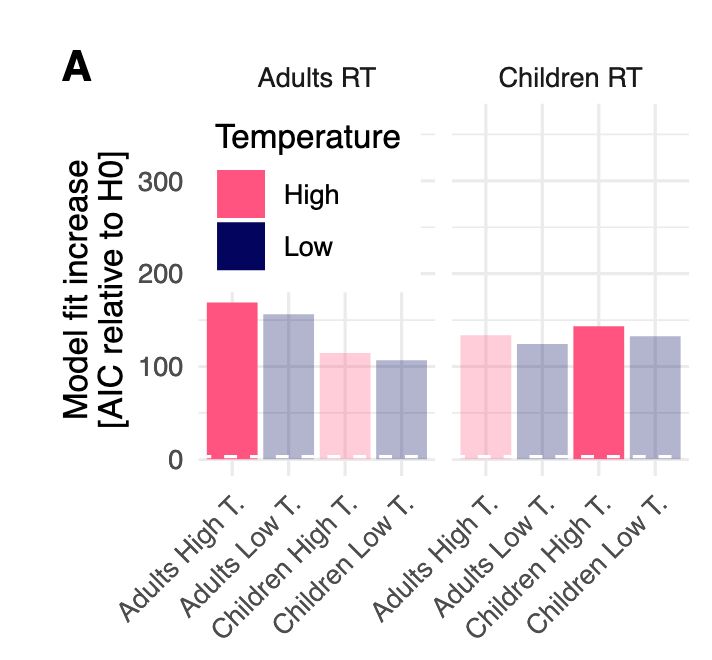
The study investigated whether a measure of word frequency based on text generated by a large language model (LLM) is suitable. Over multiple corpora, we found reduced lexical richness of the LLM corpus, which can be accounted for to some extent by increasing the LLM's temperature parameter.

December 4, 2024 at 1:19 PM
The study investigated whether a measure of word frequency based on text generated by a large language model (LLM) is suitable. Over multiple corpora, we found reduced lexical richness of the LLM corpus, which can be accounted for to some extent by increasing the LLM's temperature parameter.
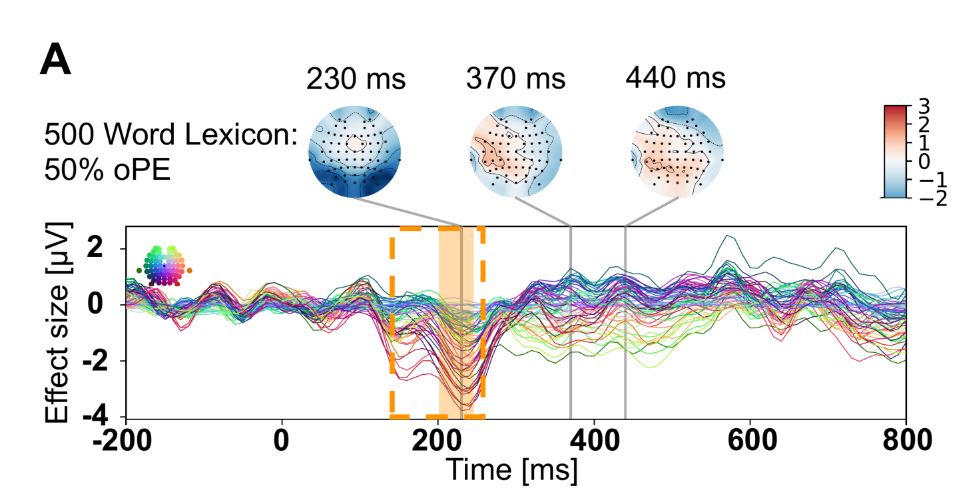
Early brain activation was better explained by less precise representations.
November 20, 2024 at 7:45 PM
Early brain activation was better explained by less precise representations.
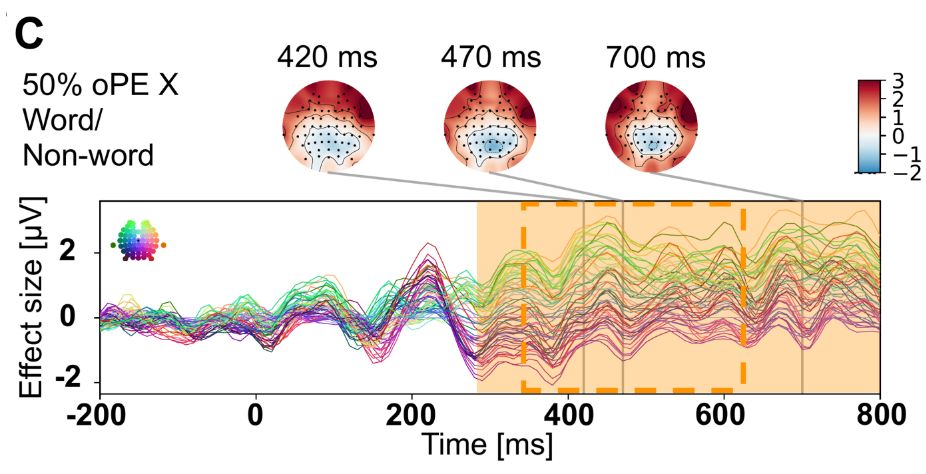
(ii) More realistic assumptions of the items in the long time storage of the model (i.e., the lexicon)
The central finding is that for late brain activation and behavior, a model with a representation that uses binary signals and memory storage fits with estimates of human vocabulary.
The central finding is that for late brain activation and behavior, a model with a representation that uses binary signals and memory storage fits with estimates of human vocabulary.
November 20, 2024 at 7:45 PM
(ii) More realistic assumptions of the items in the long time storage of the model (i.e., the lexicon)
The central finding is that for late brain activation and behavior, a model with a representation that uses binary signals and memory storage fits with estimates of human vocabulary.
The central finding is that for late brain activation and behavior, a model with a representation that uses binary signals and memory storage fits with estimates of human vocabulary.
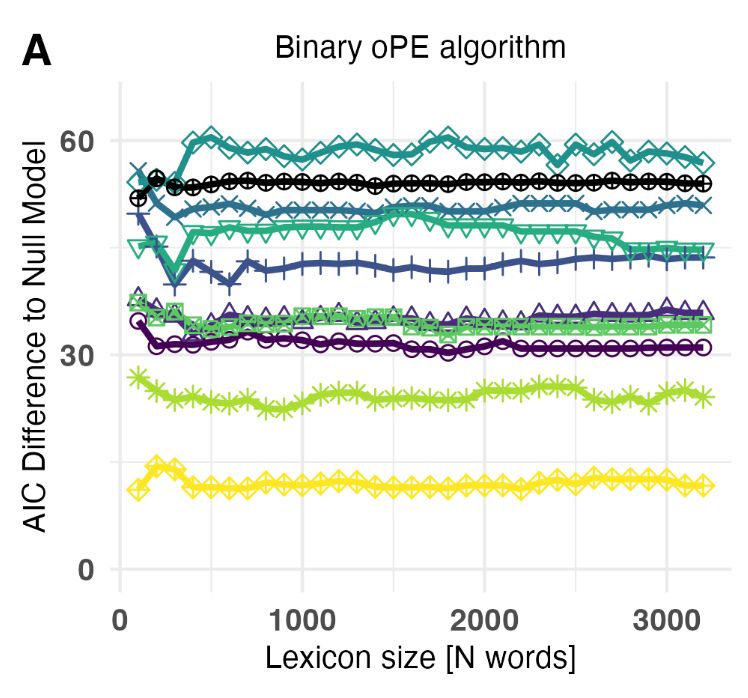
To test this, we use simple, transparent computational models implemented within a predictive coding framework that can be falsified ... and yes, we falsify a ton of models in that paper.
Within that framework, we test if the precision of the representation can be increased by
(i) Binary signals
Within that framework, we test if the precision of the representation can be increased by
(i) Binary signals

November 20, 2024 at 7:45 PM
To test this, we use simple, transparent computational models implemented within a predictive coding framework that can be falsified ... and yes, we falsify a ton of models in that paper.
Within that framework, we test if the precision of the representation can be increased by
(i) Binary signals
Within that framework, we test if the precision of the representation can be increased by
(i) Binary signals

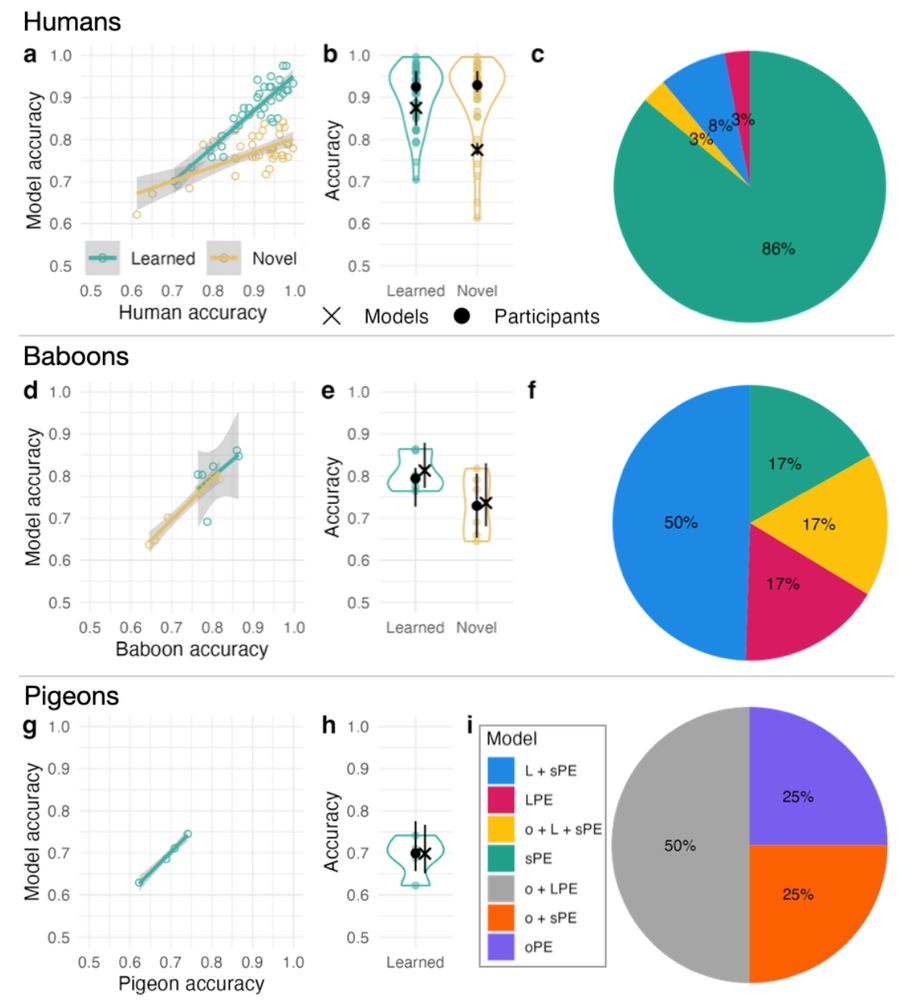
We find that humans and baboons use similar representations but with different quantities. In contrast, pigeons rely more heavily on the integration of representation based on pixel-level information.
June 27, 2024 at 7:20 AM
We find that humans and baboons use similar representations but with different quantities. In contrast, pigeons rely more heavily on the integration of representation based on pixel-level information.
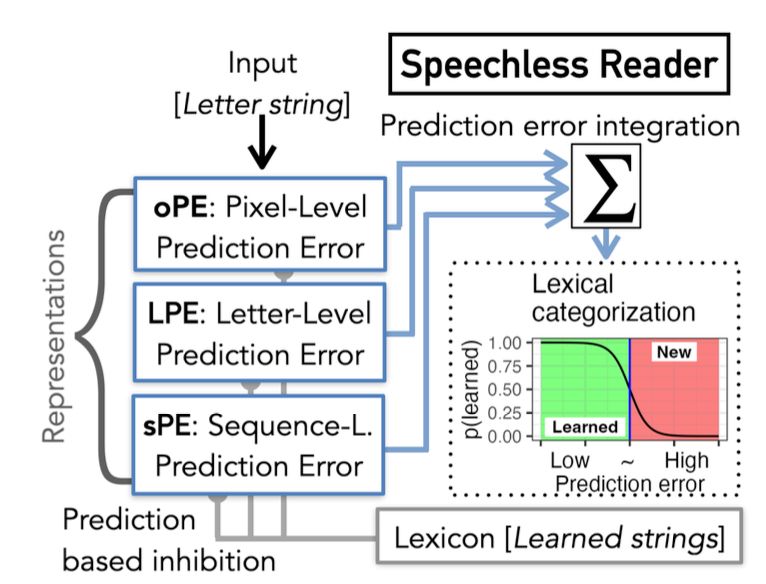
We use the speechless reader model, a transparent model of visual-orthographic processing based on the assumptions of predictive coding, to infer which representations are implemented in orthographic decisions.
June 27, 2024 at 7:19 AM
We use the speechless reader model, a transparent model of visual-orthographic processing based on the assumptions of predictive coding, to infer which representations are implemented in orthographic decisions.
🚨New Preprint🚨 We developed a new version of the orthographic prediction error (oPE) and found that the representation increases in precision over time. We found that the newly developed oPE representation better explained late EEG time windows and behavior. Also, allowed better ResNet18 performance

March 5, 2024 at 7:44 AM
🚨New Preprint🚨 We developed a new version of the orthographic prediction error (oPE) and found that the representation increases in precision over time. We found that the newly developed oPE representation better explained late EEG time windows and behavior. Also, allowed better ResNet18 performance