



Axel Brunnbauer
@axelbrunnbauer.bsky.social
Multi-Agent RL, PhD Student @ TUWien
This blog post is a nice complementary, behind-the-scenes extra on our recent work about on-policy pathwise gradient algorithms. @cvoelcker.bsky.social went the extra mile, and wrote this piece to provide some more context on the design decisions behind REPPO!
cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!

a close up of a sad cat with the words pleeeaasse written below it
ALT: a close up of a sad cat with the words pleeeaasse written below it
media.tenor.com
October 3, 2025 at 10:52 PM
This blog post is a nice complementary, behind-the-scenes extra on our recent work about on-policy pathwise gradient algorithms. @cvoelcker.bsky.social went the extra mile, and wrote this piece to provide some more context on the design decisions behind REPPO!
Reposted by Axel Brunnbauer

cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
a close up of a sad cat with the words pleeeaasse written below it
ALT: a close up of a sad cat with the words pleeeaasse written below it
media.tenor.com
October 2, 2025 at 9:34 PM
cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
Reposted by Axel Brunnbauer
Big if true 🤫: #REPPO works on Atari as well 😱 👾 🚀
Some tuning is still needed, but we are seeing results roughly on par with #PQN.
If you want to test out #REPPO (atari is not integrated due to issues with envpool and jax version), check out github.com/cvoelcker/re...
#reinforcementlearning
Some tuning is still needed, but we are seeing results roughly on par with #PQN.
If you want to test out #REPPO (atari is not integrated due to issues with envpool and jax version), check out github.com/cvoelcker/re...
#reinforcementlearning

September 16, 2025 at 1:29 PM
Big if true 🤫: #REPPO works on Atari as well 😱 👾 🚀
Some tuning is still needed, but we are seeing results roughly on par with #PQN.
If you want to test out #REPPO (atari is not integrated due to issues with envpool and jax version), check out github.com/cvoelcker/re...
#reinforcementlearning
Some tuning is still needed, but we are seeing results roughly on par with #PQN.
If you want to test out #REPPO (atari is not integrated due to issues with envpool and jax version), check out github.com/cvoelcker/re...
#reinforcementlearning
Reposted by Axel Brunnbauer

Super stoked for the New York RL workshop tomorrow. Will be presenting 2 orals:
* Replicable Reinforcement Learning with Linear Function Approximation
* Relative Entropy Pathwise Policy Optimization
We already posted about the 2nd one (below), I'll get to talking about the first one in a bit here.
* Replicable Reinforcement Learning with Linear Function Approximation
* Relative Entropy Pathwise Policy Optimization
We already posted about the 2nd one (below), I'll get to talking about the first one in a bit here.
September 11, 2025 at 2:28 PM
Super stoked for the New York RL workshop tomorrow. Will be presenting 2 orals:
* Replicable Reinforcement Learning with Linear Function Approximation
* Relative Entropy Pathwise Policy Optimization
We already posted about the 2nd one (below), I'll get to talking about the first one in a bit here.
* Replicable Reinforcement Learning with Linear Function Approximation
* Relative Entropy Pathwise Policy Optimization
We already posted about the 2nd one (below), I'll get to talking about the first one in a bit here.
Reposted by Axel Brunnbauer

I’ve been hearing about this paper from Claas for a while now, the fact that they aren’t tuning per benchmark is a killer sign. Also, check out the wall clock plots!
July 18, 2025 at 8:15 PM
I’ve been hearing about this paper from Claas for a while now, the fact that they aren’t tuning per benchmark is a killer sign. Also, check out the wall clock plots!
Reposted by Axel Brunnbauer
My PhD journey started with me fine-tuning hparams of PPO which ultimately led to my research on stability. With REPPO, we've made a huge step in the right direction. Stable learning, no tuning on a new benchmark, amazing performance. REPPO has the potential to be the PPO killer we all waited for.
July 17, 2025 at 7:41 PM
My PhD journey started with me fine-tuning hparams of PPO which ultimately led to my research on stability. With REPPO, we've made a huge step in the right direction. Stable learning, no tuning on a new benchmark, amazing performance. REPPO has the potential to be the PPO killer we all waited for.
Reposted by Axel Brunnbauer
🔥 Presenting Relative Entropy Pathwise Policy Optimization #REPPO 🔥
Off-policy #RL (eg #TD3) trains by differentiating a critic, while on-policy #RL (eg #PPO) uses Monte-Carlo gradients. But is that necessary? Turns out: No! We show how to get critic gradients on-policy. arxiv.org/abs/2507.11019
Off-policy #RL (eg #TD3) trains by differentiating a critic, while on-policy #RL (eg #PPO) uses Monte-Carlo gradients. But is that necessary? Turns out: No! We show how to get critic gradients on-policy. arxiv.org/abs/2507.11019
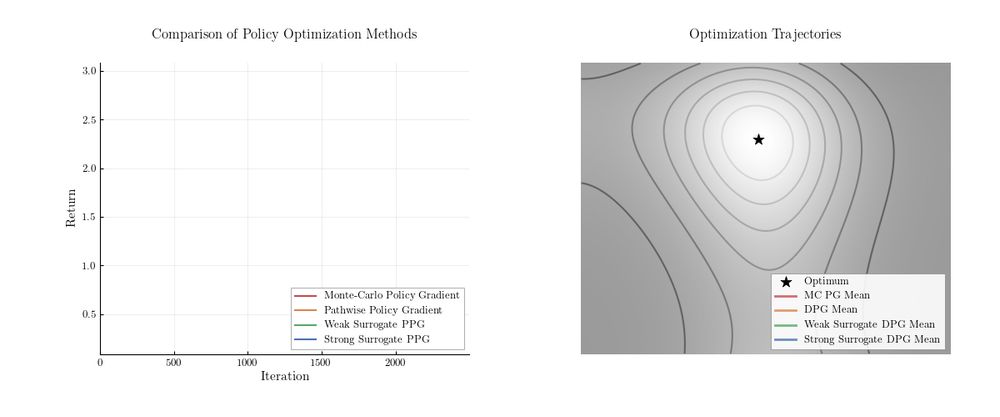
July 17, 2025 at 7:11 PM
Our paper on unsupervised environment design for autonomous-driving scenarios was accepted at ICRA! We built a curriculum generator for CARLA which adapts the scenario distribution to the current capabilities of the agent.
arxiv.org/abs/2403.17805
arxiv.org/abs/2403.17805

Scenario-Based Curriculum Generation for Multi-Agent Autonomous Driving
The automated generation of diverse and complex training scenarios has been an important ingredient in many complex learning tasks. Especially in real-world application domains, such as autonomous dri...
arxiv.org
February 11, 2025 at 10:18 AM
Our paper on unsupervised environment design for autonomous-driving scenarios was accepted at ICRA! We built a curriculum generator for CARLA which adapts the scenario distribution to the current capabilities of the agent.
arxiv.org/abs/2403.17805
arxiv.org/abs/2403.17805
Excited to announce that our paper "Scalable Offline Reinforcement Learning for Mean Field Games" has been accepted at #AAMAS2025! 🚀 We propose Off-MMD, an offline RL algorithm for learning equilibrium policies in MFGs from static datasets. arxiv.org/abs/2410.17898

Scalable Offline Reinforcement Learning for Mean Field Games
Reinforcement learning algorithms for mean-field games offer a scalable framework for optimizing policies in large populations of interacting agents. Existing methods often depend on online interactio...
arxiv.org
December 20, 2024 at 10:04 AM
Excited to announce that our paper "Scalable Offline Reinforcement Learning for Mean Field Games" has been accepted at #AAMAS2025! 🚀 We propose Off-MMD, an offline RL algorithm for learning equilibrium policies in MFGs from static datasets. arxiv.org/abs/2410.17898