



the whole point of RLVR is to force generalization from verifiable tasks to unverifiable ones in adjacent domains
the whole pass@k thing stops making sense if you don't have a trivial way to judge the correctness of an answer
the whole pass@k thing stops making sense if you don't have a trivial way to judge the correctness of an answer
November 11, 2025 at 4:35 PM
the whole point of RLVR is to force generalization from verifiable tasks to unverifiable ones in adjacent domains
the whole pass@k thing stops making sense if you don't have a trivial way to judge the correctness of an answer
the whole pass@k thing stops making sense if you don't have a trivial way to judge the correctness of an answer
I've never really understood this line of thinking, honestly. Definitionally the model can do anything with high enough pass@k - proofs for millenium prize questions can be generated by a 300M model given enough time.
November 11, 2025 at 4:33 PM
I've never really understood this line of thinking, honestly. Definitionally the model can do anything with high enough pass@k - proofs for millenium prize questions can be generated by a 300M model given enough time.
really sort of a neutral statement on unions themselves. they sure are organizations that pursue the interests of their members
November 10, 2025 at 2:55 AM
really sort of a neutral statement on unions themselves. they sure are organizations that pursue the interests of their members

last time like the other day
November 9, 2025 at 7:35 PM
last time like the other day
there are all of these weird little features that would be extremely charming in a game that wasn't Like That. you can actually play all of the instruments! the base building and decoration system is pretty nice! but everyone is forced to build minmaxxed fortresses that get wiped every two weeks
November 9, 2025 at 2:28 AM
there are all of these weird little features that would be extremely charming in a game that wasn't Like That. you can actually play all of the instruments! the base building and decoration system is pretty nice! but everyone is forced to build minmaxxed fortresses that get wiped every two weeks
the memory system is opaque and designed to create a model that is super overfamiliar towards you
combine that with OpenAI's aggressive integration of user feedback data and you get the most buddy-buddy model in the industry with persistent memory about your preferences. nightmare
combine that with OpenAI's aggressive integration of user feedback data and you get the most buddy-buddy model in the industry with persistent memory about your preferences. nightmare
November 8, 2025 at 8:56 PM
the memory system is opaque and designed to create a model that is super overfamiliar towards you
combine that with OpenAI's aggressive integration of user feedback data and you get the most buddy-buddy model in the industry with persistent memory about your preferences. nightmare
combine that with OpenAI's aggressive integration of user feedback data and you get the most buddy-buddy model in the industry with persistent memory about your preferences. nightmare
future devil would be having a field day in our world tbh
November 8, 2025 at 7:39 AM
future devil would be having a field day in our world tbh

The Future Devil (Chainsaw man Dub)
YouTube video by Ryuko Studios Animation
www.youtube.com
November 8, 2025 at 7:29 AM
for me, coming around on LLMs for learning and coding was less "i was wrong, these things are 100% accurate!" and more "wow, I really underestimated how many things are trivially fact-checkable but hard to surface"
November 6, 2025 at 9:20 AM
for me, coming around on LLMs for learning and coding was less "i was wrong, these things are 100% accurate!" and more "wow, I really underestimated how many things are trivially fact-checkable but hard to surface"
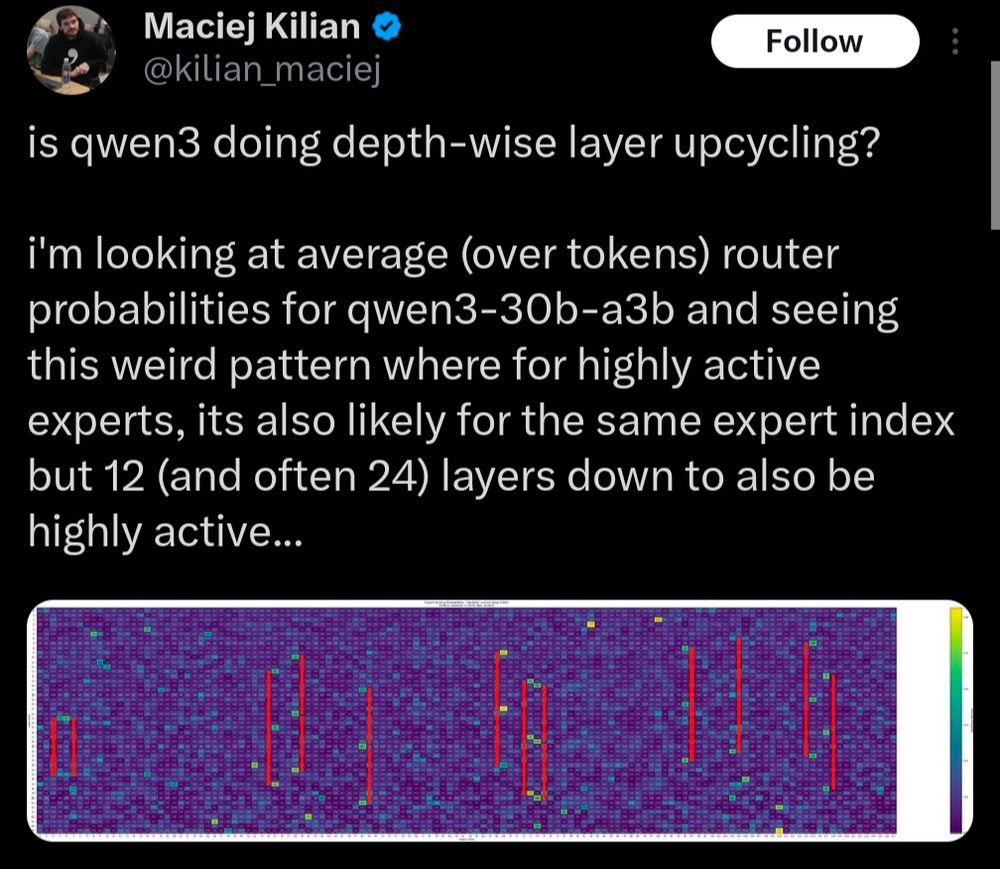
my guess is that Qwen3-30B was upscaled from the unreleased Qwen3-15B (confirmed to exist), healed with continued pretraining, and then post-trained
November 5, 2025 at 10:26 PM
my guess is that Qwen3-30B was upscaled from the unreleased Qwen3-15B (confirmed to exist), healed with continued pretraining, and then post-trained
I really have no clue, the way the Qwen team's obsessive optimization against benchmarks has manifested at larger scales is a sort of "stare into the abyss" situation for me
November 5, 2025 at 10:23 PM
I really have no clue, the way the Qwen team's obsessive optimization against benchmarks has manifested at larger scales is a sort of "stare into the abyss" situation for me
the 480B was exclusively released as an instruction-tuned "Qwen3-Coder" and the 1T model (proprietary, "Qwen3-Max") is so deeply fried that it does not know the difference between "kaomoji" and "emoji"
November 5, 2025 at 10:20 PM
the 480B was exclusively released as an instruction-tuned "Qwen3-Coder" and the 1T model (proprietary, "Qwen3-Max") is so deeply fried that it does not know the difference between "kaomoji" and "emoji"
no, they're weirdly coy about this
they produced a 235B, 480B, and then 1T model within a span of like 2 months though and there are some artifacts in the 30B
this is also the subject of enduring rumors which I have seen reasonably trustworthy people vouch for
they produced a 235B, 480B, and then 1T model within a span of like 2 months though and there are some artifacts in the 30B
this is also the subject of enduring rumors which I have seen reasonably trustworthy people vouch for
November 5, 2025 at 10:16 PM
no, they're weirdly coy about this
they produced a 235B, 480B, and then 1T model within a span of like 2 months though and there are some artifacts in the 30B
this is also the subject of enduring rumors which I have seen reasonably trustworthy people vouch for
they produced a 235B, 480B, and then 1T model within a span of like 2 months though and there are some artifacts in the 30B
this is also the subject of enduring rumors which I have seen reasonably trustworthy people vouch for
not really all that similar to this idea but weird that this works at all or that they consider this a good idea
November 5, 2025 at 10:01 PM
not really all that similar to this idea but weird that this works at all or that they consider this a good idea
Qwen does some weird layer-looped upcycling to make some models, especially Qwen3-Coder and Qwen3-Max
November 5, 2025 at 10:00 PM
Qwen does some weird layer-looped upcycling to make some models, especially Qwen3-Coder and Qwen3-Max
then again this process is so cheap that caching it in advance would seem wasteful - it's just two table lookups and some arithmetic
November 5, 2025 at 9:53 AM
then again this process is so cheap that caching it in advance would seem wasteful - it's just two table lookups and some arithmetic