



Atharva Kulkarni
@athrvkk.bsky.social
CS PhD at USC | Prev - CMU, Apple, IIIT Delhi | Robust, Generalizable, and Trustworthy NLP
https://athrvkk.github.io/
https://athrvkk.github.io/
🙌🥳Had great fun doing this during my summer internship with folks from Apple (Yuan Zhang, Joel Ruben Antony Moniz, Xiou Ge, Bo-Hsiang Tseng, Dhivya Piraviperumal, Hong Yu) and USC (@swabhs.bsky.social)
Looking forward to the feedback! 🙂
#LLMs #NLProc
(7/n)
Looking forward to the feedback! 🙂
#LLMs #NLProc
(7/n)
April 30, 2025 at 6:54 PM
🙌🥳Had great fun doing this during my summer internship with folks from Apple (Yuan Zhang, Joel Ruben Antony Moniz, Xiou Ge, Bo-Hsiang Tseng, Dhivya Piraviperumal, Hong Yu) and USC (@swabhs.bsky.social)
Looking forward to the feedback! 🙂
#LLMs #NLProc
(7/n)
Looking forward to the feedback! 🙂
#LLMs #NLProc
(7/n)
🚫Bottom line: There’s no single metric that captures hallucinations reliably across the board.
🎯Our work highlights the need for robust, context-aware, and generalizable hallucination detection tools as a prerequisite to meaningful mitigation.
(6/n)
🎯Our work highlights the need for robust, context-aware, and generalizable hallucination detection tools as a prerequisite to meaningful mitigation.
(6/n)
April 30, 2025 at 6:54 PM
🚫Bottom line: There’s no single metric that captures hallucinations reliably across the board.
🎯Our work highlights the need for robust, context-aware, and generalizable hallucination detection tools as a prerequisite to meaningful mitigation.
(6/n)
🎯Our work highlights the need for robust, context-aware, and generalizable hallucination detection tools as a prerequisite to meaningful mitigation.
(6/n)
✅What works better?
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)

April 30, 2025 at 6:54 PM
✅What works better?
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
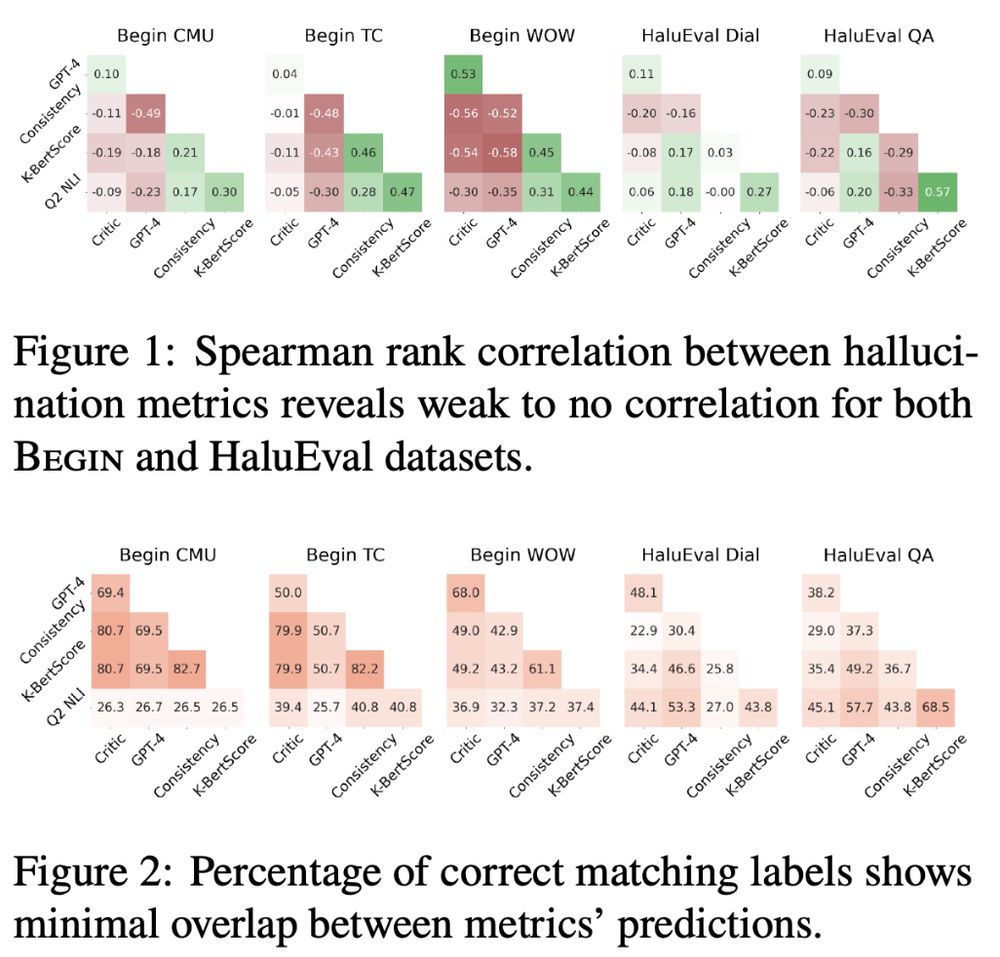
Our findings highlight:
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)

April 30, 2025 at 6:54 PM
Our findings highlight:
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
🧐Focusing on faithfulness and factuality errors in QA and dialogue tasks, we study diverse metrics spanning:
1. Syntactic and semantic similarity
2. Natural language inference
3. Multi-step question answering pipelines
4. Custom-trained models
5. SOTA LLMs as judge.
(3/n)
1. Syntactic and semantic similarity
2. Natural language inference
3. Multi-step question answering pipelines
4. Custom-trained models
5. SOTA LLMs as judge.
(3/n)
April 30, 2025 at 6:54 PM
🧐Focusing on faithfulness and factuality errors in QA and dialogue tasks, we study diverse metrics spanning:
1. Syntactic and semantic similarity
2. Natural language inference
3. Multi-step question answering pipelines
4. Custom-trained models
5. SOTA LLMs as judge.
(3/n)
1. Syntactic and semantic similarity
2. Natural language inference
3. Multi-step question answering pipelines
4. Custom-trained models
5. SOTA LLMs as judge.
(3/n)
🤔Despite a surge in research on hallucination mitigation, few ask the critical questions:
1. Are the metrics capturing the hallucinations effectively?
2. Do they align with each other and the human notion of hallucination?
3. Do they generalize across different settings?
(2/n)
1. Are the metrics capturing the hallucinations effectively?
2. Do they align with each other and the human notion of hallucination?
3. Do they generalize across different settings?
(2/n)
April 30, 2025 at 6:54 PM
🤔Despite a surge in research on hallucination mitigation, few ask the critical questions:
1. Are the metrics capturing the hallucinations effectively?
2. Do they align with each other and the human notion of hallucination?
3. Do they generalize across different settings?
(2/n)
1. Are the metrics capturing the hallucinations effectively?
2. Do they align with each other and the human notion of hallucination?
3. Do they generalize across different settings?
(2/n)
Hey John, thanks for starting this packet! Could you please add me as well?
November 18, 2024 at 6:09 PM
Hey John, thanks for starting this packet! Could you please add me as well?
Can you please add me to the pack! Looking forward to interacting with everyone!
November 15, 2024 at 6:59 AM
Can you please add me to the pack! Looking forward to interacting with everyone!
Great initiative!! Can you please add me! Looking forward to interacting with everyone!!💯
November 15, 2024 at 6:56 AM
Great initiative!! Can you please add me! Looking forward to interacting with everyone!!💯