



Atharva Kulkarni
@athrvkk.bsky.social
CS PhD at USC | Prev - CMU, Apple, IIIT Delhi | Robust, Generalizable, and Trustworthy NLP
https://athrvkk.github.io/
https://athrvkk.github.io/
✅What works better?
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)

April 30, 2025 at 6:54 PM
✅What works better?
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
Unsurprisingly, GPT4-based evaluators show the highest reliability with humans across settings 🌟
Using ensembles of multiple metrics is a promising avenue⭐️
Instruction tuning & mode-seeking decoding help reduce hallucinations📈
(5/n)
Our findings highlight:
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
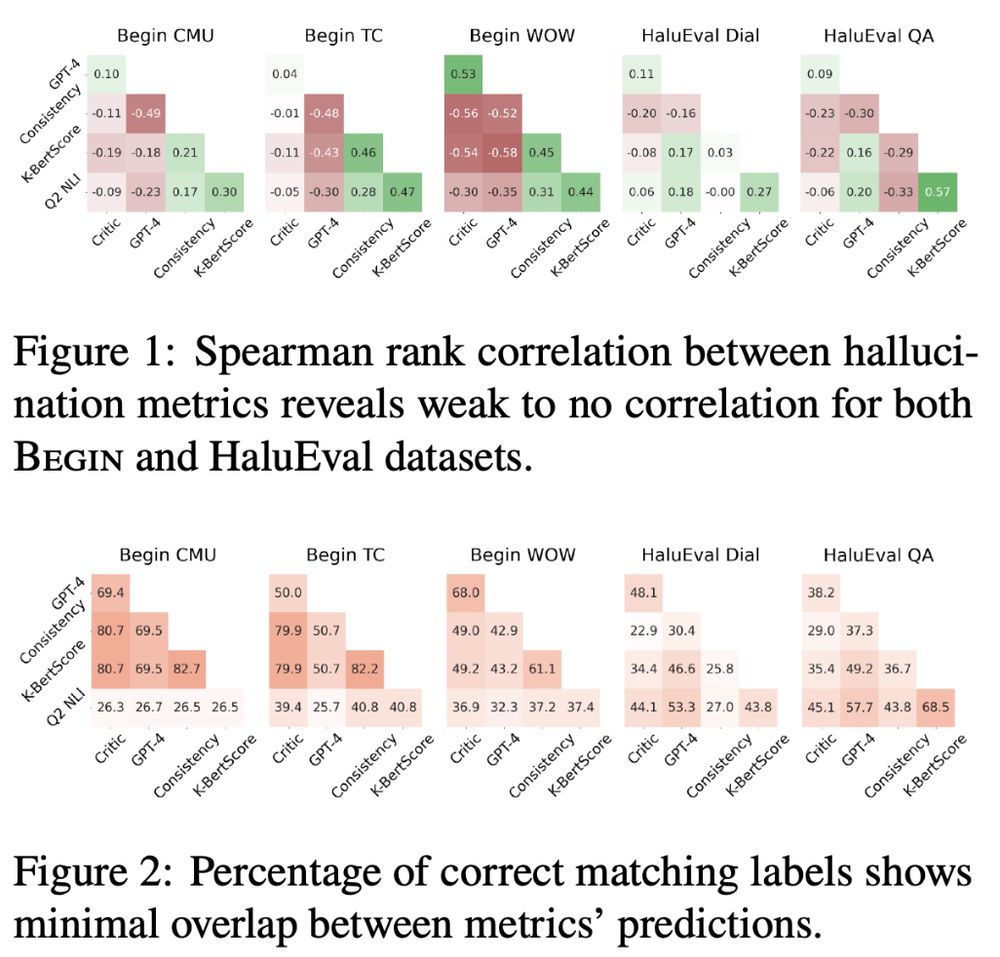
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)

April 30, 2025 at 6:54 PM
Our findings highlight:
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
⚠️Many existing metrics show poor alignment with human judgments
⚠️The inter-metric correlation is also weak
⚠️The show limited generalization across datasets, tasks, and models
⚠️They do not consistent improvement with larger models
(4/n)
Hallucinations in LLMs are real—and so are the problems with how we measure them 📉
Our latest work questions the generalizability of hallucination detection metrics across tasks, datasets, model sizes, training methods, and decoding strategies 💥
arxiv.org/abs/2504.18114
(1/n)
Our latest work questions the generalizability of hallucination detection metrics across tasks, datasets, model sizes, training methods, and decoding strategies 💥
arxiv.org/abs/2504.18114
(1/n)

April 30, 2025 at 6:54 PM
Hallucinations in LLMs are real—and so are the problems with how we measure them 📉
Our latest work questions the generalizability of hallucination detection metrics across tasks, datasets, model sizes, training methods, and decoding strategies 💥
arxiv.org/abs/2504.18114
(1/n)
Our latest work questions the generalizability of hallucination detection metrics across tasks, datasets, model sizes, training methods, and decoding strategies 💥
arxiv.org/abs/2504.18114
(1/n)