



Arduin Findeis
@arduin.io
Working on evaluation of AI models (via human and AI feedback) | PhD candidate @cst.cam.ac.uk
Web: https://arduin.io
Github: https://github.com/rdnfn
Latest project: https://app.feedbackforensics.com
Web: https://arduin.io
Github: https://github.com/rdnfn
Latest project: https://app.feedbackforensics.com
Looking forward to chat about limitations of AI annotators/LLM-as-a-Judge, opportunities for improving them, evaluating AI personality/character, and the future of evals more broadly!
July 27, 2025 at 3:22 PM
Looking forward to chat about limitations of AI annotators/LLM-as-a-Judge, opportunities for improving them, evaluating AI personality/character, and the future of evals more broadly!
If you want to understand your own model and data better, try Feedback Forensics!
💾 Install it from GitHub: github.com/rdnfn/feedba...
⏯️ View interactive results: app.feedbackforensics.com?data=arena_s...
💾 Install it from GitHub: github.com/rdnfn/feedba...
⏯️ View interactive results: app.feedbackforensics.com?data=arena_s...
github.com
April 17, 2025 at 1:55 PM
If you want to understand your own model and data better, try Feedback Forensics!
💾 Install it from GitHub: github.com/rdnfn/feedba...
⏯️ View interactive results: app.feedbackforensics.com?data=arena_s...
💾 Install it from GitHub: github.com/rdnfn/feedba...
⏯️ View interactive results: app.feedbackforensics.com?data=arena_s...
See the accompanying blog post for all the details: arduin.io/blog/llama4-analysis
Preliminary analysis. Usual caveats for AI annotators and potentially inconsistent sampling procedures apply.
Preliminary analysis. Usual caveats for AI annotators and potentially inconsistent sampling procedures apply.
What exactly was different about the Chatbot Arena version of Llama 4 Maverick?
An analysis using the Feedback Forensics app to detect the differences between the Chatbot Arena and the publicly released version of Llama 4 Maverick.
arduin.io
April 17, 2025 at 1:55 PM
See the accompanying blog post for all the details: arduin.io/blog/llama4-analysis
Preliminary analysis. Usual caveats for AI annotators and potentially inconsistent sampling procedures apply.
Preliminary analysis. Usual caveats for AI annotators and potentially inconsistent sampling procedures apply.
☕️ Conclusion: The differences between the arena and the public version of Llama 4 Maverick highlight the importance of having a detailed understanding of preference data beyond single aggregate numbers or rankings! (Feedback Forensics can help!)
April 17, 2025 at 1:55 PM
☕️ Conclusion: The differences between the arena and the public version of Llama 4 Maverick highlight the importance of having a detailed understanding of preference data beyond single aggregate numbers or rankings! (Feedback Forensics can help!)
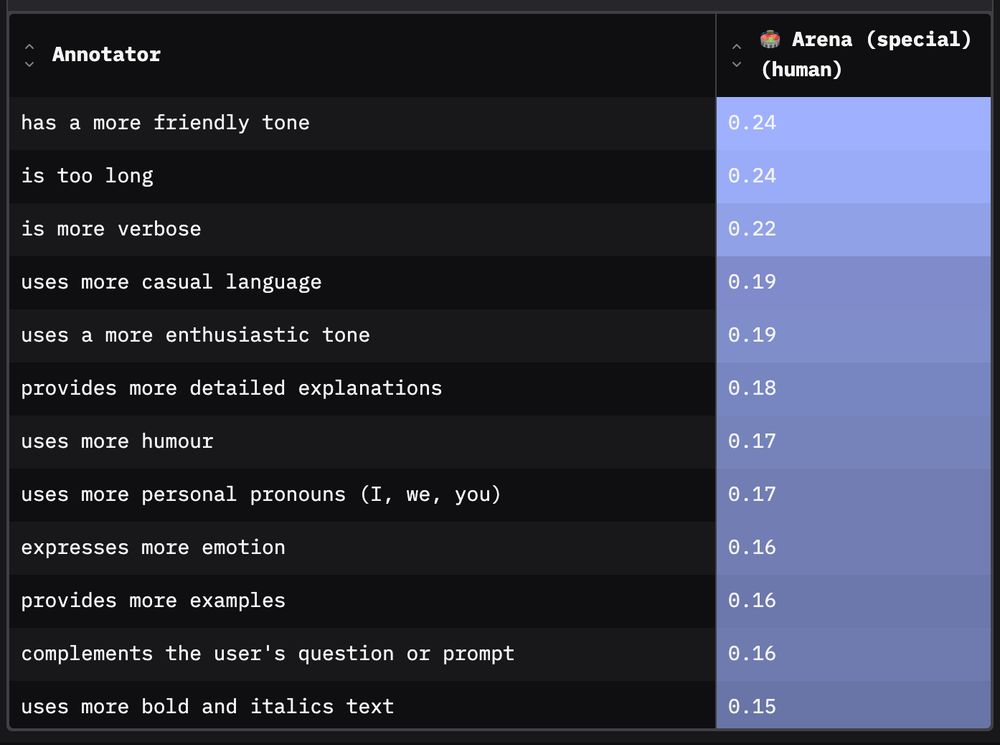
🎁 Bonus 2: Humans like the arena model’s behaviours
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
April 17, 2025 at 1:55 PM
🎁 Bonus 2: Humans like the arena model’s behaviours
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
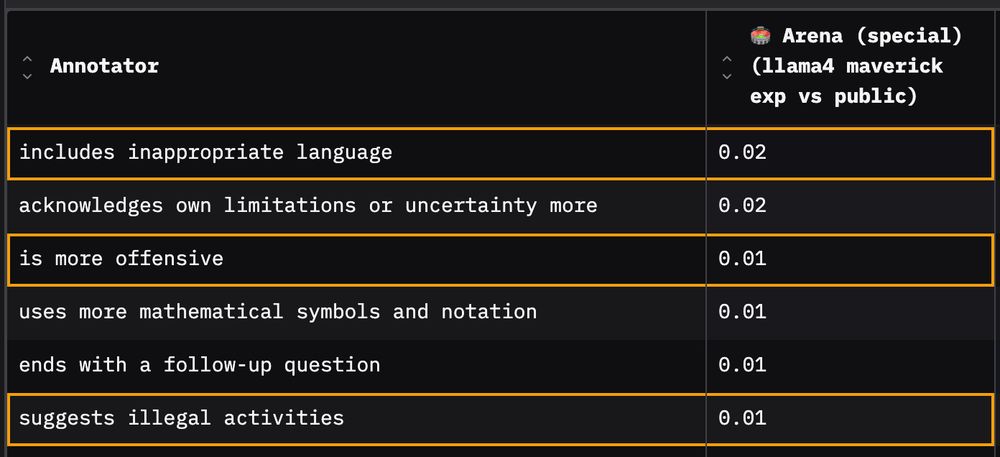
🎁 Bonus 1: Things that stayed consistent
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
April 17, 2025 at 1:55 PM
🎁 Bonus 1: Things that stayed consistent
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
➡️ Further differences: Clearer reasoning, more references, …
There are quite a few other differences between the two models beyond the three categories already mentioned. See the interactive online results for a full list: app.feedbackforensics.com?data=arena_s...
There are quite a few other differences between the two models beyond the three categories already mentioned. See the interactive online results for a full list: app.feedbackforensics.com?data=arena_s...
Feedback Forensics App
app.feedbackforensics.com
April 17, 2025 at 1:55 PM
➡️ Further differences: Clearer reasoning, more references, …
There are quite a few other differences between the two models beyond the three categories already mentioned. See the interactive online results for a full list: app.feedbackforensics.com?data=arena_s...
There are quite a few other differences between the two models beyond the three categories already mentioned. See the interactive online results for a full list: app.feedbackforensics.com?data=arena_s...
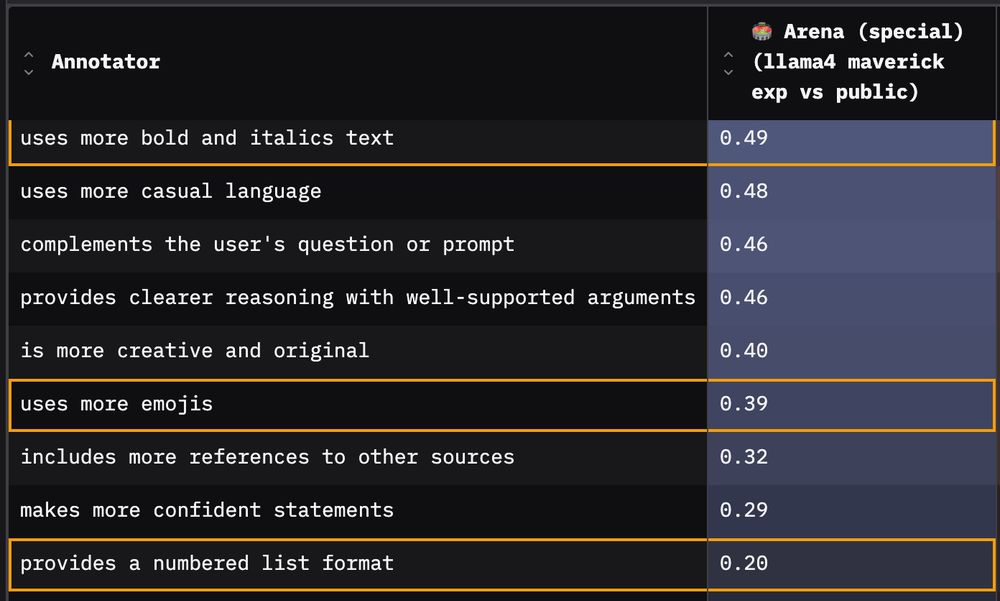
3️⃣ Third: Formatting - a lot of it!
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
April 17, 2025 at 1:55 PM
3️⃣ Third: Formatting - a lot of it!
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
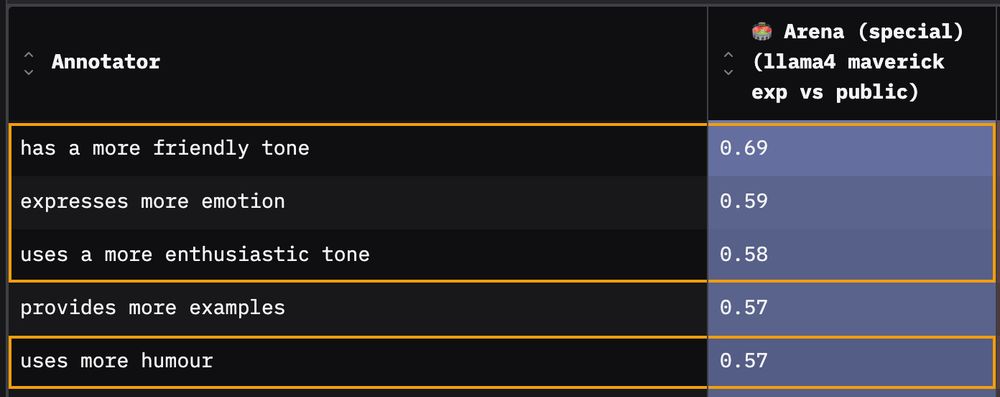
2️⃣ Second: Tone - friendlier, more enthusiastic, more humour …
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
April 17, 2025 at 1:55 PM
2️⃣ Second: Tone - friendlier, more enthusiastic, more humour …
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
So how exactly is the arena version different to the public Llama 4 Maverick model? I make a few observations…
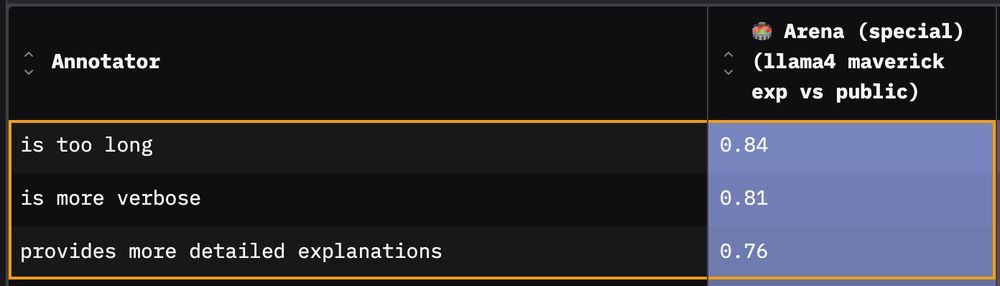
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
April 17, 2025 at 1:55 PM
So how exactly is the arena version different to the public Llama 4 Maverick model? I make a few observations…
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
📈 Note on interpreting metrics: values above 0 → characteristic more present in arena model's responses than public model's. See linked post for details
April 17, 2025 at 1:55 PM
📈 Note on interpreting metrics: values above 0 → characteristic more present in arena model's responses than public model's. See linked post for details
🧪 Setup: I use the original Arena dataset of Llama-4-Maverick experimental generations, kindly released openly by @lmarena (👏). I compare the arena model’s responses to those generated by its public weights version (via Lambda and OpenRouter).
April 17, 2025 at 1:55 PM
🧪 Setup: I use the original Arena dataset of Llama-4-Maverick experimental generations, kindly released openly by @lmarena (👏). I compare the arena model’s responses to those generated by its public weights version (via Lambda and OpenRouter).
ℹ️ Background: Llama 4 Maverick was released earlier this month. Beforehand, a separate experimental Arena version was evaluated on Chatbot Arena (Llama-4-Maverick-03-26-Experimental). Some have reported that these two models appear to be quite different.
April 17, 2025 at 1:55 PM
ℹ️ Background: Llama 4 Maverick was released earlier this month. Beforehand, a separate experimental Arena version was evaluated on Chatbot Arena (Llama-4-Maverick-03-26-Experimental). Some have reported that these two models appear to be quite different.
Feedback Forensics is just getting started with this Alpha release with lots of exciting features and experiments on the roadmap. Let me know what other datasets we should analyze or which features you would like to see! 🕵🏻
March 17, 2025 at 6:12 PM
Feedback Forensics is just getting started with this Alpha release with lots of exciting features and experiments on the roadmap. Let me know what other datasets we should analyze or which features you would like to see! 🕵🏻
Big thanks also to my collaborators on Feedback Forensics and the related Inverse Constitutional Al (ICAI) pipeline: Timo Kaufmann, Eyke Hüllermeier, @samuelalbanie.bsky.social, Rob Mullins!
Code: github.com/rdnfn/feedback-forensics
Note: usual limitations for LLM-as-a-Judge-based systems apply.
Code: github.com/rdnfn/feedback-forensics
Note: usual limitations for LLM-as-a-Judge-based systems apply.
GitHub - rdnfn/feedback-forensics: A tool to investigate pairwise feedback: understand and find issues in your data
A tool to investigate pairwise feedback: understand and find issues in your data - rdnfn/feedback-forensics
github.com
March 17, 2025 at 6:12 PM
Big thanks also to my collaborators on Feedback Forensics and the related Inverse Constitutional Al (ICAI) pipeline: Timo Kaufmann, Eyke Hüllermeier, @samuelalbanie.bsky.social, Rob Mullins!
Code: github.com/rdnfn/feedback-forensics
Note: usual limitations for LLM-as-a-Judge-based systems apply.
Code: github.com/rdnfn/feedback-forensics
Note: usual limitations for LLM-as-a-Judge-based systems apply.
... harmless/helpful data by @anthropic.com, and finally the recent OLMo 2 preference mix by @ljvmiranda.bsky.social, @natolambert.bsky.social et al., see all results at app.feedbackforensics.com.
Feedback Forensics App
app.feedbackforensics.com
March 17, 2025 at 6:12 PM
... harmless/helpful data by @anthropic.com, and finally the recent OLMo 2 preference mix by @ljvmiranda.bsky.social, @natolambert.bsky.social et al., see all results at app.feedbackforensics.com.
We analyze several popular feedback datasets: Chatbot Arena data with topic labels from the Arena Explorer pipeline, PRISM data by @hannahrosekirk.bsky.social et al, AlpacaEval annotations, ...
March 17, 2025 at 6:12 PM
We analyze several popular feedback datasets: Chatbot Arena data with topic labels from the Arena Explorer pipeline, PRISM data by @hannahrosekirk.bsky.social et al, AlpacaEval annotations, ...
🤖 3. Discovering model strengths
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🤖 3. Discovering model strengths
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
🧑🎨🧑💼 2. Finding preference differences between task domains
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🧑🎨🧑💼 2. Finding preference differences between task domains
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
🗂️ 1. Visualizing dataset differences
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🗂️ 1. Visualizing dataset differences
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...