



Arduin Findeis
@arduin.io
Working on evaluation of AI models (via human and AI feedback) | PhD candidate @cst.cam.ac.uk
Web: https://arduin.io
Github: https://github.com/rdnfn
Latest project: https://app.feedbackforensics.com
Web: https://arduin.io
Github: https://github.com/rdnfn
Latest project: https://app.feedbackforensics.com
Excited to be in Singapore for ICLR! Keen to chat about interpreting feedback data and detecting model characteristics ⚖️
Reach out or come by our poster on Inverse Constitutional AI on Friday 25 April from 10am-12.30pm (#520 in Hall 2B) - @timokauf.bsky.social and I will be there!
Reach out or come by our poster on Inverse Constitutional AI on Friday 25 April from 10am-12.30pm (#520 in Hall 2B) - @timokauf.bsky.social and I will be there!

April 24, 2025 at 3:47 PM
Excited to be in Singapore for ICLR! Keen to chat about interpreting feedback data and detecting model characteristics ⚖️
Reach out or come by our poster on Inverse Constitutional AI on Friday 25 April from 10am-12.30pm (#520 in Hall 2B) - @timokauf.bsky.social and I will be there!
Reach out or come by our poster on Inverse Constitutional AI on Friday 25 April from 10am-12.30pm (#520 in Hall 2B) - @timokauf.bsky.social and I will be there!
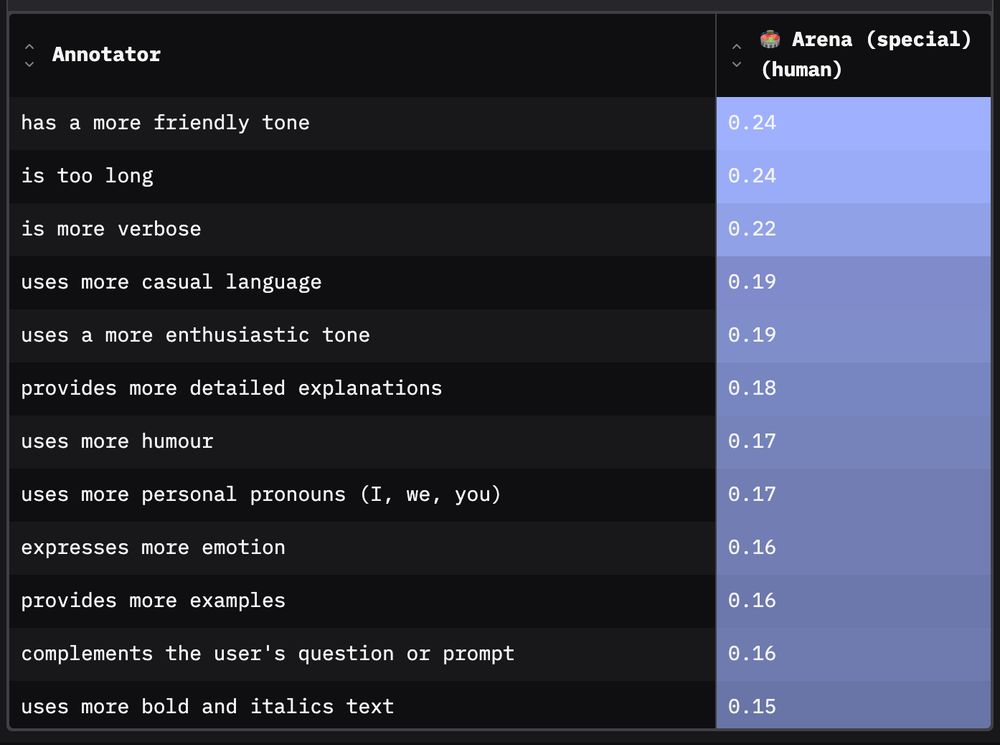
🎁 Bonus 2: Humans like the arena model’s behaviours
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
April 17, 2025 at 1:55 PM
🎁 Bonus 2: Humans like the arena model’s behaviours
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
Human annotators on Chatbot Arena indeed like the change in tone, more verbose responses and adapted formatting.
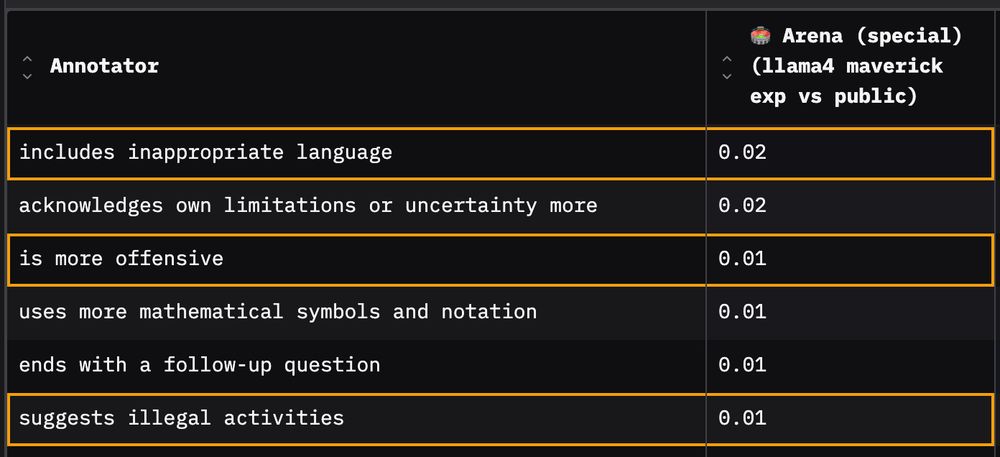
🎁 Bonus 1: Things that stayed consistent
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
April 17, 2025 at 1:55 PM
🎁 Bonus 1: Things that stayed consistent
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
I also find that some behaviours stayed the same: on the Arena dataset prompts, the public and arena model versions are similarly very unlikely to suggest illegal activities, be offensive or use inappropriate language.
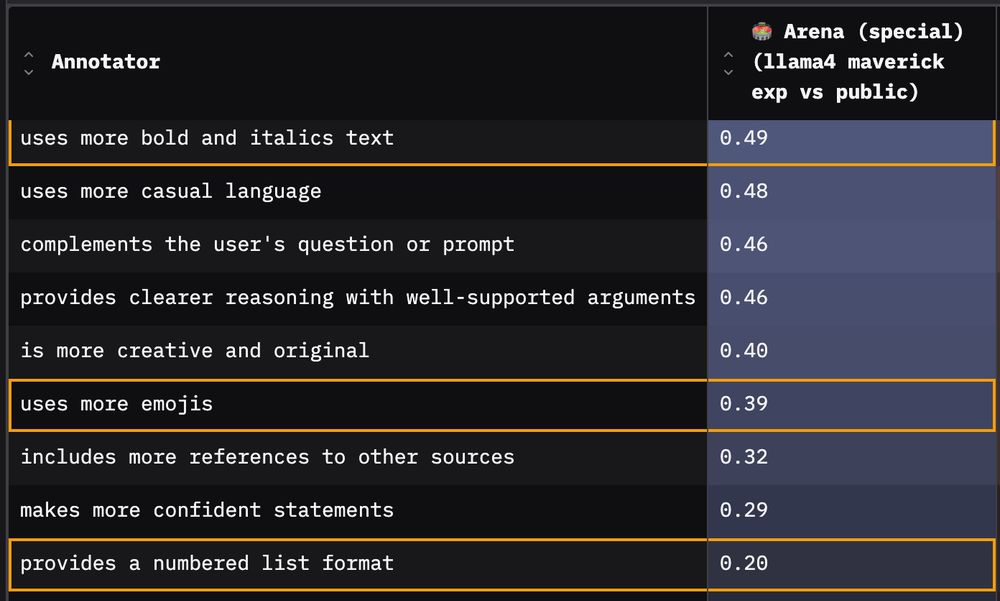
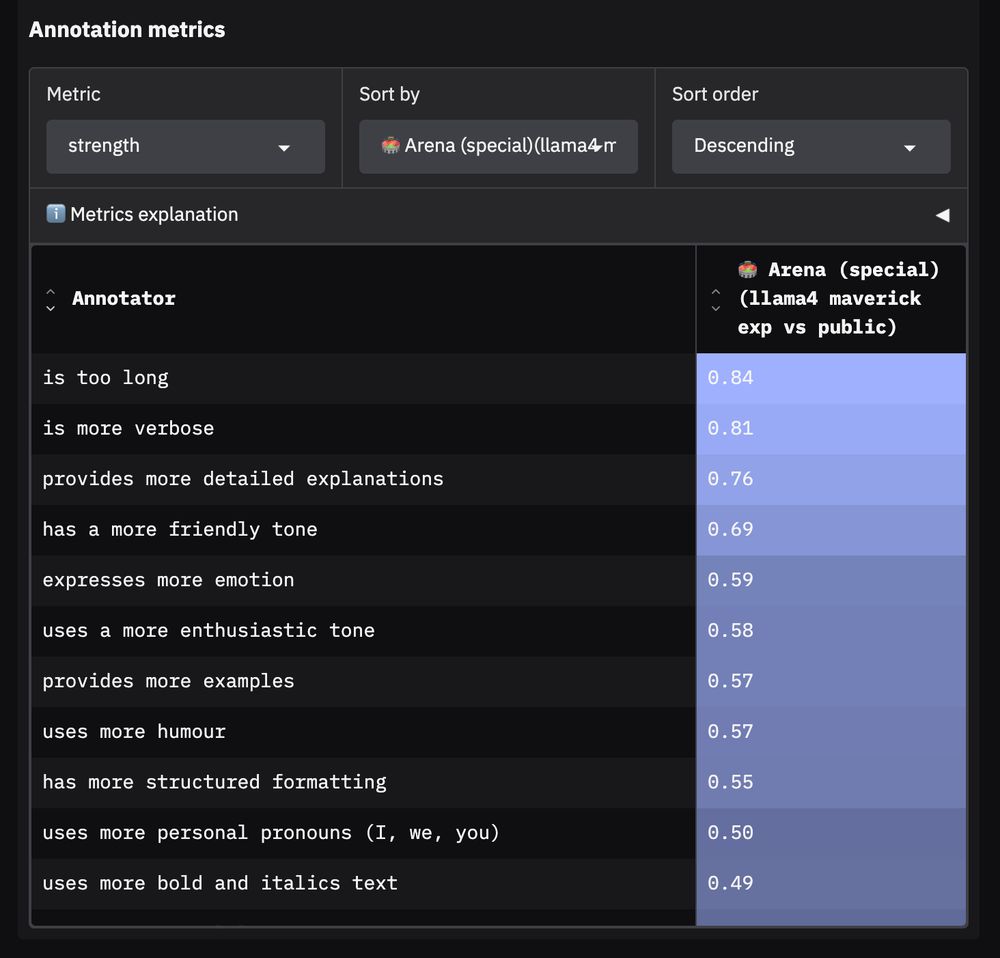
3️⃣ Third: Formatting - a lot of it!
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
April 17, 2025 at 1:55 PM
3️⃣ Third: Formatting - a lot of it!
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
The arena model uses more bold, italics, numbered lists and emojis relative to its public version.
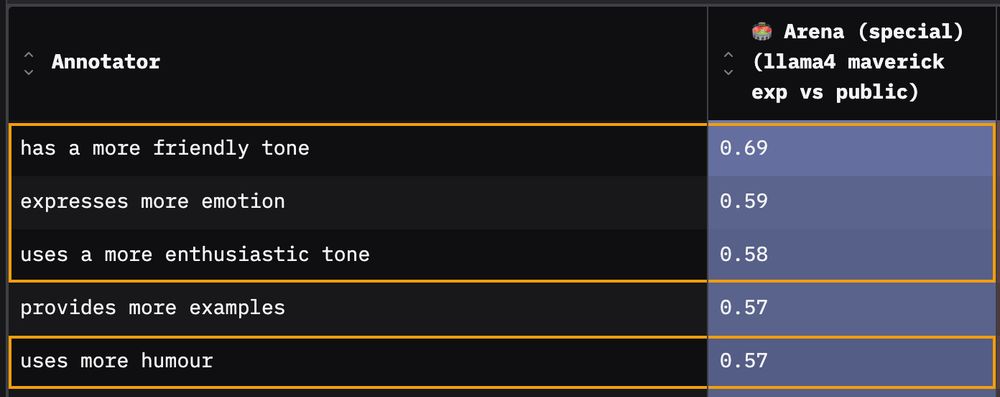
2️⃣ Second: Tone - friendlier, more enthusiastic, more humour …
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
April 17, 2025 at 1:55 PM
2️⃣ Second: Tone - friendlier, more enthusiastic, more humour …
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
Next, the results highlight how much friendlier, emotional, enthusiastic, humorous, confident and casual the arena model is relative to its own public weights version (and also its opponent models).
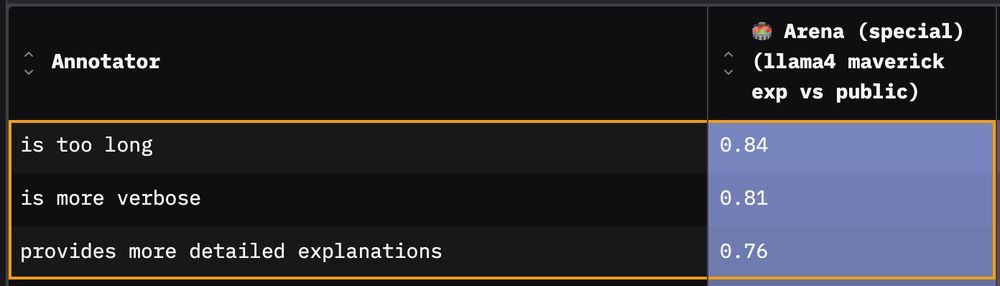
So how exactly is the arena version different to the public Llama 4 Maverick model? I make a few observations…
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
April 17, 2025 at 1:55 PM
So how exactly is the arena version different to the public Llama 4 Maverick model? I make a few observations…
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
1️⃣ First and most obvious: Responses are more verbose. The arena model’s responses are longer relative to the public version for 99% of prompts.
How exactly was the initial Chatbot Arena version of Llama 4 Maverick different from the public HuggingFace version?🕵️
I used our Feedback Forensics app to quantitatively analyse how exactly these two models differ. An overview…👇🧵
I used our Feedback Forensics app to quantitatively analyse how exactly these two models differ. An overview…👇🧵
April 17, 2025 at 1:55 PM
How exactly was the initial Chatbot Arena version of Llama 4 Maverick different from the public HuggingFace version?🕵️
I used our Feedback Forensics app to quantitatively analyse how exactly these two models differ. An overview…👇🧵
I used our Feedback Forensics app to quantitatively analyse how exactly these two models differ. An overview…👇🧵
🤖 3. Discovering model strengths
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🤖 3. Discovering model strengths
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
How is GPT-4o different to other models? → Uses more numbered lists, but Gemini is more friendly and polite
app.feedbackforensics.com?data=chatbot...
🧑🎨🧑💼 2. Finding preference differences between task domains
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🧑🎨🧑💼 2. Finding preference differences between task domains
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
How do preferences differ across writing tasks? → Emails should be concise, creative writing more verbose
app.feedbackforensics.com?data=chatbot...
🗂️ 1. Visualizing dataset differences
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...

March 17, 2025 at 6:12 PM
🗂️ 1. Visualizing dataset differences
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...
How does Chatbot Arena differ from Anthropic Helpful data? → Prefers less polite but better formatted responses
app.feedbackforensics.com?data=chatbot...
🕵🏻💬 Introducing Feedback Forensics: a new tool to investigate pairwise preference data.
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
March 17, 2025 at 6:12 PM
🕵🏻💬 Introducing Feedback Forensics: a new tool to investigate pairwise preference data.
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵