




Archiki Prasad
@archiki.bsky.social
Ph.D. Student at UNC NLP | Apple Scholar in AI/ML Ph.D. Fellowship | Prev: FAIR at Meta, AI2, Adobe (Intern) | Interests: #NLP, #ML | https://archiki.github.io/
Can RAG systems handle imbalanced evidence or increasing misinformation?
➡️ As document support becomes imbalanced, baselines ignore under-supported correct answers but MADAM-RAG maintains stable performance
➡️ As misinformation 📈, baselines degrade sharply (−46%) but MADAM-RAG remains more robust
➡️ As document support becomes imbalanced, baselines ignore under-supported correct answers but MADAM-RAG maintains stable performance
➡️ As misinformation 📈, baselines degrade sharply (−46%) but MADAM-RAG remains more robust

April 18, 2025 at 5:06 PM
Can RAG systems handle imbalanced evidence or increasing misinformation?
➡️ As document support becomes imbalanced, baselines ignore under-supported correct answers but MADAM-RAG maintains stable performance
➡️ As misinformation 📈, baselines degrade sharply (−46%) but MADAM-RAG remains more robust
➡️ As document support becomes imbalanced, baselines ignore under-supported correct answers but MADAM-RAG maintains stable performance
➡️ As misinformation 📈, baselines degrade sharply (−46%) but MADAM-RAG remains more robust
How important are multi-round debate and aggregation in MADAM-RAG?
Increasing debate rounds in MADAM-RAG improves performance by allowing agents to refine answers via debate.
Aggregator provides even greater gains, especially in early rounds, aligning conflicting views & suppressing misinfo.
Increasing debate rounds in MADAM-RAG improves performance by allowing agents to refine answers via debate.
Aggregator provides even greater gains, especially in early rounds, aligning conflicting views & suppressing misinfo.

April 18, 2025 at 5:06 PM
How important are multi-round debate and aggregation in MADAM-RAG?
Increasing debate rounds in MADAM-RAG improves performance by allowing agents to refine answers via debate.
Aggregator provides even greater gains, especially in early rounds, aligning conflicting views & suppressing misinfo.
Increasing debate rounds in MADAM-RAG improves performance by allowing agents to refine answers via debate.
Aggregator provides even greater gains, especially in early rounds, aligning conflicting views & suppressing misinfo.
We evaluate on 3 datasets: FaithEval (suppression of misinformation), AmbigDocs (disambiguation across sources), RAMDocs (our dataset w/ different types of conflict).
MADAM-RAG consistently outperforms concatenated-prompt and Astute RAG baselines across all three datasets and model backbones.
MADAM-RAG consistently outperforms concatenated-prompt and Astute RAG baselines across all three datasets and model backbones.

April 18, 2025 at 5:06 PM
We evaluate on 3 datasets: FaithEval (suppression of misinformation), AmbigDocs (disambiguation across sources), RAMDocs (our dataset w/ different types of conflict).
MADAM-RAG consistently outperforms concatenated-prompt and Astute RAG baselines across all three datasets and model backbones.
MADAM-RAG consistently outperforms concatenated-prompt and Astute RAG baselines across all three datasets and model backbones.
We propose MADAM-RAG, a structured, multi-agent framework designed to handle inter-doc conflicts, misinformation, & noise in retrieved content, comprising:
1️⃣ Independent LLM agents - generate intermediate response conditioned on a single doc
2️⃣ Centralized aggregator
3️⃣ Iterative multi-round debate
1️⃣ Independent LLM agents - generate intermediate response conditioned on a single doc
2️⃣ Centralized aggregator
3️⃣ Iterative multi-round debate

April 18, 2025 at 5:06 PM
We propose MADAM-RAG, a structured, multi-agent framework designed to handle inter-doc conflicts, misinformation, & noise in retrieved content, comprising:
1️⃣ Independent LLM agents - generate intermediate response conditioned on a single doc
2️⃣ Centralized aggregator
3️⃣ Iterative multi-round debate
1️⃣ Independent LLM agents - generate intermediate response conditioned on a single doc
2️⃣ Centralized aggregator
3️⃣ Iterative multi-round debate
📂RAMDocs is designed to reflect the complexities of real-world retrieval. It includes:
➡️ Ambiguous queries w/ multiple valid ans.
➡️ Imbalanced document support (some answers backed by many sources, others by fewer)
➡️ Docs w/ misinformation (plausible but wrong claims) or noisy/irrelevant content
➡️ Ambiguous queries w/ multiple valid ans.
➡️ Imbalanced document support (some answers backed by many sources, others by fewer)
➡️ Docs w/ misinformation (plausible but wrong claims) or noisy/irrelevant content

April 18, 2025 at 5:06 PM
📂RAMDocs is designed to reflect the complexities of real-world retrieval. It includes:
➡️ Ambiguous queries w/ multiple valid ans.
➡️ Imbalanced document support (some answers backed by many sources, others by fewer)
➡️ Docs w/ misinformation (plausible but wrong claims) or noisy/irrelevant content
➡️ Ambiguous queries w/ multiple valid ans.
➡️ Imbalanced document support (some answers backed by many sources, others by fewer)
➡️ Docs w/ misinformation (plausible but wrong claims) or noisy/irrelevant content
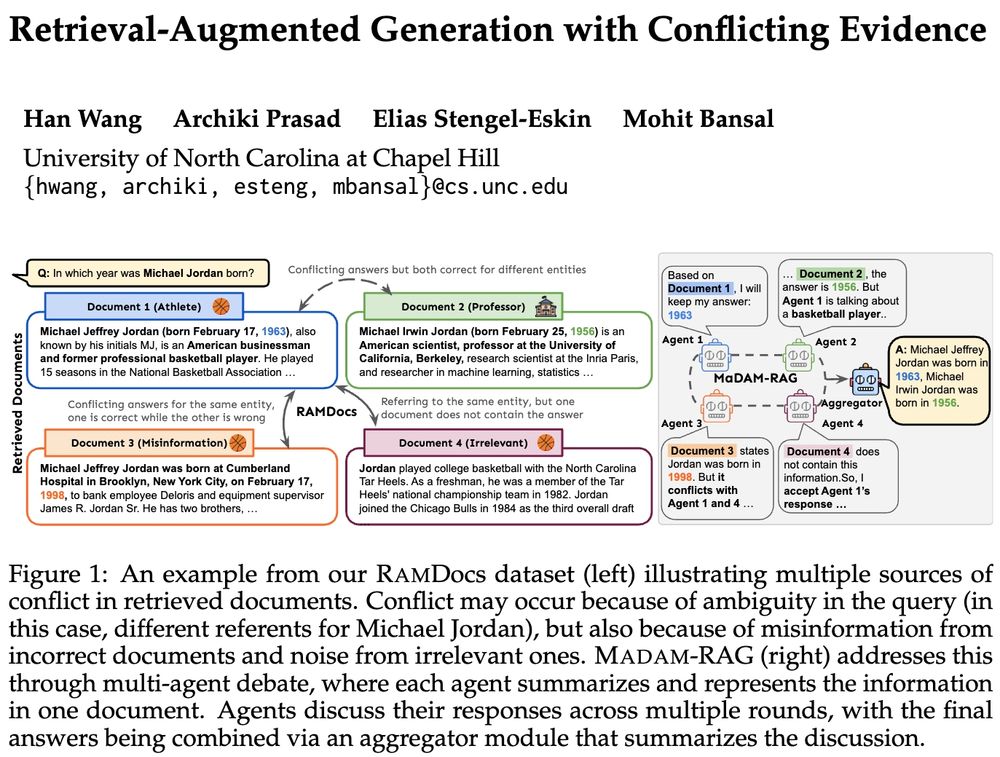
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
April 18, 2025 at 5:06 PM
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
🥳🥳 Honored and grateful to be awarded the 2025 Apple Scholars in AI/ML PhD Fellowship! ✨
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...

March 27, 2025 at 7:25 PM
🥳🥳 Honored and grateful to be awarded the 2025 Apple Scholars in AI/ML PhD Fellowship! ✨
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...
Lastly, we show that both test-time scaling and backtracking are crucial for UTDebug, and scaling the number of generated UTs also consistently improves code accuracy.


February 4, 2025 at 7:10 PM
Lastly, we show that both test-time scaling and backtracking are crucial for UTDebug, and scaling the number of generated UTs also consistently improves code accuracy.
Combining UTGen with UTDebug 🤝 we consistently outperform no UT feedback, randomly sampling UTs, and prompting targeted UTs across 3 models & datasets.
For partially correct code with subtle errors (our MBPP+Fix hard split) debugging with UTGen improves over baselines by >12.35% on Qwen 2.5!
For partially correct code with subtle errors (our MBPP+Fix hard split) debugging with UTGen improves over baselines by >12.35% on Qwen 2.5!

February 4, 2025 at 7:10 PM
Combining UTGen with UTDebug 🤝 we consistently outperform no UT feedback, randomly sampling UTs, and prompting targeted UTs across 3 models & datasets.
For partially correct code with subtle errors (our MBPP+Fix hard split) debugging with UTGen improves over baselines by >12.35% on Qwen 2.5!
For partially correct code with subtle errors (our MBPP+Fix hard split) debugging with UTGen improves over baselines by >12.35% on Qwen 2.5!
RQ3: We also propose ✨UTDebug ✨ with two key modifications:
1⃣Test-time scaling (self-consistency over multiple samples) for increasing output acc.
2⃣Validation & Backtracking: Generating multiple UTs to perform validation, accept edits only when the overall pass rate increases & backtrack otherwise
1⃣Test-time scaling (self-consistency over multiple samples) for increasing output acc.
2⃣Validation & Backtracking: Generating multiple UTs to perform validation, accept edits only when the overall pass rate increases & backtrack otherwise

February 4, 2025 at 7:10 PM
RQ3: We also propose ✨UTDebug ✨ with two key modifications:
1⃣Test-time scaling (self-consistency over multiple samples) for increasing output acc.
2⃣Validation & Backtracking: Generating multiple UTs to perform validation, accept edits only when the overall pass rate increases & backtrack otherwise
1⃣Test-time scaling (self-consistency over multiple samples) for increasing output acc.
2⃣Validation & Backtracking: Generating multiple UTs to perform validation, accept edits only when the overall pass rate increases & backtrack otherwise
On three metrics: attack rate, output acc, and acc + attack (measuring both) we benchmark several open-source 7-8B LLMs.
We find that UTGen models balance output acc and attack rate and result in 7.59% more failing/error-revealing unit tests with correct outputs on Qwen-2.5.
We find that UTGen models balance output acc and attack rate and result in 7.59% more failing/error-revealing unit tests with correct outputs on Qwen-2.5.

February 4, 2025 at 7:10 PM
On three metrics: attack rate, output acc, and acc + attack (measuring both) we benchmark several open-source 7-8B LLMs.
We find that UTGen models balance output acc and attack rate and result in 7.59% more failing/error-revealing unit tests with correct outputs on Qwen-2.5.
We find that UTGen models balance output acc and attack rate and result in 7.59% more failing/error-revealing unit tests with correct outputs on Qwen-2.5.
✨UTGen ✨ bootstraps training data from code generation datasets to train unit test generators.
Given coding problems and their solutions, we 1⃣ perturb the code to simulate errors, 2⃣ find challenging UT inputs, 3⃣ generate CoT rationales deducing the correct UT output for challenging UT inputs.
Given coding problems and their solutions, we 1⃣ perturb the code to simulate errors, 2⃣ find challenging UT inputs, 3⃣ generate CoT rationales deducing the correct UT output for challenging UT inputs.

February 4, 2025 at 7:10 PM
✨UTGen ✨ bootstraps training data from code generation datasets to train unit test generators.
Given coding problems and their solutions, we 1⃣ perturb the code to simulate errors, 2⃣ find challenging UT inputs, 3⃣ generate CoT rationales deducing the correct UT output for challenging UT inputs.
Given coding problems and their solutions, we 1⃣ perturb the code to simulate errors, 2⃣ find challenging UT inputs, 3⃣ generate CoT rationales deducing the correct UT output for challenging UT inputs.
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨
which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests.
UTGen+UTDebug yields large gains in debugging (+12% pass@1) & addresses 3 key questions:
🧵👇
which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests.
UTGen+UTDebug yields large gains in debugging (+12% pass@1) & addresses 3 key questions:
🧵👇

February 4, 2025 at 7:10 PM
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨
which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests.
UTGen+UTDebug yields large gains in debugging (+12% pass@1) & addresses 3 key questions:
🧵👇
which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests.
UTGen+UTDebug yields large gains in debugging (+12% pass@1) & addresses 3 key questions:
🧵👇