



Andrew E. Papale
@andrewpapale.bsky.social
Pitt Postdoc | neuroscience | decision-making | olfaction | fMRI | motor skill learning
Physics and math enthusiast. Friendly with R, Matlab, and Python.
Physics and math enthusiast. Friendly with R, Matlab, and Python.
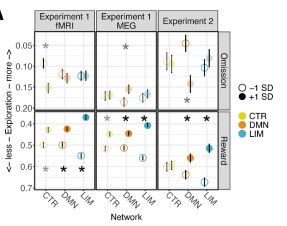
Finally, we look at the effects of this connectivity analysis on exploration behavior. We find that following rewarded trials, higher entropy modulation of posterior hippocampal-DMN connectivity predicted subsequent exploration. Maybe these signals are related to choice. 13/15
April 3, 2025 at 12:11 AM
Finally, we look at the effects of this connectivity analysis on exploration behavior. We find that following rewarded trials, higher entropy modulation of posterior hippocampal-DMN connectivity predicted subsequent exploration. Maybe these signals are related to choice. 13/15
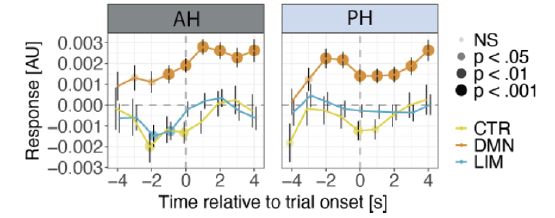
We next examine interactions between vPFC and hippocampus using the deconvolved MLM framework. We do this by using HC as a regressor and vPFC as an outcome. A key result from this analysis is that hippocampal-DMN connectivity is higher when entropy is higher. 12/15
April 3, 2025 at 12:11 AM
We next examine interactions between vPFC and hippocampus using the deconvolved MLM framework. We do this by using HC as a regressor and vPFC as an outcome. A key result from this analysis is that hippocampal-DMN connectivity is higher when entropy is higher. 12/15
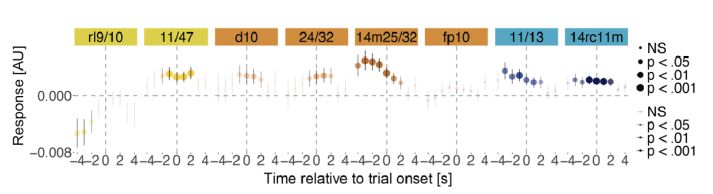
We find robust encoding of the value maximum in vPFC, strongest in region 14m25/32 of the DMN and in the LIM network. This is consistent with the neuroeconomic literature that suggests ventromedial PFC encodes scalar values. 11/15
April 3, 2025 at 12:11 AM
We find robust encoding of the value maximum in vPFC, strongest in region 14m25/32 of the DMN and in the LIM network. This is consistent with the neuroeconomic literature that suggests ventromedial PFC encodes scalar values. 11/15
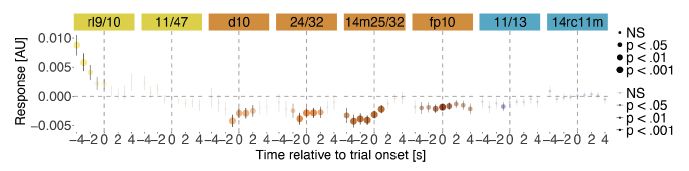
We find that DMN responds when entropy is lower, when there is likely one prominent global value maximum that is easier to exploit. We use deconvolved BOLD aligned to trial onset in a MLM. This allows examination of the time course of signals w.r.t. an event (like a PETH). 10/15
April 3, 2025 at 12:11 AM
We find that DMN responds when entropy is lower, when there is likely one prominent global value maximum that is easier to exploit. We use deconvolved BOLD aligned to trial onset in a MLM. This allows examination of the time course of signals w.r.t. an event (like a PETH). 10/15
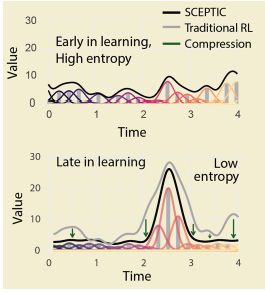
Entropy is an emergent property that captures the complexity of the value function on a given trial: higher entropy indicates many local value maxima (complex value landscape) and lower entropy typically indicates one prominent global value maximum (simple value landscape). 9/15
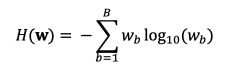
April 3, 2025 at 12:11 AM
Entropy is an emergent property that captures the complexity of the value function on a given trial: higher entropy indicates many local value maxima (complex value landscape) and lower entropy typically indicates one prominent global value maximum (simple value landscape). 9/15
An RL model is fit to subjects’ behavior, and the value maximum and entropy of the value distribution are calculated on each trial. We can then examine neural correlates with predictions from the model. 8/15
April 3, 2025 at 12:11 AM
An RL model is fit to subjects’ behavior, and the value maximum and entropy of the value distribution are calculated on each trial. We can then examine neural correlates with predictions from the model. 8/15
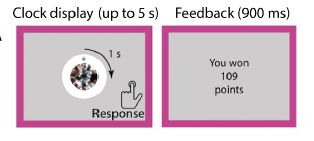
Subjects explore and exploit on a clock task where a dot rotates 360 deg, and responding at different locations gives probabilistic rewards. Hidden underlying value distributions are learned through exploration. Subjects play this task during an fMRI scan. 7/15
April 3, 2025 at 12:11 AM
Subjects explore and exploit on a clock task where a dot rotates 360 deg, and responding at different locations gives probabilistic rewards. Hidden underlying value distributions are learned through exploration. Subjects play this task during an fMRI scan. 7/15
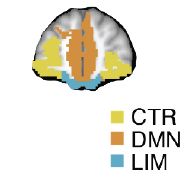
Here we extend these findings to ventral prefrontal cortex (vPFC), and interactions between hippocampus and vPFC. We examine 3 resting state networks, the control (CTR), default mode (DMN) and limbic (LIM). Importantly, we replicate key findings out-of-sample. 6/15
April 3, 2025 at 12:11 AM
Here we extend these findings to ventral prefrontal cortex (vPFC), and interactions between hippocampus and vPFC. We examine 3 resting state networks, the control (CTR), default mode (DMN) and limbic (LIM). Importantly, we replicate key findings out-of-sample. 6/15
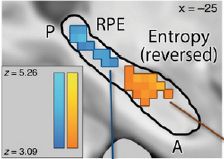
In prior work, we found that compressing out some of the information the RL agent could have learned better explained people’s choices. Compressed (lower-entropy) maps of valuable options were found in the anterior hippocampus with fMRI. 5/15
April 3, 2025 at 12:11 AM
In prior work, we found that compressing out some of the information the RL agent could have learned better explained people’s choices. Compressed (lower-entropy) maps of valuable options were found in the anterior hippocampus with fMRI. 5/15
We encounter a similar problem when we decide whether to stick with known good options or explore unknown but possibly better alternatives. Reinforcement learning (RL) algorithms are often used to solve this so-called explore/exploit (E/E) dilemma. 3/15

April 3, 2025 at 12:11 AM
We encounter a similar problem when we decide whether to stick with known good options or explore unknown but possibly better alternatives. Reinforcement learning (RL) algorithms are often used to solve this so-called explore/exploit (E/E) dilemma. 3/15
During WW2, Alan Turing decoded the German Enigma using an early computer. He used common phrases and statistical techniques to limit the number of possible solutions, eliminating extraneous alternatives. Does our brain do something similar? 2/15

April 3, 2025 at 12:11 AM
During WW2, Alan Turing decoded the German Enigma using an early computer. He used common phrases and statistical techniques to limit the number of possible solutions, eliminating extraneous alternatives. Does our brain do something similar? 2/15