




Amr Farahat
@amr-farahat.bsky.social
MD/M.Sc/PhD candidate @ESI_Frankfurt and IMPRS for neural circuits @MpiBrain. Medicine, Neuroscience & AI
https://amr-farahat.github.io/
https://amr-farahat.github.io/
Yes! Next Wednesday! 🙏
October 16, 2025 at 4:33 PM
Yes! Next Wednesday! 🙏
Congratulations! 🎉🎉 And welcome to Frankfurt!
October 16, 2025 at 8:37 AM
Congratulations! 🎉🎉 And welcome to Frankfurt!
Yes indeed. It probably has something to do with learning dynamics that favors increasing the complexity gradually. Or it could be that the loss landscape has edges between high and low complexity volumes
March 15, 2025 at 1:31 PM
Yes indeed. It probably has something to do with learning dynamics that favors increasing the complexity gradually. Or it could be that the loss landscape has edges between high and low complexity volumes
In AlexNet, however, the first layers are the most predictive. That's because they have bigger filters at earlier layers (see Miao and Tong 2024)
March 15, 2025 at 12:35 PM
In AlexNet, however, the first layers are the most predictive. That's because they have bigger filters at earlier layers (see Miao and Tong 2024)
V1 is usually predicted by more intermediate layers than early layers but it depends on the architecture of the model. In Cadena et al 2019 block3_conv1 in VGG19 was the most predictive. Early layers in VGG have very small receptive fields which makes it difficult to capture V1-like features.
March 15, 2025 at 12:35 PM
V1 is usually predicted by more intermediate layers than early layers but it depends on the architecture of the model. In Cadena et al 2019 block3_conv1 in VGG19 was the most predictive. Early layers in VGG have very small receptive fields which makes it difficult to capture V1-like features.
This was the most predictive layer of V1 in the VGG16 model. Same for IT, it was block4_conv2.
March 15, 2025 at 10:58 AM
This was the most predictive layer of V1 in the VGG16 model. Same for IT, it was block4_conv2.
and then starts increasing again with further training to fit the target function. This is the most likely explanation for the initial drop in V1 prediction.
March 15, 2025 at 10:57 AM
and then starts increasing again with further training to fit the target function. This is the most likely explanation for the initial drop in V1 prediction.
We also observed in separate experiments on the simple CNN models that the complexity of the models "resets" to a low value (lower than its random-weight complexity) after the first training epoch (likely using the linear part of the activation function)
March 15, 2025 at 10:57 AM
We also observed in separate experiments on the simple CNN models that the complexity of the models "resets" to a low value (lower than its random-weight complexity) after the first training epoch (likely using the linear part of the activation function)
Thanks for your interest! Object recognition performance increases directly starting from the first training epoch and nevertheless V1 prediction drops considerably so this drop supports the non significance of object recognition training for V1.
March 15, 2025 at 10:57 AM
Thanks for your interest! Object recognition performance increases directly starting from the first training epoch and nevertheless V1 prediction drops considerably so this drop supports the non significance of object recognition training for V1.
The legend of the left plot was missing!

March 14, 2025 at 5:32 PM
The legend of the left plot was missing!
read more here
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...

Neural responses in early, but not late, visual cortex are well predicted by random-weight CNNs with sufficient model complexity
Convolutional neural networks (CNNs) were inspired by the organization of the primate visual system, and in turn have become effective models of the visual cortex, allowing for accurate predictions of...
www.biorxiv.org
March 13, 2025 at 9:34 PM
read more here
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
15/15
It is also important to use various ways to assess model strengths and weaknesses, not just one like prediction accuracy.
It is also important to use various ways to assess model strengths and weaknesses, not just one like prediction accuracy.
March 13, 2025 at 9:34 PM
15/15
It is also important to use various ways to assess model strengths and weaknesses, not just one like prediction accuracy.
It is also important to use various ways to assess model strengths and weaknesses, not just one like prediction accuracy.
14/15
Our results also emphasize the importance of rigorous controls when using black box models like DNNs in neural modeling. They can show what makes a good neural model, and help us generate hypotheses about brain computations
Our results also emphasize the importance of rigorous controls when using black box models like DNNs in neural modeling. They can show what makes a good neural model, and help us generate hypotheses about brain computations
March 13, 2025 at 9:34 PM
14/15
Our results also emphasize the importance of rigorous controls when using black box models like DNNs in neural modeling. They can show what makes a good neural model, and help us generate hypotheses about brain computations
Our results also emphasize the importance of rigorous controls when using black box models like DNNs in neural modeling. They can show what makes a good neural model, and help us generate hypotheses about brain computations
13/15
Our results suggest that the architecture bias of CNNs is key to predicting neural responses in the early visual cortex, which aligns with results in computer vision, showing that random convolutions suffice for several visual tasks.
Our results suggest that the architecture bias of CNNs is key to predicting neural responses in the early visual cortex, which aligns with results in computer vision, showing that random convolutions suffice for several visual tasks.
March 13, 2025 at 9:34 PM
13/15
Our results suggest that the architecture bias of CNNs is key to predicting neural responses in the early visual cortex, which aligns with results in computer vision, showing that random convolutions suffice for several visual tasks.
Our results suggest that the architecture bias of CNNs is key to predicting neural responses in the early visual cortex, which aligns with results in computer vision, showing that random convolutions suffice for several visual tasks.
12/15
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
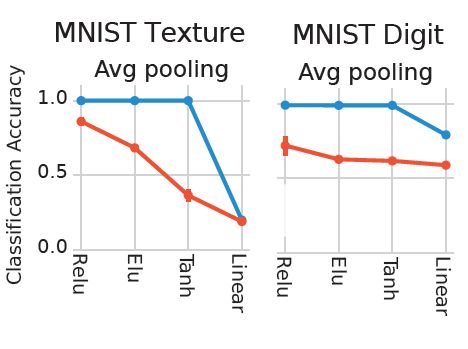
March 13, 2025 at 9:34 PM
12/15
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
11/15
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination

March 13, 2025 at 9:34 PM
11/15
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
10/15
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
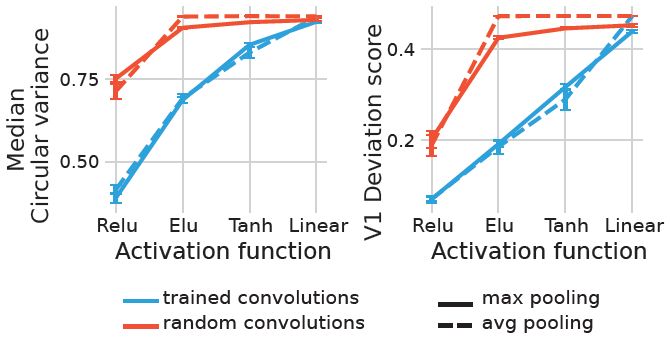
March 13, 2025 at 9:34 PM
10/15
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.