




Amr Farahat
@amr-farahat.bsky.social
MD/M.Sc/PhD candidate @ESI_Frankfurt and IMPRS for neural circuits @MpiBrain. Medicine, Neuroscience & AI
https://amr-farahat.github.io/
https://amr-farahat.github.io/
The legend of the left plot was missing!

March 14, 2025 at 5:32 PM
The legend of the left plot was missing!
12/15
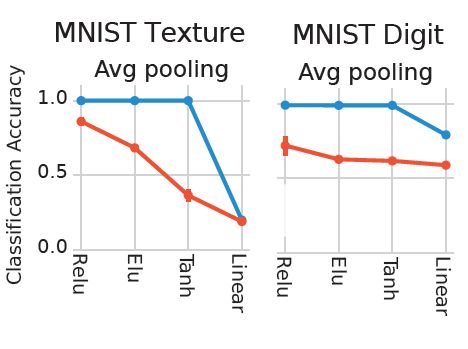
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
March 13, 2025 at 9:34 PM
12/15
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
We found that random ReLU networks performed the best among random networks and only slightly worse than the fully trained counterpart.
11/15
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination

March 13, 2025 at 9:34 PM
11/15
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
Then we tested for the ability of random networks to support texture discrimination, a task known to involve early visual cortex. We created Texture-MNIST, a dataset that allows for training for two tasks: object (Digit) recognition and texture discrimination
10/15
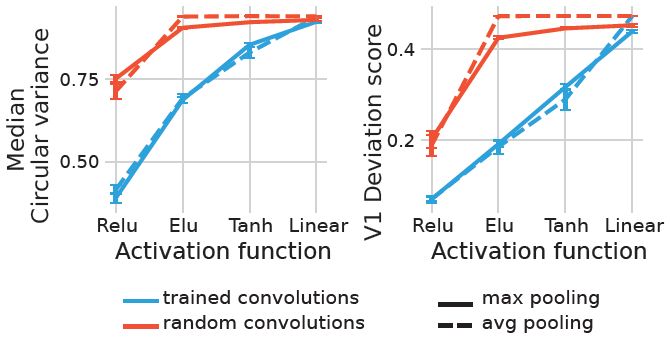
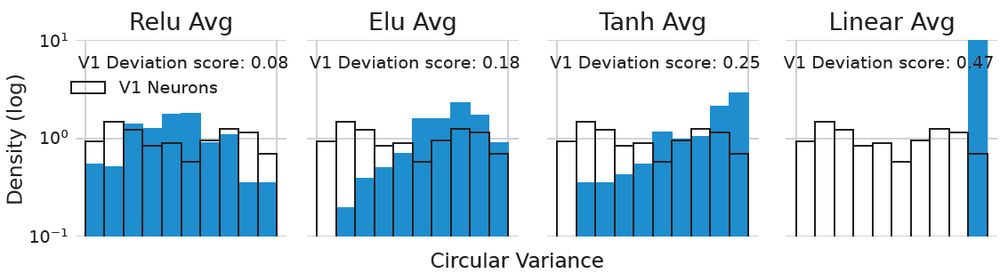
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
March 13, 2025 at 9:34 PM
10/15
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
We found that trained ReLU networks are the most V1-like concerning OS. Moreover, random ReLU networks were the most V1-like among random networks and even on par with other fully trained networks.
9/15
We quantified the orientation selectivity (OS) of artificial neurons using circular variance and calculated how their distribution deviates from the distribution of an independent dataset of experimentally recorded v1 neurons
We quantified the orientation selectivity (OS) of artificial neurons using circular variance and calculated how their distribution deviates from the distribution of an independent dataset of experimentally recorded v1 neurons
March 13, 2025 at 9:34 PM
9/15
We quantified the orientation selectivity (OS) of artificial neurons using circular variance and calculated how their distribution deviates from the distribution of an independent dataset of experimentally recorded v1 neurons
We quantified the orientation selectivity (OS) of artificial neurons using circular variance and calculated how their distribution deviates from the distribution of an independent dataset of experimentally recorded v1 neurons
6/15
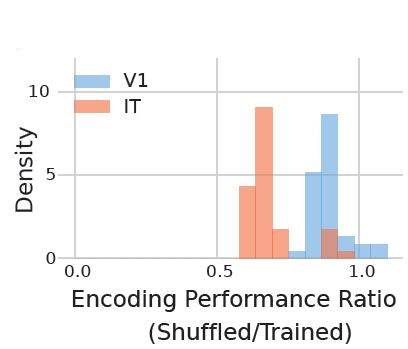
Even when we shuffled the trained weights of the convolutional filters, V1 models were way less affected than IT
Even when we shuffled the trained weights of the convolutional filters, V1 models were way less affected than IT
March 13, 2025 at 9:34 PM
6/15
Even when we shuffled the trained weights of the convolutional filters, V1 models were way less affected than IT
Even when we shuffled the trained weights of the convolutional filters, V1 models were way less affected than IT
4/15
We quantified the complexity of the models transformations and found that ReLU models and max pooling models had considerably higher complexity. Moreover, complexity explained substantial variance in V1 encoding performance in comparison to IT (63%) and VO (55%) (not shown here)
We quantified the complexity of the models transformations and found that ReLU models and max pooling models had considerably higher complexity. Moreover, complexity explained substantial variance in V1 encoding performance in comparison to IT (63%) and VO (55%) (not shown here)
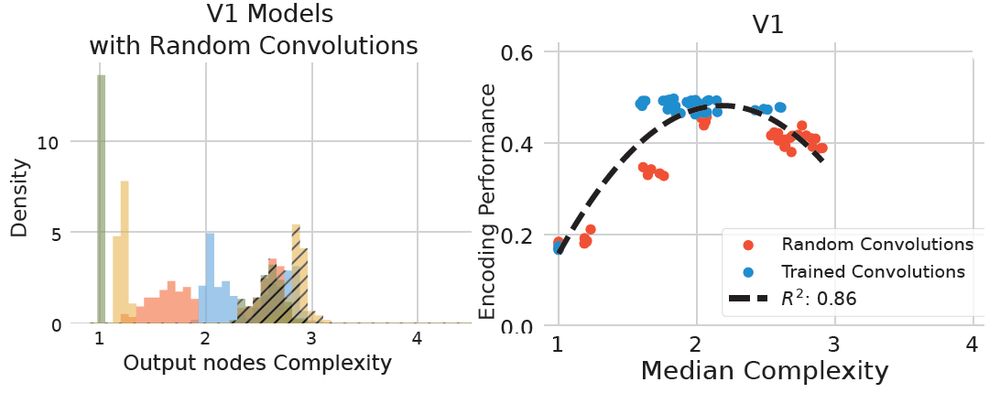
March 13, 2025 at 9:34 PM
4/15
We quantified the complexity of the models transformations and found that ReLU models and max pooling models had considerably higher complexity. Moreover, complexity explained substantial variance in V1 encoding performance in comparison to IT (63%) and VO (55%) (not shown here)
We quantified the complexity of the models transformations and found that ReLU models and max pooling models had considerably higher complexity. Moreover, complexity explained substantial variance in V1 encoding performance in comparison to IT (63%) and VO (55%) (not shown here)
3/15
Surprisingly, we found out that even training simple CNN models directly on V1 data did not improve encoding performance substantially unlike IT. However, that was only true for CNNs using ReLU activation functions and/or max pooling.
Surprisingly, we found out that even training simple CNN models directly on V1 data did not improve encoding performance substantially unlike IT. However, that was only true for CNNs using ReLU activation functions and/or max pooling.
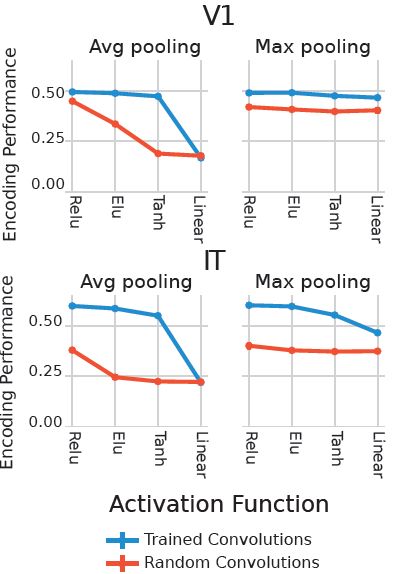
March 13, 2025 at 9:34 PM
3/15
Surprisingly, we found out that even training simple CNN models directly on V1 data did not improve encoding performance substantially unlike IT. However, that was only true for CNNs using ReLU activation functions and/or max pooling.
Surprisingly, we found out that even training simple CNN models directly on V1 data did not improve encoding performance substantially unlike IT. However, that was only true for CNNs using ReLU activation functions and/or max pooling.
2/15
We found that training CNNs for object recognition doesn’t improve V1 encoding as much as it does for higher visual areas (like IT in monkeys or VO in humans)! Is V1 encoding more about architecture than learning?
We found that training CNNs for object recognition doesn’t improve V1 encoding as much as it does for higher visual areas (like IT in monkeys or VO in humans)! Is V1 encoding more about architecture than learning?
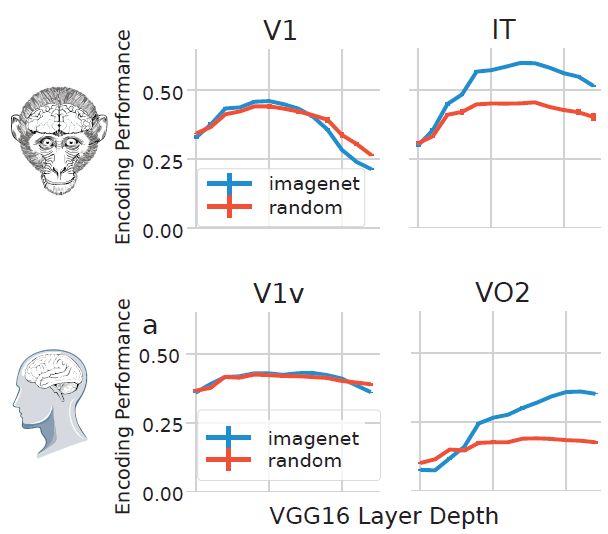
March 13, 2025 at 9:34 PM
2/15
We found that training CNNs for object recognition doesn’t improve V1 encoding as much as it does for higher visual areas (like IT in monkeys or VO in humans)! Is V1 encoding more about architecture than learning?
We found that training CNNs for object recognition doesn’t improve V1 encoding as much as it does for higher visual areas (like IT in monkeys or VO in humans)! Is V1 encoding more about architecture than learning?
🧵 time!
1/15
Why are CNNs so good at predicting neural responses in the primate visual system? Is it their design (architecture) or learning (training)? And does this change along the visual hierarchy?
🧠🤖
🧠📈
1/15
Why are CNNs so good at predicting neural responses in the primate visual system? Is it their design (architecture) or learning (training)? And does this change along the visual hierarchy?
🧠🤖
🧠📈

March 13, 2025 at 9:34 PM
🧵 time!
1/15
Why are CNNs so good at predicting neural responses in the primate visual system? Is it their design (architecture) or learning (training)? And does this change along the visual hierarchy?
🧠🤖
🧠📈
1/15
Why are CNNs so good at predicting neural responses in the primate visual system? Is it their design (architecture) or learning (training)? And does this change along the visual hierarchy?
🧠🤖
🧠📈