




Alessio Devoto
@alessiodevoto.bsky.social
PhD in ML/AI | Researching Efficient ML/AI (vision & language) 🍀 & Interpretability | @SapienzaRoma @EdinburghNLP | https://alessiodevoto.github.io/ | ex @NVIDIA
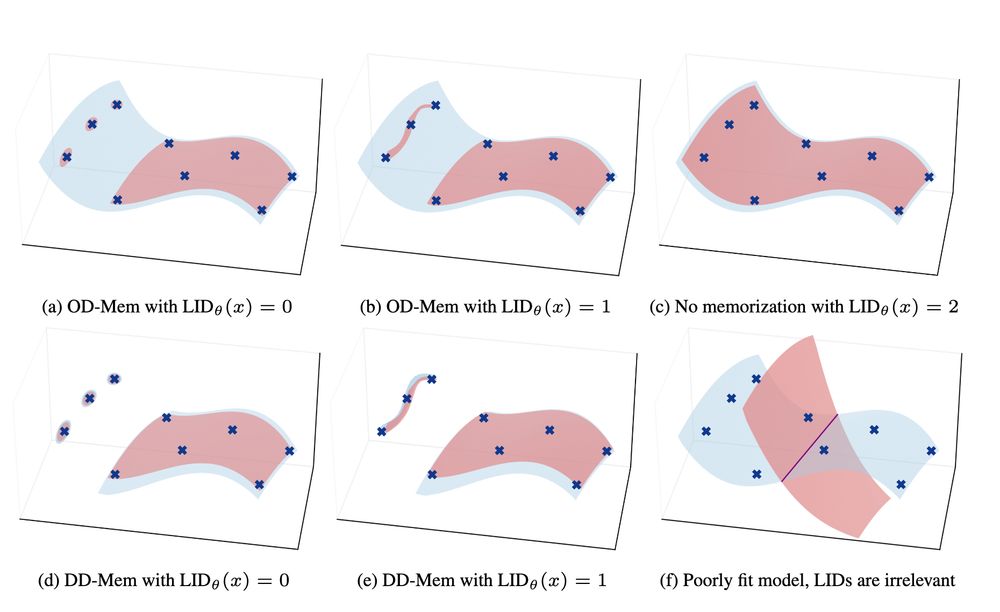
Cool research on how models memorize data 📝 : The 'Manifold Memorization Hypothesis' by Brendan Ross, Hamidreza Kamkariet al. suggests memorization occurs when the model's learned manifold matches the true data manifold but with too small 'local intrinsic dimensionality'.
February 5, 2025 at 4:11 PM
Cool research on how models memorize data 📝 : The 'Manifold Memorization Hypothesis' by Brendan Ross, Hamidreza Kamkariet al. suggests memorization occurs when the model's learned manifold matches the true data manifold but with too small 'local intrinsic dimensionality'.
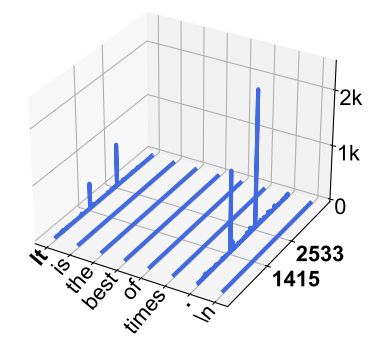
Massive activations & weights in LLMs, two cool works 🤓:
- The Super Weight: finds performance can be totally degraded when pruning a *single* weight - Mengxia Yu et al.
- Massive Activations in LLM:finds some (crucial) activations have very high norm irrespective of context - Mingjie Sun et al.
- The Super Weight: finds performance can be totally degraded when pruning a *single* weight - Mengxia Yu et al.
- Massive Activations in LLM:finds some (crucial) activations have very high norm irrespective of context - Mingjie Sun et al.
February 4, 2025 at 5:55 PM
Massive activations & weights in LLMs, two cool works 🤓:
- The Super Weight: finds performance can be totally degraded when pruning a *single* weight - Mengxia Yu et al.
- Massive Activations in LLM:finds some (crucial) activations have very high norm irrespective of context - Mingjie Sun et al.
- The Super Weight: finds performance can be totally degraded when pruning a *single* weight - Mengxia Yu et al.
- Massive Activations in LLM:finds some (crucial) activations have very high norm irrespective of context - Mingjie Sun et al.
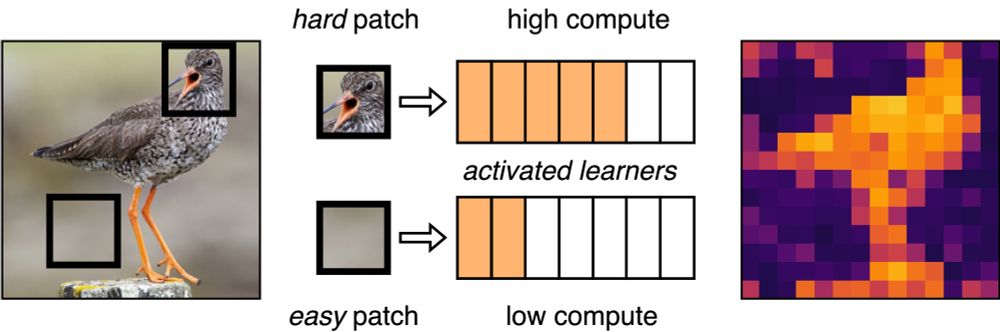
In Vision & Audio transformers, not all tokens need the same compute resources! We propose “modular learners” to control compute at token-level granularity (MHA & MLP): hard tokens get more, easy ones get less!
w/ @sscardapane.bsky.social @neuralnoise.com @bartoszWojcik
Soon #AAAI25
Link 👇
w/ @sscardapane.bsky.social @neuralnoise.com @bartoszWojcik
Soon #AAAI25
Link 👇
December 19, 2024 at 4:33 PM
In Vision & Audio transformers, not all tokens need the same compute resources! We propose “modular learners” to control compute at token-level granularity (MHA & MLP): hard tokens get more, easy ones get less!
w/ @sscardapane.bsky.social @neuralnoise.com @bartoszWojcik
Soon #AAAI25
Link 👇
w/ @sscardapane.bsky.social @neuralnoise.com @bartoszWojcik
Soon #AAAI25
Link 👇
Cool take on straight-through-estimator (to backpropagate through discrete ops): during back-propagation, keep gradient's relative angle, not absolute direction. The authors call this the "rotation trick".
From "Restructuring Vector Quantization With The Rotation Trick" @ChristopherFifty et al.
From "Restructuring Vector Quantization With The Rotation Trick" @ChristopherFifty et al.

December 4, 2024 at 10:13 AM
Cool take on straight-through-estimator (to backpropagate through discrete ops): during back-propagation, keep gradient's relative angle, not absolute direction. The authors call this the "rotation trick".
From "Restructuring Vector Quantization With The Rotation Trick" @ChristopherFifty et al.
From "Restructuring Vector Quantization With The Rotation Trick" @ChristopherFifty et al.
New and very cool library!👏 Our L2 Norm-based KV Cache compression is already implemented - ready to use! 🚀
Check out the method details in our EMNLP '24 paper: arxiv.org/abs/2406.11430
Check out the method details in our EMNLP '24 paper: arxiv.org/abs/2406.11430

November 20, 2024 at 9:57 AM
New and very cool library!👏 Our L2 Norm-based KV Cache compression is already implemented - ready to use! 🚀
Check out the method details in our EMNLP '24 paper: arxiv.org/abs/2406.11430
Check out the method details in our EMNLP '24 paper: arxiv.org/abs/2406.11430
*Tokenformer: Rethinking Transformer Scaling With Tokenized Model Parameters* arxiv.org/pdf/2410.23168
Very cool transformer-inspired architecture where linear layers are replaced with token-parameter attention (Pattention). This allows for efficient scaling by adding new parameters to the model.
Very cool transformer-inspired architecture where linear layers are replaced with token-parameter attention (Pattention). This allows for efficient scaling by adding new parameters to the model.

November 18, 2024 at 4:56 PM
*Tokenformer: Rethinking Transformer Scaling With Tokenized Model Parameters* arxiv.org/pdf/2410.23168
Very cool transformer-inspired architecture where linear layers are replaced with token-parameter attention (Pattention). This allows for efficient scaling by adding new parameters to the model.
Very cool transformer-inspired architecture where linear layers are replaced with token-parameter attention (Pattention). This allows for efficient scaling by adding new parameters to the model.