




aicoffeebreak.bsky.social
@aicoffeebreak.bsky.social
📺 ML Youtuber http://youtube.com/AICoffeeBreak
👩🎓 PhD student in Computational Linguistics @ Heidelberg University |
Impressum: https://t1p.de/q93um
👩🎓 PhD student in Computational Linguistics @ Heidelberg University |
Impressum: https://t1p.de/q93um
LLMs can memorize even a phone number seen once in training.🔒
Google’s VaultGemma fixes that, being the first open-weight LLM trained from scratch with differential privacy, so rare secrets leave no trace.
☕ new video explaining Differential Privacy through VaultGemma 👇
🎥 youtu.be/UwX5zzjwb_g
Google’s VaultGemma fixes that, being the first open-weight LLM trained from scratch with differential privacy, so rare secrets leave no trace.
☕ new video explaining Differential Privacy through VaultGemma 👇
🎥 youtu.be/UwX5zzjwb_g

What's up with Google's new VaultGemma model? – Differential Privacy explained
YouTube video by AI Coffee Break with Letitia
youtu.be
November 2, 2025 at 1:28 PM
LLMs can memorize even a phone number seen once in training.🔒
Google’s VaultGemma fixes that, being the first open-weight LLM trained from scratch with differential privacy, so rare secrets leave no trace.
☕ new video explaining Differential Privacy through VaultGemma 👇
🎥 youtu.be/UwX5zzjwb_g
Google’s VaultGemma fixes that, being the first open-weight LLM trained from scratch with differential privacy, so rare secrets leave no trace.
☕ new video explaining Differential Privacy through VaultGemma 👇
🎥 youtu.be/UwX5zzjwb_g
We explain diffusion models and flow-matching models side by side. Flow-Matching models are the new generation of AI image generators that are quickly replacing diffusion models. They take everything diffusion did well, but make it faster, smoother, and deterministic.
🎥 youtu.be/firXjwZ_6KI
🎥 youtu.be/firXjwZ_6KI

Diffusion Models and Flow-Matching explained side by side
YouTube video by AI Coffee Break with Letitia
youtu.be
October 19, 2025 at 12:20 PM
We explain diffusion models and flow-matching models side by side. Flow-Matching models are the new generation of AI image generators that are quickly replacing diffusion models. They take everything diffusion did well, but make it faster, smoother, and deterministic.
🎥 youtu.be/firXjwZ_6KI
🎥 youtu.be/firXjwZ_6KI
Ever wondered how Energy-Based Models (EBMs) work and how they differ from normal neural networks?
☕️ We go over EBMs and then dive into the Energy-Based Transformers paper to make LLMs that refine guesses, self-verify, and could adapt compute to problem difficulty.
☕️ We go over EBMs and then dive into the Energy-Based Transformers paper to make LLMs that refine guesses, self-verify, and could adapt compute to problem difficulty.

September 21, 2025 at 12:48 PM
Ever wondered how Energy-Based Models (EBMs) work and how they differ from normal neural networks?
☕️ We go over EBMs and then dive into the Energy-Based Transformers paper to make LLMs that refine guesses, self-verify, and could adapt compute to problem difficulty.
☕️ We go over EBMs and then dive into the Energy-Based Transformers paper to make LLMs that refine guesses, self-verify, and could adapt compute to problem difficulty.
The world’s largest NLP conference with almost 2,000 papers presented, ACL 2025 just took place in Vienna! 🎓✨ Here is a quick snapshot of the event via a short interview with one of the authors whose work caught my attention.
🎥 Watch: youtu.be/GBISWggsQOA
🎥 Watch: youtu.be/GBISWggsQOA

September 14, 2025 at 11:49 AM
The world’s largest NLP conference with almost 2,000 papers presented, ACL 2025 just took place in Vienna! 🎓✨ Here is a quick snapshot of the event via a short interview with one of the authors whose work caught my attention.
🎥 Watch: youtu.be/GBISWggsQOA
🎥 Watch: youtu.be/GBISWggsQOA
My friend Vivi Nastase is working on a short science communication film called "Puppets of a Digital Brain". It aims to explain the tech behind AI chatbots (the good, the bad, the environmental) in an accessible, visual way.
💡 GoFundMe: gofund.me/453ed662
💡 GoFundMe: gofund.me/453ed662

August 5, 2025 at 6:36 PM
My friend Vivi Nastase is working on a short science communication film called "Puppets of a Digital Brain". It aims to explain the tech behind AI chatbots (the good, the bad, the environmental) in an accessible, visual way.
💡 GoFundMe: gofund.me/453ed662
💡 GoFundMe: gofund.me/453ed662
How do LLMs pick the next word? They don’t choose words directly: they only output word probabilities. 📊 Greedy decoding, top-k, top-p, min-p are methods that turn these probabilities into actual text.

August 3, 2025 at 12:06 PM
How do LLMs pick the next word? They don’t choose words directly: they only output word probabilities. 📊 Greedy decoding, top-k, top-p, min-p are methods that turn these probabilities into actual text.
Excited to be at ACL 2025 in Vienna this week 🇦🇹 #ACL2025
I’m always up for a chat about reasoning models, NLE faithfulness, synthetic data generation, or the joys and challenges of explaining AI on YouTube.
If you're around, let’s connect!
I’m always up for a chat about reasoning models, NLE faithfulness, synthetic data generation, or the joys and challenges of explaining AI on YouTube.
If you're around, let’s connect!

July 27, 2025 at 12:20 PM
Excited to be at ACL 2025 in Vienna this week 🇦🇹 #ACL2025
I’m always up for a chat about reasoning models, NLE faithfulness, synthetic data generation, or the joys and challenges of explaining AI on YouTube.
If you're around, let’s connect!
I’m always up for a chat about reasoning models, NLE faithfulness, synthetic data generation, or the joys and challenges of explaining AI on YouTube.
If you're around, let’s connect!
🤖 Can we trust AI in science?
I'm excited to be speaking at the final event of the Young Marsilius Fellows 2025, themed "Dancing with Right & Wrong?" – a title that feels increasingly relevant these days.
I'll be joining a panel on "(How) can we trust AI in science?" to discuss questions like:
I'm excited to be speaking at the final event of the Young Marsilius Fellows 2025, themed "Dancing with Right & Wrong?" – a title that feels increasingly relevant these days.
I'll be joining a panel on "(How) can we trust AI in science?" to discuss questions like:
July 7, 2025 at 5:03 PM
🤖 Can we trust AI in science?
I'm excited to be speaking at the final event of the Young Marsilius Fellows 2025, themed "Dancing with Right & Wrong?" – a title that feels increasingly relevant these days.
I'll be joining a panel on "(How) can we trust AI in science?" to discuss questions like:
I'm excited to be speaking at the final event of the Young Marsilius Fellows 2025, themed "Dancing with Right & Wrong?" – a title that feels increasingly relevant these days.
I'll be joining a panel on "(How) can we trust AI in science?" to discuss questions like:
We train AI on human-selected or -generated data (yes, even taking a photo is concept selection – we capture what we find interesting; text even more so, expressing our conceptualisation of the world). Then we’re surprised when the AI's concepts and representations are similar to ours. 🤷♀️

June 20, 2025 at 3:25 PM
We train AI on human-selected or -generated data (yes, even taking a photo is concept selection – we capture what we find interesting; text even more so, expressing our conceptualisation of the world). Then we’re surprised when the AI's concepts and representations are similar to ours. 🤷♀️
Reposted by aicoffeebreak.bsky.social

I'm very excited to finally share the main work of my PhD!
We explored the evolutionary dynamics of gene regulation and expression during gonad development in primates. We cover among others: X chromosome dynamics (incl. in a developing XXY testis), gene regulatory networks and cell type evolution.
We explored the evolutionary dynamics of gene regulation and expression during gonad development in primates. We cover among others: X chromosome dynamics (incl. in a developing XXY testis), gene regulatory networks and cell type evolution.

We are delighted to share our new preprint “The evolution of gene regulatory programs controlling gonadal development in primates” www.biorxiv.org/content/10.1...
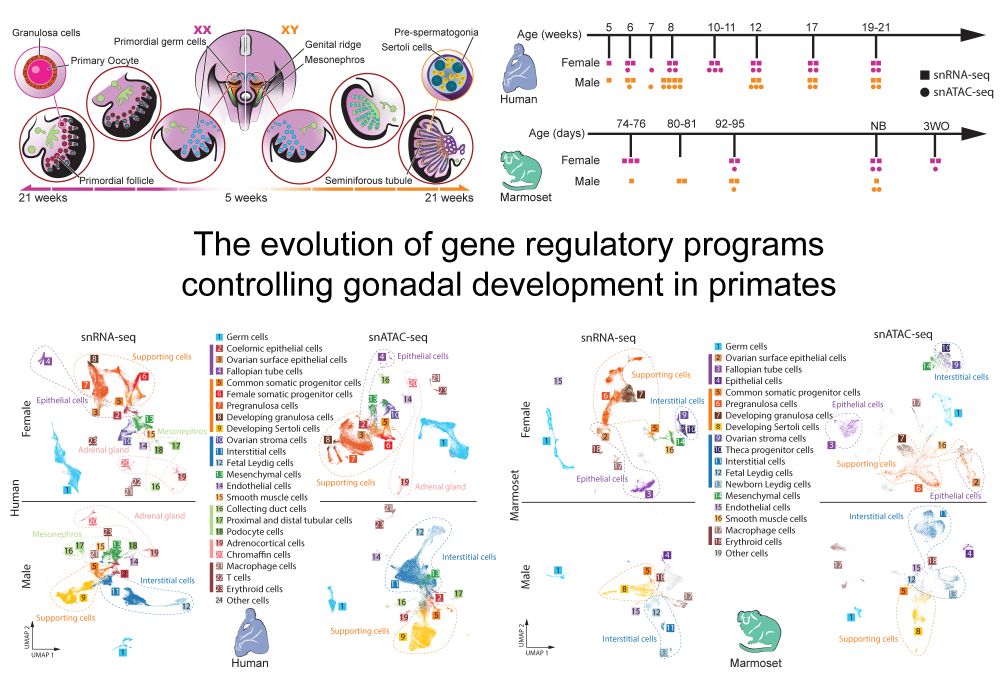
June 20, 2025 at 8:37 AM
I'm very excited to finally share the main work of my PhD!
We explored the evolutionary dynamics of gene regulation and expression during gonad development in primates. We cover among others: X chromosome dynamics (incl. in a developing XXY testis), gene regulatory networks and cell type evolution.
We explored the evolutionary dynamics of gene regulation and expression during gonad development in primates. We cover among others: X chromosome dynamics (incl. in a developing XXY testis), gene regulatory networks and cell type evolution.
💡 AlphaEvolve is a new AI system that doesn’t just write code, it evolves it. It uses LLMs and evolutionary search to make scientific discoveries.
We explain how AlphaEvolve works and the evolutionary strategies behind it (like MAP-Elites and island-based population methods).
📺 youtu.be/Z4uF6cVly8o
We explain how AlphaEvolve works and the evolutionary strategies behind it (like MAP-Elites and island-based population methods).
📺 youtu.be/Z4uF6cVly8o

AlphaEvolve: Using LLMs to solve Scientific and Engineering Challenges | AlphaEvolve explained
YouTube video by AI Coffee Break with Letitia
youtu.be
June 19, 2025 at 1:00 PM
💡 AlphaEvolve is a new AI system that doesn’t just write code, it evolves it. It uses LLMs and evolutionary search to make scientific discoveries.
We explain how AlphaEvolve works and the evolutionary strategies behind it (like MAP-Elites and island-based population methods).
📺 youtu.be/Z4uF6cVly8o
We explain how AlphaEvolve works and the evolutionary strategies behind it (like MAP-Elites and island-based population methods).
📺 youtu.be/Z4uF6cVly8o
Excited to share that I’ll be joining the Summer School “AI and Human Values” this September at the Marsilius-Kolleg of Heidelberg University as a speaker. I'll be giving an introduction to how large language models actually work—before the summer school dives deeper into broader implications.

May 31, 2025 at 11:47 AM
Excited to share that I’ll be joining the Summer School “AI and Human Values” this September at the Marsilius-Kolleg of Heidelberg University as a speaker. I'll be giving an introduction to how large language models actually work—before the summer school dives deeper into broader implications.
Long videos are a nightmare for language models—too many tokens, slow inference. ☠️
We explain STORM ⛈️, a new architecture that improves long video LLMs using Mamba layers and token compression. Reaches better accuracy than GPT-4o on benchmarks and up to 8× more efficiency.
📺 youtu.be/uMk3VN4S8TQ
We explain STORM ⛈️, a new architecture that improves long video LLMs using Mamba layers and token compression. Reaches better accuracy than GPT-4o on benchmarks and up to 8× more efficiency.
📺 youtu.be/uMk3VN4S8TQ

Token-Efficient Long Video Understanding for Multimodal LLMs | Paper explained
YouTube video by AI Coffee Break with Letitia
youtu.be
May 18, 2025 at 12:02 PM
Long videos are a nightmare for language models—too many tokens, slow inference. ☠️
We explain STORM ⛈️, a new architecture that improves long video LLMs using Mamba layers and token compression. Reaches better accuracy than GPT-4o on benchmarks and up to 8× more efficiency.
📺 youtu.be/uMk3VN4S8TQ
We explain STORM ⛈️, a new architecture that improves long video LLMs using Mamba layers and token compression. Reaches better accuracy than GPT-4o on benchmarks and up to 8× more efficiency.
📺 youtu.be/uMk3VN4S8TQ
Reposted by aicoffeebreak.bsky.social

Follow @aicoffeebreak.bsky.social!! Letitia is very effective in communicating research papers in just a few mins! Perfect for your coffee break. 😉
May 17, 2025 at 12:51 AM
Follow @aicoffeebreak.bsky.social!! Letitia is very effective in communicating research papers in just a few mins! Perfect for your coffee break. 😉
We all know quantization works at inference time, but researchers successfully trained a 13B LLaMA 2 model using FP4 precision (only 16 values per weight!). 🤯
We break down how it works. If quantization and mixed-precision training sounds mysterious, this’ll clear it up.
📺 youtu.be/Ue3AK4mCYYg
We break down how it works. If quantization and mixed-precision training sounds mysterious, this’ll clear it up.
📺 youtu.be/Ue3AK4mCYYg

4-Bit Training for Billion-Parameter LLMs? Yes, Really.
YouTube video by AI Coffee Break with Letitia
youtu.be
April 18, 2025 at 12:11 PM
We all know quantization works at inference time, but researchers successfully trained a 13B LLaMA 2 model using FP4 precision (only 16 values per weight!). 🤯
We break down how it works. If quantization and mixed-precision training sounds mysterious, this’ll clear it up.
📺 youtu.be/Ue3AK4mCYYg
We break down how it works. If quantization and mixed-precision training sounds mysterious, this’ll clear it up.
📺 youtu.be/Ue3AK4mCYYg
Just say “Wait…” – and your LLM gets smarter?!
We explain how just 1,000 training examples + a tiny trick at inference time = o1-preview level reasoning. No RL, no massive data needed.
🎥 Watch now → youtu.be/XuH2QTAC5yI
We explain how just 1,000 training examples + a tiny trick at inference time = o1-preview level reasoning. No RL, no massive data needed.
🎥 Watch now → youtu.be/XuH2QTAC5yI

s1: Simple test-time scaling: Just “wait…” + 1,000 training examples? | PAPER EXPLAINED
YouTube video by AI Coffee Break with Letitia
youtu.be
March 23, 2025 at 12:58 PM
Just say “Wait…” – and your LLM gets smarter?!
We explain how just 1,000 training examples + a tiny trick at inference time = o1-preview level reasoning. No RL, no massive data needed.
🎥 Watch now → youtu.be/XuH2QTAC5yI
We explain how just 1,000 training examples + a tiny trick at inference time = o1-preview level reasoning. No RL, no massive data needed.
🎥 Watch now → youtu.be/XuH2QTAC5yI
🎙️ Yesterday, I gave a keynote on large language models outfitted with visual understanding, and the faithfulness of their chain-of-thought reasoning at the National Conference on Governing the Digital Society and Human-Centered AI.

February 1, 2025 at 1:13 PM
🎙️ Yesterday, I gave a keynote on large language models outfitted with visual understanding, and the faithfulness of their chain-of-thought reasoning at the National Conference on Governing the Digital Society and Human-Centered AI.
Reposted by aicoffeebreak.bsky.social

The National Conference on AI Transformations: Language, Technology, and Society organised by Utrecht University @utrechtuniversity.bsky.social was a success, and indeed Letiția‘s @aicoffeebreak.bsky.social talk was very inspiring.

It was very nice seeing @aicoffeebreak.bsky.social again after many years😊 She gave a wonderful keynote at the Railway Museum in Utrecht, as part of the National Conference on AI Transformations!💫



February 1, 2025 at 12:27 PM
The National Conference on AI Transformations: Language, Technology, and Society organised by Utrecht University @utrechtuniversity.bsky.social was a success, and indeed Letiția‘s @aicoffeebreak.bsky.social talk was very inspiring.
Reposted by aicoffeebreak.bsky.social

🎉 Exciting news from our team!
The final paper of @aicoffeebreak.bsky.social's PhD journey is accepted at #ICLR2025! 🙌 🖼️📄
Check out her original post below for more details on Vision & Language Models (VLMs), their modality use and their self-consistency 🔥
The final paper of @aicoffeebreak.bsky.social's PhD journey is accepted at #ICLR2025! 🙌 🖼️📄
Check out her original post below for more details on Vision & Language Models (VLMs), their modality use and their self-consistency 🔥
The last paper of my PhD is accepted at ICLR 2025! 🙌 🎊
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇

Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Vision and language model (VLM) decoders are currently the best-performing architectures on multimodal tasks. Next to answers, they are able to produce natural language explanations, either in post-ho...
arxiv.org
January 27, 2025 at 1:04 PM
🎉 Exciting news from our team!
The final paper of @aicoffeebreak.bsky.social's PhD journey is accepted at #ICLR2025! 🙌 🖼️📄
Check out her original post below for more details on Vision & Language Models (VLMs), their modality use and their self-consistency 🔥
The final paper of @aicoffeebreak.bsky.social's PhD journey is accepted at #ICLR2025! 🙌 🖼️📄
Check out her original post below for more details on Vision & Language Models (VLMs), their modality use and their self-consistency 🔥
We explain 🥥COCONUT (Chain of Continuous Thought), a new paper using vectors for CoT instead of words. We break down:
- Why CoT with words might not be optimal.
- How to implement vectors for CoT instead words and make CoT faster.
- What this means for interpretability.
📺 youtu.be/mhKC3Avqy2E
- Why CoT with words might not be optimal.
- How to implement vectors for CoT instead words and make CoT faster.
- What this means for interpretability.
📺 youtu.be/mhKC3Avqy2E

COCONUT: Training large language models to reason in a continuous latent space – Paper explained
YouTube video by AI Coffee Break with Letitia
youtu.be
January 26, 2025 at 1:20 PM
We explain 🥥COCONUT (Chain of Continuous Thought), a new paper using vectors for CoT instead of words. We break down:
- Why CoT with words might not be optimal.
- How to implement vectors for CoT instead words and make CoT faster.
- What this means for interpretability.
📺 youtu.be/mhKC3Avqy2E
- Why CoT with words might not be optimal.
- How to implement vectors for CoT instead words and make CoT faster.
- What this means for interpretability.
📺 youtu.be/mhKC3Avqy2E
The last paper of my PhD is accepted at ICLR 2025! 🙌 🎊
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇
Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
Vision and language model (VLM) decoders are currently the best-performing architectures on multimodal tasks. Next to answers, they are able to produce natural language explanations, either in post-ho...
arxiv.org
January 22, 2025 at 7:40 PM
The last paper of my PhD is accepted at ICLR 2025! 🙌 🎊
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇
We investigate the reliance of modern Vision & Language Models (VLMs) on image🖼️ vs. text📄 inputs when generating answers vs. explanations, revealing fascinating insights into their modality use and self-consistency. Takeaways: 👇
An educational and a bit historical deep dive into LLM research.
💡Learn what breakthroughs since 2017 paved the way for AI like ChatGPT (it wasn't overnight). We go through:
* Transformers
* Prompting
* Human Feedback, etc. and break it all down for you! 👇
📺 youtu.be/BprirYymXrg
💡Learn what breakthroughs since 2017 paved the way for AI like ChatGPT (it wasn't overnight). We go through:
* Transformers
* Prompting
* Human Feedback, etc. and break it all down for you! 👇
📺 youtu.be/BprirYymXrg

LLMs Explained: A Deep Dive into Transformers, Prompts, and Human Feedback
YouTube video by AI Coffee Break with Letitia
youtu.be
January 19, 2025 at 1:06 PM
An educational and a bit historical deep dive into LLM research.
💡Learn what breakthroughs since 2017 paved the way for AI like ChatGPT (it wasn't overnight). We go through:
* Transformers
* Prompting
* Human Feedback, etc. and break it all down for you! 👇
📺 youtu.be/BprirYymXrg
💡Learn what breakthroughs since 2017 paved the way for AI like ChatGPT (it wasn't overnight). We go through:
* Transformers
* Prompting
* Human Feedback, etc. and break it all down for you! 👇
📺 youtu.be/BprirYymXrg
Reposted by aicoffeebreak.bsky.social

Transformer language models like Chat GPT, when using chain-of-thought reasoning, are Turing complete. Specifically, they can execute probabilistic algorithms and generate any computable weighted language
youtu.be/MMIJKKNxvec?...
youtu.be/MMIJKKNxvec?...

Transformer LLMs are Turing Complete after all !?
YouTube video by AI Coffee Break with Letitia
youtu.be
November 18, 2024 at 2:32 PM
Transformer language models like Chat GPT, when using chain-of-thought reasoning, are Turing complete. Specifically, they can execute probabilistic algorithms and generate any computable weighted language
youtu.be/MMIJKKNxvec?...
youtu.be/MMIJKKNxvec?...
Don't forget to register! 🤭👇

📅 Artificial Intelligence: Which skills do I need?
🎤 Dr. Letiția Pârcălăbescu and Paolo Celot
🕒 04 February 2024, 15:00-16:30 (CET, Brussels)
🖥️ Don’t miss this chance to boost your AI literacy and media skills!
🔗 Registration is required and can be done here: forms.gle/vhbSt2gzLe1m...
🎤 Dr. Letiția Pârcălăbescu and Paolo Celot
🕒 04 February 2024, 15:00-16:30 (CET, Brussels)
🖥️ Don’t miss this chance to boost your AI literacy and media skills!
🔗 Registration is required and can be done here: forms.gle/vhbSt2gzLe1m...

January 9, 2025 at 5:43 PM
Don't forget to register! 🤭👇
New video about:
REPA (Representation Alignment), a clever trick to align diffusion transformers’ representations with pretrained transformers like DINOv2.
It accelerates training and improves the diff. model’s ability to do things other than image generation (like image classification).
REPA (Representation Alignment), a clever trick to align diffusion transformers’ representations with pretrained transformers like DINOv2.
It accelerates training and improves the diff. model’s ability to do things other than image generation (like image classification).

REPA Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You ...
YouTube video by AI Coffee Break with Letitia
youtu.be
December 8, 2024 at 2:05 PM
New video about:
REPA (Representation Alignment), a clever trick to align diffusion transformers’ representations with pretrained transformers like DINOv2.
It accelerates training and improves the diff. model’s ability to do things other than image generation (like image classification).
REPA (Representation Alignment), a clever trick to align diffusion transformers’ representations with pretrained transformers like DINOv2.
It accelerates training and improves the diff. model’s ability to do things other than image generation (like image classification).