




Andreas Hochlehnert
@ahochlehnert.bsky.social
PhD student in ML at Tübingen AI Center & International Max-Planck Research School for Intelligent Systems
5/ What actually works?
🔹 RL methods over distillations? Often negligible gains, prone to overfitting.
🔹 Supervised finetuning (SFT) on reasoning traces? Stable & generalizable.
🔹 RL methods over distillations? Often negligible gains, prone to overfitting.
🔹 Supervised finetuning (SFT) on reasoning traces? Stable & generalizable.

April 10, 2025 at 3:38 PM
5/ What actually works?
🔹 RL methods over distillations? Often negligible gains, prone to overfitting.
🔹 Supervised finetuning (SFT) on reasoning traces? Stable & generalizable.
🔹 RL methods over distillations? Often negligible gains, prone to overfitting.
🔹 Supervised finetuning (SFT) on reasoning traces? Stable & generalizable.
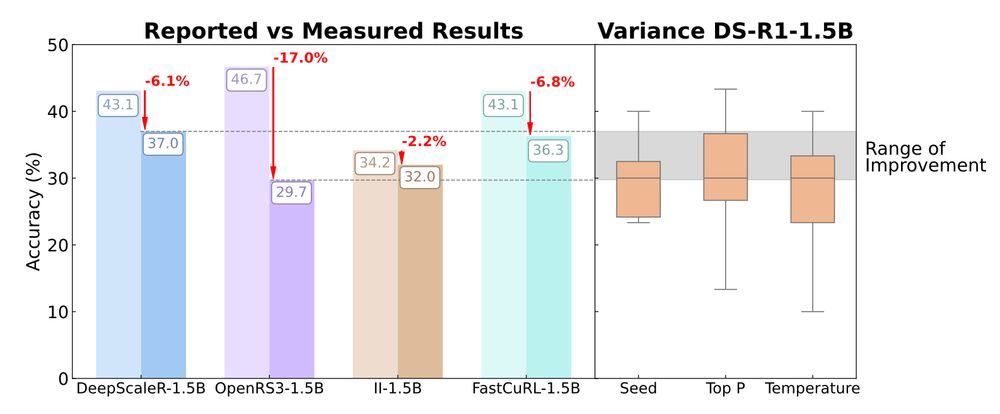
4/ Variance is everywhere:
– Random seed: swings Pass@1 by 5–15pp
– Temperature/top-p: another ±10pp
– Software & Hardware? Yes, even that changes scores
🎯 Single-seed results on small datasets are essentially noise.
– Random seed: swings Pass@1 by 5–15pp
– Temperature/top-p: another ±10pp
– Software & Hardware? Yes, even that changes scores
🎯 Single-seed results on small datasets are essentially noise.

April 10, 2025 at 3:37 PM
4/ Variance is everywhere:
– Random seed: swings Pass@1 by 5–15pp
– Temperature/top-p: another ±10pp
– Software & Hardware? Yes, even that changes scores
🎯 Single-seed results on small datasets are essentially noise.
– Random seed: swings Pass@1 by 5–15pp
– Temperature/top-p: another ±10pp
– Software & Hardware? Yes, even that changes scores
🎯 Single-seed results on small datasets are essentially noise.
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
April 10, 2025 at 3:36 PM
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
🔸 Some questions reference figures that aren't included! Text-only models can't infer missing visuals. [4/6]

February 17, 2025 at 6:25 PM
🔸 Some questions reference figures that aren't included! Text-only models can't infer missing visuals. [4/6]
🔸 Mathematical proofs are a challenge. There's no automated way to verify them, and answers often only show an initial equation, leading to unreliable training signals. [3/6]

February 17, 2025 at 6:25 PM
🔸 Mathematical proofs are a challenge. There's no automated way to verify them, and answers often only show an initial equation, leading to unreliable training signals. [3/6]
Blog (For Updates): huggingface.co/datasets/bet...
🔸 Some questions contain subquestions, but only one answer is labeled. The model may get penalized for "wrong" but valid reasoning. [2/6]
🔸 Some questions contain subquestions, but only one answer is labeled. The model may get penalized for "wrong" but valid reasoning. [2/6]

February 17, 2025 at 6:24 PM
Blog (For Updates): huggingface.co/datasets/bet...
🔸 Some questions contain subquestions, but only one answer is labeled. The model may get penalized for "wrong" but valid reasoning. [2/6]
🔸 Some questions contain subquestions, but only one answer is labeled. The model may get penalized for "wrong" but valid reasoning. [2/6]