



Adrian Haith
@adrianhaith.bsky.social
Motor Control and Motor Learning
Lastly, I should add -- I'm not the first to propose policy gradient RL for modeling human motor learning. Check out @nidhise.bsky.social 's excellent paper arguing for policy-gradient RL in locomotor learning:

link to our paper: www.nature.com/articles/s41...

Exploration-based learning of a stabilizing controller predicts locomotor adaptation - Nature Communications
People learn to walk better over time in novel situations, such as walking with new shoes. Here, the authors show that such adaptive behavior relies on a stabilizer that reacts quickly to keep the wal...
www.nature.com
October 29, 2025 at 6:54 PM
Lastly, I should add -- I'm not the first to propose policy gradient RL for modeling human motor learning. Check out @nidhise.bsky.social 's excellent paper arguing for policy-gradient RL in locomotor learning:
I suspect we stand to learn more from the roboticists than the other way around. Progress there is accelerating rapidly! But maybe there will be insights that can go in the other direction too. I think it’s a very interesting direction to explore!
October 24, 2025 at 12:50 AM
I suspect we stand to learn more from the roboticists than the other way around. Progress there is accelerating rapidly! But maybe there will be insights that can go in the other direction too. I think it’s a very interesting direction to explore!
Yes. A lot of these challenges are being addressed already in robotics, with basically PG methods. I believe that ultimately policy gradient + smart/adaptive curriculum/reward function can get you pretty far. That latter part is the real role of cognition in skill learning.
October 21, 2025 at 2:34 AM
Yes. A lot of these challenges are being addressed already in robotics, with basically PG methods. I believe that ultimately policy gradient + smart/adaptive curriculum/reward function can get you pretty far. That latter part is the real role of cognition in skill learning.
I'm certainly not proposing this as a "Theory of Everything", but rather as an alternative foundation to error-based models of learning. Very feasible I hope to extend the theory in future to account for the kinds of things you mention. And some things may even make more sense from this perspective.
October 21, 2025 at 2:24 AM
I'm certainly not proposing this as a "Theory of Everything", but rather as an alternative foundation to error-based models of learning. Very feasible I hope to extend the theory in future to account for the kinds of things you mention. And some things may even make more sense from this perspective.
As for contextual interference, savings etc. Those things are increasingly viewed as occurring at the level of retrieval and/or separation of policies across tasks, rather than low-level learning rules. In that case, it's quite compatible with the underlying policy learning rule being model-free RL
October 21, 2025 at 2:17 AM
As for contextual interference, savings etc. Those things are increasingly viewed as occurring at the level of retrieval and/or separation of policies across tasks, rather than low-level learning rules. In that case, it's quite compatible with the underlying policy learning rule being model-free RL
Offline learning could be easily explained through replay - RL applications in robotics etc. do exactly this, and there's plenty of evidence something like this occurs during sleep. So it's very compatible with that.
October 21, 2025 at 2:13 AM
Offline learning could be easily explained through replay - RL applications in robotics etc. do exactly this, and there's plenty of evidence something like this occurs during sleep. So it's very compatible with that.
Thanks, JJ. It doesn't directly predict those things. In our experiments, we actually haven't found there to be much forgetting of skills you learn through practice. People retain pretty much everything in our de novo task, even after a year: drive.google.com/file/d/11M0l...
October 21, 2025 at 2:09 AM
Thanks, JJ. It doesn't directly predict those things. In our experiments, we actually haven't found there to be much forgetting of skills you learn through practice. People retain pretty much everything in our de novo task, even after a year: drive.google.com/file/d/11M0l...
Please check out the paper for more details and hopefully an accessible intro to policy-gradient RL if you’re not familiar with it. I welcome any feedback.
If you’d like to dabble with the models, code for all simulations is available at: github.com/adrianhaith/PolicyGradientSkillLearning
/End.
If you’d like to dabble with the models, code for all simulations is available at: github.com/adrianhaith/PolicyGradientSkillLearning
/End.
October 20, 2025 at 3:19 PM
Please check out the paper for more details and hopefully an accessible intro to policy-gradient RL if you’re not familiar with it. I welcome any feedback.
If you’d like to dabble with the models, code for all simulations is available at: github.com/adrianhaith/PolicyGradientSkillLearning
/End.
If you’d like to dabble with the models, code for all simulations is available at: github.com/adrianhaith/PolicyGradientSkillLearning
/End.
I’m excited about the potential of this approach. Progress on understanding the kinds of motor learning that really matters for sports, rehab, and development, has been pretty limited in recent decades. I’m hopeful that a concrete and simple computational theory can help spur progress.
October 20, 2025 at 3:18 PM
I’m excited about the potential of this approach. Progress on understanding the kinds of motor learning that really matters for sports, rehab, and development, has been pretty limited in recent decades. I’m hopeful that a concrete and simple computational theory can help spur progress.
And in a precision movement task, requiring precise, speeded movements through an arc-shaped channel (Shmuelof, Krakauer & Mazzoni, 2012):

October 20, 2025 at 3:09 PM
And in a precision movement task, requiring precise, speeded movements through an arc-shaped channel (Shmuelof, Krakauer & Mazzoni, 2012):
In a cursor-control task with a highly non-intuitive mapping (often described as “de novo” learning, since it requires learning a brand new controller rather than adapting an existing one; Haith, Yang, Pakpoor & Kita, 2002):

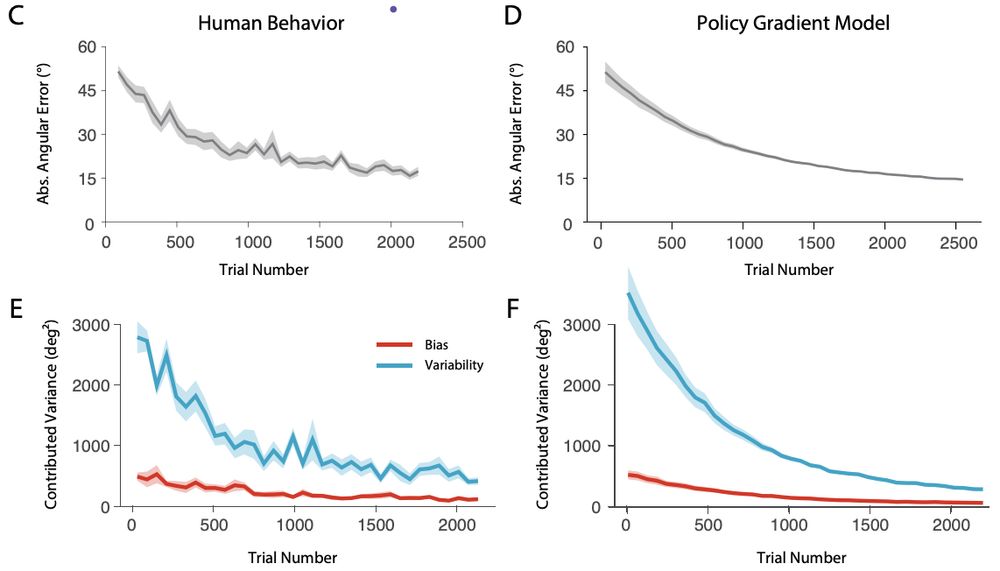
October 20, 2025 at 3:08 PM
In a cursor-control task with a highly non-intuitive mapping (often described as “de novo” learning, since it requires learning a brand new controller rather than adapting an existing one; Haith, Yang, Pakpoor & Kita, 2002):
Across three quite different tasks, policy-gradient RL models of learning account very well for the patterns of improvement in the mean and variance of people’s actions across a range of tasks.
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):


October 20, 2025 at 3:04 PM
Across three quite different tasks, policy-gradient RL models of learning account very well for the patterns of improvement in the mean and variance of people’s actions across a range of tasks.
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
Policy-gradient RL is a simple, model-free RL method that is a pillar of impressive recent advances in robotics. Here, I show that a trial-by-trial learning rule based on policy-gradient RL accounts remarkably well for the way people improve at a skill through practice.

October 20, 2025 at 3:02 PM
Policy-gradient RL is a simple, model-free RL method that is a pillar of impressive recent advances in robotics. Here, I show that a trial-by-trial learning rule based on policy-gradient RL accounts remarkably well for the way people improve at a skill through practice.
I agree there are other cons that have a more subtle impact and will be harder to mitigate - like failure to properly cite or attribute ideas, or potentially leading everyone up the same path. Those are the ones to be concerned about, not so much AI hallucination/confabulation.
September 6, 2025 at 3:06 PM
I agree there are other cons that have a more subtle impact and will be harder to mitigate - like failure to properly cite or attribute ideas, or potentially leading everyone up the same path. Those are the ones to be concerned about, not so much AI hallucination/confabulation.
I would say a “bad” AI user is someone who uses it without being wary of its limitations and without properly validating its output. I expect most scientists to be capable of using AI with appropriate skepticism of its output.
September 6, 2025 at 3:03 PM
I would say a “bad” AI user is someone who uses it without being wary of its limitations and without properly validating its output. I expect most scientists to be capable of using AI with appropriate skepticism of its output.
Bad, lazy scientists are nothing new, but they are a small minority. I'm confident most of us will be able to use it wisely to make our science better
September 5, 2025 at 7:37 PM
Bad, lazy scientists are nothing new, but they are a small minority. I'm confident most of us will be able to use it wisely to make our science better
So many pros. Most 'cons' are avoidable by basic common sense: don't just blindly assume that what it outputs is correct or true. The alarmism seems to be all about how *other* people will use it - bad, lazy scientists using it to do bad, lazy science.
September 5, 2025 at 7:35 PM
So many pros. Most 'cons' are avoidable by basic common sense: don't just blindly assume that what it outputs is correct or true. The alarmism seems to be all about how *other* people will use it - bad, lazy scientists using it to do bad, lazy science.