



Adrian Haith
@adrianhaith.bsky.social
Motor Control and Motor Learning
And in a precision movement task, requiring precise, speeded movements through an arc-shaped channel (Shmuelof, Krakauer & Mazzoni, 2012):

October 20, 2025 at 3:09 PM
And in a precision movement task, requiring precise, speeded movements through an arc-shaped channel (Shmuelof, Krakauer & Mazzoni, 2012):
In a cursor-control task with a highly non-intuitive mapping (often described as “de novo” learning, since it requires learning a brand new controller rather than adapting an existing one; Haith, Yang, Pakpoor & Kita, 2002):

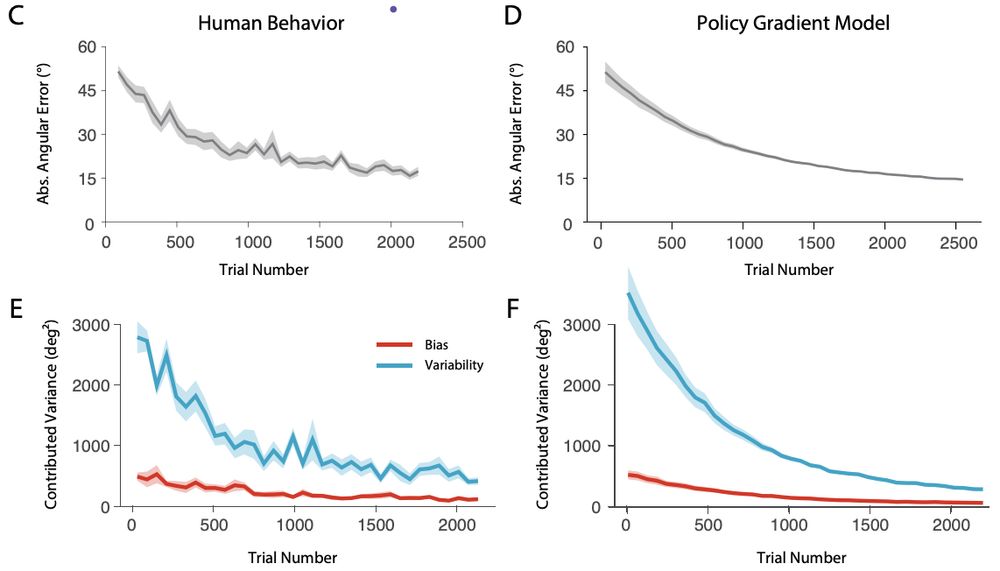
October 20, 2025 at 3:08 PM
In a cursor-control task with a highly non-intuitive mapping (often described as “de novo” learning, since it requires learning a brand new controller rather than adapting an existing one; Haith, Yang, Pakpoor & Kita, 2002):
Across three quite different tasks, policy-gradient RL models of learning account very well for the patterns of improvement in the mean and variance of people’s actions across a range of tasks.
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):


October 20, 2025 at 3:04 PM
Across three quite different tasks, policy-gradient RL models of learning account very well for the patterns of improvement in the mean and variance of people’s actions across a range of tasks.
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
In Müller and Sternad’s skittles task (Sternad, Huber, Kuznetzov, 2014):
Policy-gradient RL is a simple, model-free RL method that is a pillar of impressive recent advances in robotics. Here, I show that a trial-by-trial learning rule based on policy-gradient RL accounts remarkably well for the way people improve at a skill through practice.

October 20, 2025 at 3:02 PM
Policy-gradient RL is a simple, model-free RL method that is a pillar of impressive recent advances in robotics. Here, I show that a trial-by-trial learning rule based on policy-gradient RL accounts remarkably well for the way people improve at a skill through practice.
Just under 2 weeks left to submit your panel and individual talk proposals for #NCM2025 in Panama. Dec 2nd deadline. There's still time to put together a panel proposal if you haven't already! Details at ncm-society.org/submission/

November 19, 2024 at 7:39 PM
Just under 2 weeks left to submit your panel and individual talk proposals for #NCM2025 in Panama. Dec 2nd deadline. There's still time to put together a panel proposal if you haven't already! Details at ncm-society.org/submission/