




Yapei Chang
@yapeichang.bsky.social
☁️ phd in progress @ UMD | 🔗 https://lilakk.github.io/
🤔 Can simple string-matching metrics like BLEU rival reward models for LLM alignment?
🔍 We show that given access to a reference, BLEU can match reward models in human preference agreement, and even train LLMs competitively with them using GRPO.
🫐 Introducing BLEUBERI:
🔍 We show that given access to a reference, BLEU can match reward models in human preference agreement, and even train LLMs competitively with them using GRPO.
🫐 Introducing BLEUBERI:
May 20, 2025 at 4:25 PM
🤔 Can simple string-matching metrics like BLEU rival reward models for LLM alignment?
🔍 We show that given access to a reference, BLEU can match reward models in human preference agreement, and even train LLMs competitively with them using GRPO.
🫐 Introducing BLEUBERI:
🔍 We show that given access to a reference, BLEU can match reward models in human preference agreement, and even train LLMs competitively with them using GRPO.
🫐 Introducing BLEUBERI:
🕵️♀️ agents are strong on many tasks, but are they good at interacting with the web? 🧸our BEARCUBS benchmark shows that they struggle on interactive tasks that seem trivial to humans! 📄 check out the paper for how to build robust evaluations & directions for future agent research

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%

March 12, 2025 at 2:40 PM
🕵️♀️ agents are strong on many tasks, but are they good at interacting with the web? 🧸our BEARCUBS benchmark shows that they struggle on interactive tasks that seem trivial to humans! 📄 check out the paper for how to build robust evaluations & directions for future agent research
Reposted by Yapei Chang

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇

March 5, 2025 at 5:06 PM
Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
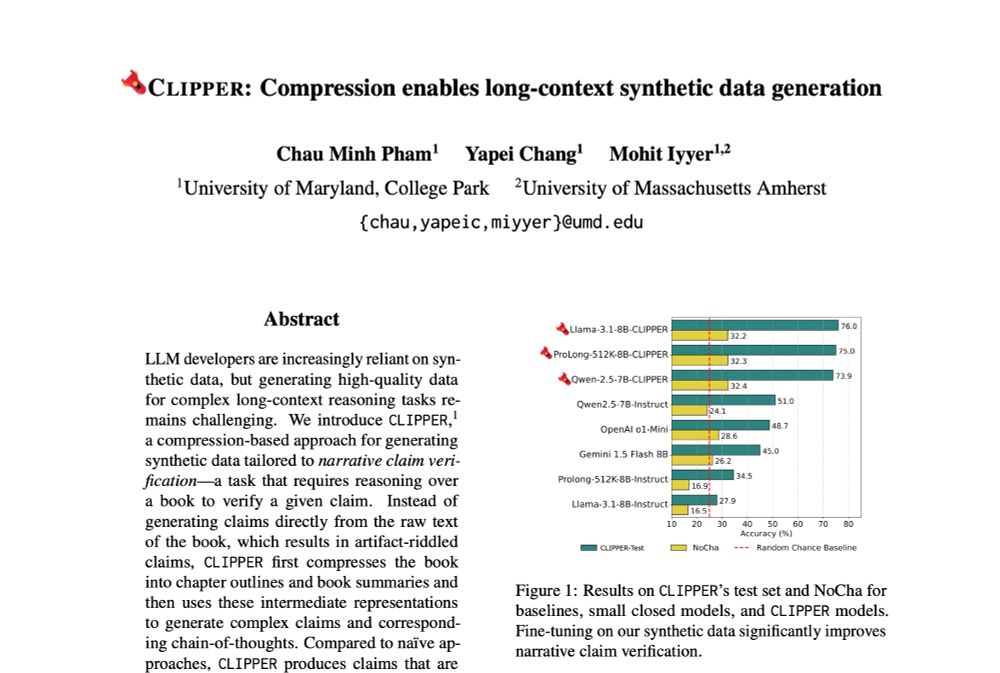
current models struggle with complex long-range reasoning tasks 📚 how can we reliably create synthetic training data?
💽 check out CLIPPER, a pipeline that generates data conditioning on compressed forms of long input documents!
💽 check out CLIPPER, a pipeline that generates data conditioning on compressed forms of long input documents!
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
February 21, 2025 at 4:30 PM
current models struggle with complex long-range reasoning tasks 📚 how can we reliably create synthetic training data?
💽 check out CLIPPER, a pipeline that generates data conditioning on compressed forms of long input documents!
💽 check out CLIPPER, a pipeline that generates data conditioning on compressed forms of long input documents!
Reposted by Yapei Chang

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

January 28, 2025 at 2:55 PM
People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Reposted by Yapei Chang

Great blog post (by a 15-author team!) on their release of ModernBERT, the continuing relevance of encoder-only models, and how they relate to, say, GPT-4/llama. Accessible enough that I might use this as an undergrad reading.

Finally, a Replacement for BERT: Introducing ModernBERT
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 19, 2024 at 7:11 PM
Great blog post (by a 15-author team!) on their release of ModernBERT, the continuing relevance of encoder-only models, and how they relate to, say, GPT-4/llama. Accessible enough that I might use this as an undergrad reading.
Reposted by Yapei Chang

🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me

December 6, 2024 at 1:44 AM
🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
🐠 what monday feels like..

December 2, 2024 at 11:46 PM
🐠 what monday feels like..
private closed-source evals are the future 🫣
November 26, 2024 at 8:37 PM
private closed-source evals are the future 🫣
i knew something like this had to exist but why did i only discover it now?? no more suffering from looking at my 10+ open arxiv tabs not knowing which one is which...

November 25, 2024 at 9:22 PM
i knew something like this had to exist but why did i only discover it now?? no more suffering from looking at my 10+ open arxiv tabs not knowing which one is which...
Reposted by Yapei Chang

I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
November 23, 2024 at 7:54 PM
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
such a creative way of using long-context models! this sounds like a super hard evaluation task, but gemini is already so good at it...

Steve Johnson on using book text to build a text adventure in NotebookLM. “the game relies on three elements: the original text from my book; a large language model (… Gemini Pro 1.5); and a 400-word prompt that I wrote giving the model instructions on how to host the game” thelongcontext.com

You Exist In The Long Context
Thoughts on the quiet revolution of long-context AI models, from NotebookLM's Editorial Director Steven Johnson.
thelongcontext.com
November 21, 2024 at 3:04 PM
such a creative way of using long-context models! this sounds like a super hard evaluation task, but gemini is already so good at it...
Reposted by Yapei Chang

Mat is not on 🦋—posting on his behalf!
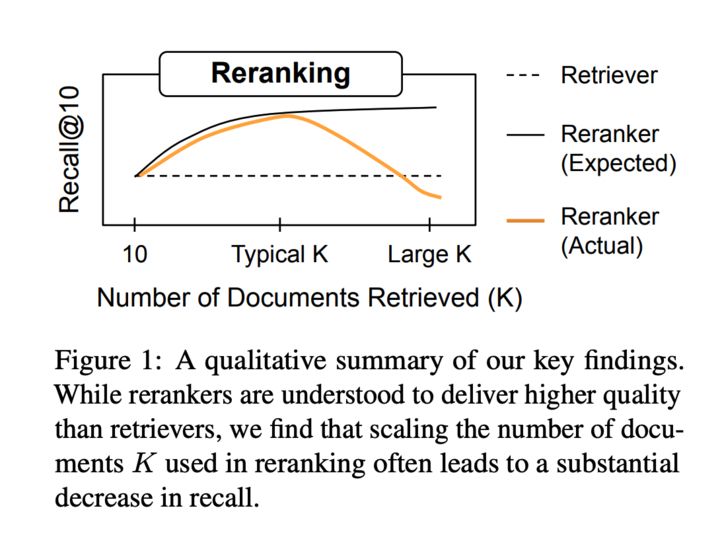
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
November 20, 2024 at 7:47 PM
Mat is not on 🦋—posting on his behalf!
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
It's time to revisit common assumptions in IR! Embeddings have improved drastically, but mainstream IR evals have stagnated since MSMARCO + BEIR.
We ask: on private or tricky IR tasks, are rerankers better? Surely, reranking many docs is best?
Reposted by Yapei Chang

The soul-searching journey for figuring out what research area is right for you is tricky since so many papers are cool. I tell my early career students that they should try to differentiate papers that they'd like to read 📖, implement 🔨, *and* write 📝 from papers that they'd only like to read 📖.
November 18, 2024 at 11:32 PM
The soul-searching journey for figuring out what research area is right for you is tricky since so many papers are cool. I tell my early career students that they should try to differentiate papers that they'd like to read 📖, implement 🔨, *and* write 📝 from papers that they'd only like to read 📖.
#EMNLP2024 was fun🍹now brainstorming ideas for #EMNLP2025 🙇🏻♀️




November 17, 2024 at 10:59 PM
#EMNLP2024 was fun🍹now brainstorming ideas for #EMNLP2025 🙇🏻♀️
airbnb >>> hotel for conferences #EMNLP2024

November 17, 2024 at 1:28 AM
airbnb >>> hotel for conferences #EMNLP2024
Reposted by Yapei Chang

✨I am on the faculty job market in the 2024-2025 cycle!✨
My research centers on advancing Responsible AI, specifically enhancing factuality, robustness, and transparency in AI systems.
If you have relevant positions, let me know! lasharavichander.github.io Please share/RT!
My research centers on advancing Responsible AI, specifically enhancing factuality, robustness, and transparency in AI systems.
If you have relevant positions, let me know! lasharavichander.github.io Please share/RT!
Abhilasha Ravichander - Home
lasharavichander.github.io
November 11, 2024 at 2:23 PM
✨I am on the faculty job market in the 2024-2025 cycle!✨
My research centers on advancing Responsible AI, specifically enhancing factuality, robustness, and transparency in AI systems.
If you have relevant positions, let me know! lasharavichander.github.io Please share/RT!
My research centers on advancing Responsible AI, specifically enhancing factuality, robustness, and transparency in AI systems.
If you have relevant positions, let me know! lasharavichander.github.io Please share/RT!
Reposted by Yapei Chang

Long-form text generation with multiple stylistic and semantic constraints remains largely unexplored.
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371

November 11, 2024 at 12:41 PM
Long-form text generation with multiple stylistic and semantic constraints remains largely unexplored.
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371
We present Suri 🦙: a dataset of 20K long-form texts & LLM-generated, backtranslated instructions with complex constraints.
📎 arxiv.org/abs/2406.19371
Reposted by Yapei Chang

I really wanted to run NEW #nocha benchmark claims on #o1 but it won't behave 😠
- 6k reasoning tokens is often not enough to get an ans and more means being able to process only short books
- OpenAI adds sth to the prompt: ~8k extra tokens-> less room for book+reason+generation!
- 6k reasoning tokens is often not enough to get an ans and more means being able to process only short books
- OpenAI adds sth to the prompt: ~8k extra tokens-> less room for book+reason+generation!

November 11, 2024 at 5:11 PM
🌊Heading to #EMNLP2024 tmr, presenting PostMark on Tue. morning! 🔗 arxiv.org/abs/2406.14517
Aside from this, I'd love to chat about:
• long-context training
• realistic & hard eval
• synthetic data
• tbh any cool projects people are working on
Also, I'm on the lookout for a summer 2025 internship!
Aside from this, I'd love to chat about:
• long-context training
• realistic & hard eval
• synthetic data
• tbh any cool projects people are working on
Also, I'm on the lookout for a summer 2025 internship!

November 10, 2024 at 7:35 PM
🌊Heading to #EMNLP2024 tmr, presenting PostMark on Tue. morning! 🔗 arxiv.org/abs/2406.14517
Aside from this, I'd love to chat about:
• long-context training
• realistic & hard eval
• synthetic data
• tbh any cool projects people are working on
Also, I'm on the lookout for a summer 2025 internship!
Aside from this, I'd love to chat about:
• long-context training
• realistic & hard eval
• synthetic data
• tbh any cool projects people are working on
Also, I'm on the lookout for a summer 2025 internship!
Reposted by Yapei Chang

Looking forward to catching up with old and new friends at #EMNLP2024!
I’m on the academic job market so please reach out if you would like to chat 🙏
And come talk to me, @rnv.bsky.social and @iaugenstein.bsky.social on Thu (Nov 14) at poster session G from 2-3:30PM about LLM tropes!
I’m on the academic job market so please reach out if you would like to chat 🙏
And come talk to me, @rnv.bsky.social and @iaugenstein.bsky.social on Thu (Nov 14) at poster session G from 2-3:30PM about LLM tropes!
At #EMNLP2024 we will present our paper on LLM values and opinions!
We introduce tropes: repeated and consistent phrases which LLMs generate to argue for political stances.
Read the paper to learn more! arxiv.org/abs/2406.19238
Work done Uni Copenhagen + Pioneer Center for AI
We introduce tropes: repeated and consistent phrases which LLMs generate to argue for political stances.
Read the paper to learn more! arxiv.org/abs/2406.19238
Work done Uni Copenhagen + Pioneer Center for AI

November 10, 2024 at 5:32 PM
Looking forward to catching up with old and new friends at #EMNLP2024!
I’m on the academic job market so please reach out if you would like to chat 🙏
And come talk to me, @rnv.bsky.social and @iaugenstein.bsky.social on Thu (Nov 14) at poster session G from 2-3:30PM about LLM tropes!
I’m on the academic job market so please reach out if you would like to chat 🙏
And come talk to me, @rnv.bsky.social and @iaugenstein.bsky.social on Thu (Nov 14) at poster session G from 2-3:30PM about LLM tropes!
Reposted by Yapei Chang

Starter packs are a great way to find people. But I followed a few tech/AI starter packs, and now have a sizeable gender skew in who I'm following.
To counteract, I started collecting this list. Who else should I be following & add? 👇 go.bsky.app/LaGDpqg
To counteract, I started collecting this list. Who else should I be following & add? 👇 go.bsky.app/LaGDpqg
November 8, 2024 at 12:04 PM
Starter packs are a great way to find people. But I followed a few tech/AI starter packs, and now have a sizeable gender skew in who I'm following.
To counteract, I started collecting this list. Who else should I be following & add? 👇 go.bsky.app/LaGDpqg
To counteract, I started collecting this list. Who else should I be following & add? 👇 go.bsky.app/LaGDpqg
thxx for the acknowledgment 🥰 also check out our followup work NoCha (novelchallenge.github.io), a benchmark that asks LLMs to verify claims about new fictional books! the leaderboard is updated with very new models
October 8, 2024 at 4:19 AM
thxx for the acknowledgment 🥰 also check out our followup work NoCha (novelchallenge.github.io), a benchmark that asks LLMs to verify claims about new fictional books! the leaderboard is updated with very new models
Reposted by Yapei Chang

we released our open multimodal language model Molmo today 🥳
🍝 secret sauce? really really high quality set of image+text pairs, which we'll release openly
🕹️ try it out: molmo.allenai.org
📎 read more about it: molmo.allenai.org/blog
🤗 download models: huggingface.co/collections/...
🍝 secret sauce? really really high quality set of image+text pairs, which we'll release openly
🕹️ try it out: molmo.allenai.org
📎 read more about it: molmo.allenai.org/blog
🤗 download models: huggingface.co/collections/...

September 25, 2024 at 7:13 PM
we released our open multimodal language model Molmo today 🥳
🍝 secret sauce? really really high quality set of image+text pairs, which we'll release openly
🕹️ try it out: molmo.allenai.org
📎 read more about it: molmo.allenai.org/blog
🤗 download models: huggingface.co/collections/...
🍝 secret sauce? really really high quality set of image+text pairs, which we'll release openly
🕹️ try it out: molmo.allenai.org
📎 read more about it: molmo.allenai.org/blog
🤗 download models: huggingface.co/collections/...