




Yang Xu (许扬)
@yangxu.bsky.social
PhD student @hein-lab.bsky.social @uni-wuerzburg.de, Learning & Decision making, fMRI, modeling, delay discounting, effort, empathy, intrinsic reward
Reposted by Yang Xu (许扬)

Voxelwise Encoding Models (VEMs) are a great framework for modeling fMRI data, but it can be difficult to implement. We've made VEM accessible by providing software, tutorials and reviews that guide its use an implementation. Get it here:
gallantlab.org/blog/2025-12...
#neuroscience, #neuroimaging
gallantlab.org/blog/2025-12...
#neuroscience, #neuroimaging

December 23, 2025 at 8:31 PM
Voxelwise Encoding Models (VEMs) are a great framework for modeling fMRI data, but it can be difficult to implement. We've made VEM accessible by providing software, tutorials and reviews that guide its use an implementation. Get it here:
gallantlab.org/blog/2025-12...
#neuroscience, #neuroimaging
gallantlab.org/blog/2025-12...
#neuroscience, #neuroimaging
Reposted by Yang Xu (许扬)

🎓 PhD Position (Paris) – Computational Cognitive Science, AI & Mental Health
For Master’s students outside France
Project on the computational bases of narrative pleasure 🧠📚🎮
For Master’s students outside France
Project on the computational bases of narrative pleasure 🧠📚🎮
January 19, 2026 at 11:21 AM
🎓 PhD Position (Paris) – Computational Cognitive Science, AI & Mental Health
For Master’s students outside France
Project on the computational bases of narrative pleasure 🧠📚🎮
For Master’s students outside France
Project on the computational bases of narrative pleasure 🧠📚🎮
Reposted by Yang Xu (许扬)

New pontification piece with @awestbrook.bsky.social and Jean Daunizeau, just out in TICS:
Why is cognitive effort experienced as costly?
(or why does it hurt to think)
never written a review paper before in my life, that was a new and unusual experience
Why is cognitive effort experienced as costly?
(or why does it hurt to think)
never written a review paper before in my life, that was a new and unusual experience

Why is cognitive effort experienced as costly?
A widespread observation is that people avoid mentally effortful courses of action,
and much recent work examining cognitive effort has explained subjective effort evaluation
– and, consequently, pref...
www.cell.com
November 19, 2025 at 2:48 PM
New pontification piece with @awestbrook.bsky.social and Jean Daunizeau, just out in TICS:
Why is cognitive effort experienced as costly?
(or why does it hurt to think)
never written a review paper before in my life, that was a new and unusual experience
Why is cognitive effort experienced as costly?
(or why does it hurt to think)
never written a review paper before in my life, that was a new and unusual experience
Reposted by Yang Xu (许扬)

November 27, 2025 at 7:08 AM
Reposted by Yang Xu (许扬)

We are hiring 11 Doctoral Researchers (100%) in the DFG-RTG "The Experience of Stories in the Digital Age". Uni Wuerzburg, Germany. Disciplines: Communication, Psychology, Computer Science. Topics: VR / XR, storytelling robots, influencers, misinformation. More: go.uniwue.de/rtg3087jobs Please share

September 26, 2025 at 12:14 PM
We are hiring 11 Doctoral Researchers (100%) in the DFG-RTG "The Experience of Stories in the Digital Age". Uni Wuerzburg, Germany. Disciplines: Communication, Psychology, Computer Science. Topics: VR / XR, storytelling robots, influencers, misinformation. More: go.uniwue.de/rtg3087jobs Please share
Reposted by Yang Xu (许扬)

New in @pnas.org: doi.org/10.1073/pnas...
We study how humans explore a 61-state environment with a stochastic region that mimics a “noisy-TV.”
Results: Participants keep exploring the stochastic part even when it’s unhelpful, and novelty-seeking best explains this behavior.
#cogsci #neuroskyence
We study how humans explore a 61-state environment with a stochastic region that mimics a “noisy-TV.”
Results: Participants keep exploring the stochastic part even when it’s unhelpful, and novelty-seeking best explains this behavior.
#cogsci #neuroskyence


September 28, 2025 at 11:07 AM
New in @pnas.org: doi.org/10.1073/pnas...
We study how humans explore a 61-state environment with a stochastic region that mimics a “noisy-TV.”
Results: Participants keep exploring the stochastic part even when it’s unhelpful, and novelty-seeking best explains this behavior.
#cogsci #neuroskyence
We study how humans explore a 61-state environment with a stochastic region that mimics a “noisy-TV.”
Results: Participants keep exploring the stochastic part even when it’s unhelpful, and novelty-seeking best explains this behavior.
#cogsci #neuroskyence
Reposted by Yang Xu (许扬)

Introducing hMFC: A Bayesian hierarchical model of trial-to-trial fluctuations in decision criterion! Now out in @plos.org Comp Bio.
led by Robin Vloeberghs with @anne-urai.bsky.social Scott Linderman
Paper: desenderlab.com/wp-content/u... Thread ↓↓↓
#PsychSciSky #Neuroscience #Neuroskyence
led by Robin Vloeberghs with @anne-urai.bsky.social Scott Linderman
Paper: desenderlab.com/wp-content/u... Thread ↓↓↓
#PsychSciSky #Neuroscience #Neuroskyence
September 25, 2025 at 9:13 AM
Introducing hMFC: A Bayesian hierarchical model of trial-to-trial fluctuations in decision criterion! Now out in @plos.org Comp Bio.
led by Robin Vloeberghs with @anne-urai.bsky.social Scott Linderman
Paper: desenderlab.com/wp-content/u... Thread ↓↓↓
#PsychSciSky #Neuroscience #Neuroskyence
led by Robin Vloeberghs with @anne-urai.bsky.social Scott Linderman
Paper: desenderlab.com/wp-content/u... Thread ↓↓↓
#PsychSciSky #Neuroscience #Neuroskyence
Reposted by Yang Xu (许扬)

Excited to share new work with @hleemasson.bsky.social , Ericka Wodka, Stewart Mostofsky and @lisik.bsky.social! We investigated how simultaneous vision and language signals are combined in the brain using naturalistic+controlled fMRI. Read the paper here: osf.io/b5p4n
1/n
1/n

September 24, 2025 at 7:46 PM
Excited to share new work with @hleemasson.bsky.social , Ericka Wodka, Stewart Mostofsky and @lisik.bsky.social! We investigated how simultaneous vision and language signals are combined in the brain using naturalistic+controlled fMRI. Read the paper here: osf.io/b5p4n
1/n
1/n
Reposted by Yang Xu (许扬)

Can one bring together Reinforcement learning and Drift Diffusion models to understand collective foraging ?
Congrads to Jonathan Marienhagen , Lisa Blum Moyse and Dominik Deffner on this new study. Very happy that I was part of this collaboration.
Preprint here: osf.io/preprints/ps...
Congrads to Jonathan Marienhagen , Lisa Blum Moyse and Dominik Deffner on this new study. Very happy that I was part of this collaboration.
Preprint here: osf.io/preprints/ps...

September 16, 2025 at 10:14 AM
Can one bring together Reinforcement learning and Drift Diffusion models to understand collective foraging ?
Congrads to Jonathan Marienhagen , Lisa Blum Moyse and Dominik Deffner on this new study. Very happy that I was part of this collaboration.
Preprint here: osf.io/preprints/ps...
Congrads to Jonathan Marienhagen , Lisa Blum Moyse and Dominik Deffner on this new study. Very happy that I was part of this collaboration.
Preprint here: osf.io/preprints/ps...
Reposted by Yang Xu (许扬)

📢 Now accepted at Neuroscience & Biobehavioral Reviews 🤩
Our proposal offers a framework for understanding how fundamental regulatory sensations, such as boredom & effort, shape temporal experience through interoceptive mechanisms.
Link: www.sciencedirect.com/science/arti...
TL;DR: Check 🧵 below
Our proposal offers a framework for understanding how fundamental regulatory sensations, such as boredom & effort, shape temporal experience through interoceptive mechanisms.
Link: www.sciencedirect.com/science/arti...
TL;DR: Check 🧵 below
September 15, 2025 at 5:30 AM
📢 Now accepted at Neuroscience & Biobehavioral Reviews 🤩
Our proposal offers a framework for understanding how fundamental regulatory sensations, such as boredom & effort, shape temporal experience through interoceptive mechanisms.
Link: www.sciencedirect.com/science/arti...
TL;DR: Check 🧵 below
Our proposal offers a framework for understanding how fundamental regulatory sensations, such as boredom & effort, shape temporal experience through interoceptive mechanisms.
Link: www.sciencedirect.com/science/arti...
TL;DR: Check 🧵 below
Reposted by Yang Xu (许扬)

Do you ever wish you could just use python to pull together the files and code for running FSL's randomise? Me too! I made this: github.com/jmumford/ran... It will even replace the numbers in the file outputs with contrast names of your choosing (and replace corrp with 1minusp).

GitHub - jmumford/randomise-prep: Generate design matrices, contrasts, and scripts to set up FSL randomise analyses.
Generate design matrices, contrasts, and scripts to set up FSL randomise analyses. - jmumford/randomise-prep
github.com
September 12, 2025 at 1:41 AM
Do you ever wish you could just use python to pull together the files and code for running FSL's randomise? Me too! I made this: github.com/jmumford/ran... It will even replace the numbers in the file outputs with contrast names of your choosing (and replace corrp with 1minusp).
Reposted by Yang Xu (许扬)

Awesome new preprint from @jasonleng.bsky.social!
Deadlines in decision making often truncate too-slow responses. Failing to account for these omissions can (severely) bias your DDM parameter estimates.
They offer a great solution to correct for this issue.
doi.org/10.31234/osf...
Deadlines in decision making often truncate too-slow responses. Failing to account for these omissions can (severely) bias your DDM parameter estimates.
They offer a great solution to correct for this issue.
doi.org/10.31234/osf...


September 10, 2025 at 3:48 PM
Awesome new preprint from @jasonleng.bsky.social!
Deadlines in decision making often truncate too-slow responses. Failing to account for these omissions can (severely) bias your DDM parameter estimates.
They offer a great solution to correct for this issue.
doi.org/10.31234/osf...
Deadlines in decision making often truncate too-slow responses. Failing to account for these omissions can (severely) bias your DDM parameter estimates.
They offer a great solution to correct for this issue.
doi.org/10.31234/osf...
Reposted by Yang Xu (许扬)

📢 New preprint!
How do humans learn from arbitrary, abstract goals? We show that, when goal spaces can be compressed, costly working-memory processes give way to internalized reward functions, enabling efficient goal-dependent reinforcement learning. @annecollins.bsky.social arxiv.org/abs/2509.06810
How do humans learn from arbitrary, abstract goals? We show that, when goal spaces can be compressed, costly working-memory processes give way to internalized reward functions, enabling efficient goal-dependent reinforcement learning. @annecollins.bsky.social arxiv.org/abs/2509.06810

Reward function compression facilitates goal-dependent reinforcement learning
Reinforcement learning agents learn from rewards, but humans can uniquely assign value to novel, abstract outcomes in a goal-dependent manner. However, this flexibility is cognitively costly, making l...
arxiv.org
September 9, 2025 at 1:58 AM
📢 New preprint!
How do humans learn from arbitrary, abstract goals? We show that, when goal spaces can be compressed, costly working-memory processes give way to internalized reward functions, enabling efficient goal-dependent reinforcement learning. @annecollins.bsky.social arxiv.org/abs/2509.06810
How do humans learn from arbitrary, abstract goals? We show that, when goal spaces can be compressed, costly working-memory processes give way to internalized reward functions, enabling efficient goal-dependent reinforcement learning. @annecollins.bsky.social arxiv.org/abs/2509.06810
Reposted by Yang Xu (许扬)

Excited to share joint work with Ulf Hahnel and @sgluth.bsky.social on investigating how attribute translations - a widely implemented behavior intervention - lead to more ecological consumer choices. Main results are below, but check out our preprint 👇
www.researchsquare.com/article/rs-7...
www.researchsquare.com/article/rs-7...
Computational Mechanisms of Attribute Translations
Attribute translations, a choice architecture intervention technique aiming to promote behavior change by translating decision-relevant information into more comprehensible and meaningful units for la...
www.researchsquare.com
September 8, 2025 at 7:32 AM
Excited to share joint work with Ulf Hahnel and @sgluth.bsky.social on investigating how attribute translations - a widely implemented behavior intervention - lead to more ecological consumer choices. Main results are below, but check out our preprint 👇
www.researchsquare.com/article/rs-7...
www.researchsquare.com/article/rs-7...
Reposted by Yang Xu (许扬)

My pre-PhD work with @noham-wolpe.bsky.social is finally out! doi.org/10.1037/mot0000411
How does progress feedback influence effort-based decision-making? Our study involved a novel effort manipulation designed for online testing and mouse-tracking. The results came with a twist on apathy… (🧵1/3)
How does progress feedback influence effort-based decision-making? Our study involved a novel effort manipulation designed for online testing and mouse-tracking. The results came with a twist on apathy… (🧵1/3)
APA PsycNet
doi.org
September 3, 2025 at 4:51 PM
My pre-PhD work with @noham-wolpe.bsky.social is finally out! doi.org/10.1037/mot0000411
How does progress feedback influence effort-based decision-making? Our study involved a novel effort manipulation designed for online testing and mouse-tracking. The results came with a twist on apathy… (🧵1/3)
How does progress feedback influence effort-based decision-making? Our study involved a novel effort manipulation designed for online testing and mouse-tracking. The results came with a twist on apathy… (🧵1/3)
Reposted by Yang Xu (许扬)

New paper our in @pnas.org, lead by @isabellehoxha.bsky.social with Léo Sperber. We use evolutionary simulation to assess and compare the adaptive value of positivity bias and gradual perseveration in reinforcement learning. Follow the thread below (and Isabelle!) for more details!

Ever wondered why you keep going to that restaurant with stale fries? Is it because you went often in the past (perseveration) or because you remember past good experiences better (positivity bias)? Our study out in PNAS investigates the normative basis for these biases www.pnas.org/doi/10.1073/...

Evolving choice hysteresis in reinforcement learning: Comparing the adaptive value of positivity bias and gradual perseveration | PNAS
The tendency to repeat past choices more often than expected from the history of outcomes
has been repeatedly empirically observed in reinforcement...
www.pnas.org
September 3, 2025 at 9:17 AM
New paper our in @pnas.org, lead by @isabellehoxha.bsky.social with Léo Sperber. We use evolutionary simulation to assess and compare the adaptive value of positivity bias and gradual perseveration in reinforcement learning. Follow the thread below (and Isabelle!) for more details!
Reposted by Yang Xu (许扬)

🧠 We're hiring a computational postdoc!
3+ years with me & @mitulamehta.bsky.social on @wellcometrust.bsky.social funded social cognition/paranoia research at the IoPPN.
Lead & develop computational work, collaborate with experimentalists on psychosis/THC data.
DM for details! lnkd.in/eCMy9Jf5
3+ years with me & @mitulamehta.bsky.social on @wellcometrust.bsky.social funded social cognition/paranoia research at the IoPPN.
Lead & develop computational work, collaborate with experimentalists on psychosis/THC data.
DM for details! lnkd.in/eCMy9Jf5

September 3, 2025 at 7:13 AM
🧠 We're hiring a computational postdoc!
3+ years with me & @mitulamehta.bsky.social on @wellcometrust.bsky.social funded social cognition/paranoia research at the IoPPN.
Lead & develop computational work, collaborate with experimentalists on psychosis/THC data.
DM for details! lnkd.in/eCMy9Jf5
3+ years with me & @mitulamehta.bsky.social on @wellcometrust.bsky.social funded social cognition/paranoia research at the IoPPN.
Lead & develop computational work, collaborate with experimentalists on psychosis/THC data.
DM for details! lnkd.in/eCMy9Jf5
Reposted by Yang Xu (许扬)

🚨 Want to research the computational & neural mechanisms of planning and its disruption in mental health? If so, join our lab!
Here's one prestigious postdoc fellowship that just opened: azrielifoundation.org/azrieli-fell...
reach out w/your CV to paul.sharp@biu.ac.il
lab: sharplabbiu.github.io
Here's one prestigious postdoc fellowship that just opened: azrielifoundation.org/azrieli-fell...
reach out w/your CV to paul.sharp@biu.ac.il
lab: sharplabbiu.github.io
Lab Website
sharplabbiu.github.io
September 2, 2025 at 2:45 PM
🚨 Want to research the computational & neural mechanisms of planning and its disruption in mental health? If so, join our lab!
Here's one prestigious postdoc fellowship that just opened: azrielifoundation.org/azrieli-fell...
reach out w/your CV to paul.sharp@biu.ac.il
lab: sharplabbiu.github.io
Here's one prestigious postdoc fellowship that just opened: azrielifoundation.org/azrieli-fell...
reach out w/your CV to paul.sharp@biu.ac.il
lab: sharplabbiu.github.io
Reposted by Yang Xu (许扬)

New preprint! We are pleased to share our Hierarchical Bayesian framework for Interoceptive Psychophysics! Implemented in rstan, we provide a complete suite of tools spanning model comparison, parameter recovery, multifactor designs, power analysis, and more! 🎯 www.biorxiv.org/content/10.1...

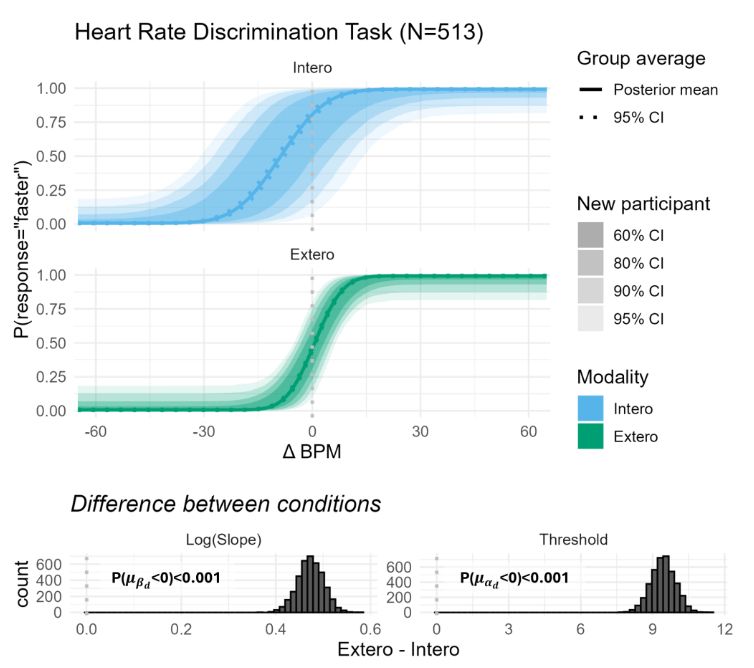
September 2, 2025 at 8:09 AM
New preprint! We are pleased to share our Hierarchical Bayesian framework for Interoceptive Psychophysics! Implemented in rstan, we provide a complete suite of tools spanning model comparison, parameter recovery, multifactor designs, power analysis, and more! 🎯 www.biorxiv.org/content/10.1...
Reposted by Yang Xu (许扬)
So happy to see this work out! 🥳
Huge thanks to our two amazing reviewers who pushed us to make the paper much stronger. A truly joyful collaboration with @lucasgruaz.bsky.social, @sobeckerneuro.bsky.social, and Johanni Brea! 🥰
Tweeprint on an earlier version: bsky.app/profile/modi... 🧠🧪👩🔬
Huge thanks to our two amazing reviewers who pushed us to make the paper much stronger. A truly joyful collaboration with @lucasgruaz.bsky.social, @sobeckerneuro.bsky.social, and Johanni Brea! 🥰
Tweeprint on an earlier version: bsky.app/profile/modi... 🧠🧪👩🔬

August 25, 2025 at 4:18 PM
So happy to see this work out! 🥳
Huge thanks to our two amazing reviewers who pushed us to make the paper much stronger. A truly joyful collaboration with @lucasgruaz.bsky.social, @sobeckerneuro.bsky.social, and Johanni Brea! 🥰
Tweeprint on an earlier version: bsky.app/profile/modi... 🧠🧪👩🔬
Huge thanks to our two amazing reviewers who pushed us to make the paper much stronger. A truly joyful collaboration with @lucasgruaz.bsky.social, @sobeckerneuro.bsky.social, and Johanni Brea! 🥰
Tweeprint on an earlier version: bsky.app/profile/modi... 🧠🧪👩🔬
Reposted by Yang Xu (许扬)

New paper from my group led by Odd Jacobson, former PhD student & current postdoc @livingingroups.bsky.social : How do animal groups simultaneously balance between- and within-group competition in dynamic environments and does this impact movement and space use? www.biorxiv.org/content/10.1...

Between-group competitive advantage offsets foraging costs for bigger groups in harsher seasons
Larger animal groups are widely understood to require more space and travel farther to mitigate the foraging costs of within-group competition. Yet, between-group interactions and shifting resource di...
www.biorxiv.org
August 20, 2025 at 12:02 PM
New paper from my group led by Odd Jacobson, former PhD student & current postdoc @livingingroups.bsky.social : How do animal groups simultaneously balance between- and within-group competition in dynamic environments and does this impact movement and space use? www.biorxiv.org/content/10.1...
Reposted by Yang Xu (许扬)

Looking at Van Gogh’s Starry Night, we see not only its content (a French village beneath a night sky) but also its *style*. How does that work? How do we see style?
In @nathumbehav.nature.com, @chazfirestone.bsky.social & I take an experimental approach to style perception! osf.io/preprints/ps...
In @nathumbehav.nature.com, @chazfirestone.bsky.social & I take an experimental approach to style perception! osf.io/preprints/ps...

May 14, 2025 at 4:42 PM
Looking at Van Gogh’s Starry Night, we see not only its content (a French village beneath a night sky) but also its *style*. How does that work? How do we see style?
In @nathumbehav.nature.com, @chazfirestone.bsky.social & I take an experimental approach to style perception! osf.io/preprints/ps...
In @nathumbehav.nature.com, @chazfirestone.bsky.social & I take an experimental approach to style perception! osf.io/preprints/ps...
Reposted by Yang Xu (许扬)

My first paper with @naoshigeuchida.bsky.social is finally out in @natcomms.nature.com ! rdcu.be/eACGf
TL;DR: asymmetric learning rates can be induced by shifts in tonic dopamine giving rise to pessimistic/optimistic biases in agents or animals undergoing reinforcement learning .
TL;DR: asymmetric learning rates can be induced by shifts in tonic dopamine giving rise to pessimistic/optimistic biases in agents or animals undergoing reinforcement learning .

Tonic dopamine and biases in value learning linked through a biologically inspired reinforcement learning model
Nature Communications - Accurate future predictions are essential for guiding behavior, and disruptions in this process are associated with psychiatric disorders. Here the authors show that changes...
rdcu.be
August 13, 2025 at 9:55 PM
My first paper with @naoshigeuchida.bsky.social is finally out in @natcomms.nature.com ! rdcu.be/eACGf
TL;DR: asymmetric learning rates can be induced by shifts in tonic dopamine giving rise to pessimistic/optimistic biases in agents or animals undergoing reinforcement learning .
TL;DR: asymmetric learning rates can be induced by shifts in tonic dopamine giving rise to pessimistic/optimistic biases in agents or animals undergoing reinforcement learning .
Reposted by Yang Xu (许扬)

Preprint⭐
Our attention changes over time and differs across contexts—which is reflected in the brain🧠 Fitting a dynamical systems model to fMRI data, we find that the geometry of neural dynamics along the attractor landscape reflects such changes in attention!
www.biorxiv.org/content/10.1...
Our attention changes over time and differs across contexts—which is reflected in the brain🧠 Fitting a dynamical systems model to fMRI data, we find that the geometry of neural dynamics along the attractor landscape reflects such changes in attention!
www.biorxiv.org/content/10.1...

Geometry of neural dynamics along the cortical attractor landscape reflects changes in attention
The brain is a complex dynamical system whose activity reflects changes in internal states, such as attention. While prior work has shown that large-scale brain activity reflects attention, the mechan...
www.biorxiv.org
August 12, 2025 at 7:29 PM
Preprint⭐
Our attention changes over time and differs across contexts—which is reflected in the brain🧠 Fitting a dynamical systems model to fMRI data, we find that the geometry of neural dynamics along the attractor landscape reflects such changes in attention!
www.biorxiv.org/content/10.1...
Our attention changes over time and differs across contexts—which is reflected in the brain🧠 Fitting a dynamical systems model to fMRI data, we find that the geometry of neural dynamics along the attractor landscape reflects such changes in attention!
www.biorxiv.org/content/10.1...
Reposted by Yang Xu (许扬)

New paper with @nathanieldaw.bsky.social in Nature Communications: an RL model that builds a successor map compositionally. The new model plans as well as the best models, and it links components of the map used for planning to neural codes in the medial entorhinal cortex.
rdcu.be/eAofi
rdcu.be/eAofi

Reconciling flexibility and efficiency: medial entorhinal cortex represents a compositional cognitive map
Nature Communications - How the brain creates compositional cognitive maps that support both flexible and efficient planning remains poorly understood. Here, authors propose a...
rdcu.be
August 12, 2025 at 5:18 PM
New paper with @nathanieldaw.bsky.social in Nature Communications: an RL model that builds a successor map compositionally. The new model plans as well as the best models, and it links components of the map used for planning to neural codes in the medial entorhinal cortex.
rdcu.be/eAofi
rdcu.be/eAofi