



Vincent Tao Hu
@vtaohu.bsky.social
LMU postdoc from Ommer-Lab, MCML junior member. UvA PhD, PKU
Reposted by Vincent Tao Hu

Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.

February 28, 2025 at 5:03 PM
Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
Reposted by Vincent Tao Hu
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
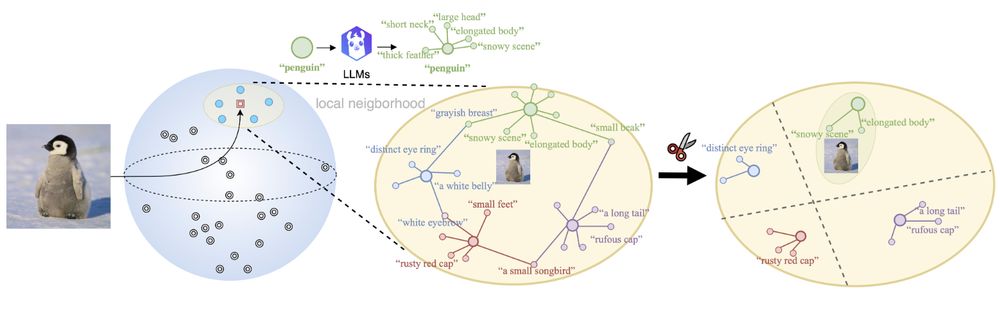
January 8, 2025 at 3:54 PM
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
Reposted by Vincent Tao Hu

Did you know you can distill the capabilities of a large diffusion model into a small ViT? ⚗️
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
December 6, 2024 at 2:35 PM
Did you know you can distill the capabilities of a large diffusion model into a small ViT? ⚗️
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
Your Diffusion Model is secretly an implicit timestep model, no matter discrete or continuous~

🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
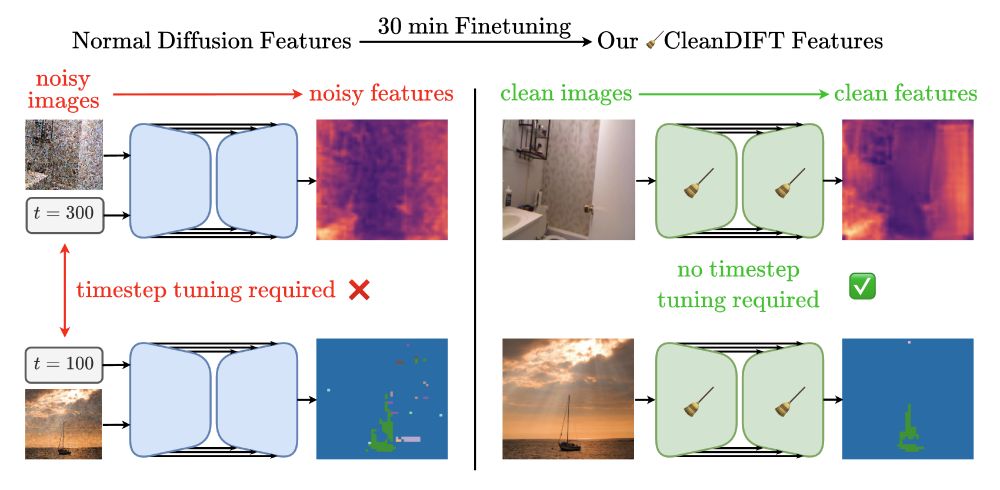
December 4, 2024 at 11:42 PM
Your Diffusion Model is secretly an implicit timestep model, no matter discrete or continuous~
Reposted by Vincent Tao Hu

Introducing “MAGiC-SLAM: Multi-Agent Gaussian Globally Consistent SLAM”! We do SLAM with novel view synthesis capabilities on multiple simultaneously operating agents!
vladimiryugay.github.io/magic_slam/i...
1/7
vladimiryugay.github.io/magic_slam/i...
1/7
November 27, 2024 at 5:34 AM
Introducing “MAGiC-SLAM: Multi-Agent Gaussian Globally Consistent SLAM”! We do SLAM with novel view synthesis capabilities on multiple simultaneously operating agents!
vladimiryugay.github.io/magic_slam/i...
1/7
vladimiryugay.github.io/magic_slam/i...
1/7