


Tony S.F.
@tonysf.bsky.social
Ass. Prof. of AI at CentraleSupélec in the Centre pour la Vision Numérique.
Pinned
Tony S.F.
@tonysf.bsky.social
· Apr 27
That problem is smooth.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
I heard that it's easier to get an h100 on Jean Zay than an a100, kind of funny. The hour multiplier for consumption (i.e. one h100 hour costs 4 credits) should take into account demand.
October 30, 2025 at 4:44 PM
I heard that it's easier to get an h100 on Jean Zay than an a100, kind of funny. The hour multiplier for consumption (i.e. one h100 hour costs 4 credits) should take into account demand.

you can improve your collaborators' writing clarity by being too dumb to fill in the gaps of what they've written, and arguing it must be wrong until they write it clearly enough that even you can understand.
October 21, 2025 at 6:43 PM
you can improve your collaborators' writing clarity by being too dumb to fill in the gaps of what they've written, and arguing it must be wrong until they write it clearly enough that even you can understand.
I started to read this paper arxiv.org/abs/2510.17503 and I thought huh the analysis is so much like Frank-Wolfe, then I remembered that Frank-Wolfe and DC algorithms are dual. Probably, a Frank-Wolfe god like Jaggi knows that but it's not mentioned in the paper; I must be missing something simple.
arxiv.org
October 21, 2025 at 9:57 AM
I started to read this paper arxiv.org/abs/2510.17503 and I thought huh the analysis is so much like Frank-Wolfe, then I remembered that Frank-Wolfe and DC algorithms are dual. Probably, a Frank-Wolfe god like Jaggi knows that but it's not mentioned in the paper; I must be missing something simple.
Have you ever written a paper, and you see a small variation you could easily cover with your analysis etc but you don't do it? But you know if someone else did it right after, you would be upset you didn't include it? It happened to me again today! arxiv.org/abs/2510.16468
arxiv.org
October 21, 2025 at 9:53 AM
Have you ever written a paper, and you see a small variation you could easily cover with your analysis etc but you don't do it? But you know if someone else did it right after, you would be upset you didn't include it? It happened to me again today! arxiv.org/abs/2510.16468
Reposted by Tony S.F.

Abbas Khademi, Antonio Silveti-Falls
Adaptive Conditional Gradient Descent
https://arxiv.org/abs/2510.11440
Adaptive Conditional Gradient Descent
https://arxiv.org/abs/2510.11440
October 14, 2025 at 4:12 AM
Abbas Khademi, Antonio Silveti-Falls
Adaptive Conditional Gradient Descent
https://arxiv.org/abs/2510.11440
Adaptive Conditional Gradient Descent
https://arxiv.org/abs/2510.11440
Straight to the top of the "to read" list: arxiv.org/pdf/2510.09034
arxiv.org
October 13, 2025 at 9:56 AM
Straight to the top of the "to read" list: arxiv.org/pdf/2510.09034
Reposted by Tony S.F.

Now accepted at #NeurIPS2025 :)
📣 New preprint 📣
**Differentiable Generalized Sliced Wasserstein Plans**
w/
L. Chapel
@rtavenar.bsky.social
We propose a Generalized Sliced Wasserstein method that provides an approximated transport plan and which admits a differentiable approximation.
arxiv.org/abs/2505.22049 1/5
**Differentiable Generalized Sliced Wasserstein Plans**
w/
L. Chapel
@rtavenar.bsky.social
We propose a Generalized Sliced Wasserstein method that provides an approximated transport plan and which admits a differentiable approximation.
arxiv.org/abs/2505.22049 1/5

September 29, 2025 at 10:48 AM
Now accepted at #NeurIPS2025 :)
In conditional gradient sliding you are using the conditional gradient algorithm to "chase" the projected Nesterov algorithm. Instead of computing the projection, you do some conditional gradient steps to approximate it. I wonder if you can do the same with FISTA/accelerated proximal point alg ?
September 25, 2025 at 7:59 PM
In conditional gradient sliding you are using the conditional gradient algorithm to "chase" the projected Nesterov algorithm. Instead of computing the projection, you do some conditional gradient steps to approximate it. I wonder if you can do the same with FISTA/accelerated proximal point alg ?
nerd sniped by the bayesian learning rule again and still unsatisfied... ok, so you can explain a lot of DL optimization algorithms with certain approximations of various posteriors but that's kind of kicking the can down the road - the question becomes: why those approximations instead of others?
September 19, 2025 at 5:20 PM
nerd sniped by the bayesian learning rule again and still unsatisfied... ok, so you can explain a lot of DL optimization algorithms with certain approximations of various posteriors but that's kind of kicking the can down the road - the question becomes: why those approximations instead of others?
My paper on Generalized Gradient Norm Clipping & Non-Euclidean (L0, L1)-Smoothness (together with collaborators from EPFL) was accepted as an oral at NeurIPS! We extend the theory for our Scion algorithm to include gradient clipping. Read about it here arxiv.org/abs/2506.01913

September 19, 2025 at 4:49 PM
My paper on Generalized Gradient Norm Clipping & Non-Euclidean (L0, L1)-Smoothness (together with collaborators from EPFL) was accepted as an oral at NeurIPS! We extend the theory for our Scion algorithm to include gradient clipping. Read about it here arxiv.org/abs/2506.01913
Found this on r/math: priority dispute in pure math that has come to a head, arxiv.org/abs/2507.20816

History of the canonical basis and crystal basis
The history of the canonical basis and crystal basis of a quantized enveloping algebra and its representations is presented
arxiv.org
July 30, 2025 at 9:24 AM
Found this on r/math: priority dispute in pure math that has come to a head, arxiv.org/abs/2507.20816
My ANR JCJC Grant was funded! 🎉
July 17, 2025 at 1:57 PM
My ANR JCJC Grant was funded! 🎉
The french branch of beyond meat missed the mark by not naming themselves beyond viande
July 6, 2025 at 9:33 AM
The french branch of beyond meat missed the mark by not naming themselves beyond viande
Reposted by Tony S.F.

🎉🎉🎉Our paper "Inexact subgradient methods for semialgebraic
functions" is accepted at Mathematical Programming !! This is a joint work with Jerome Bolte, Eric Moulines and Edouard Pauwels where we study a subgradient method with errors for nonconvex nonsmooth functions.
arxiv.org/pdf/2404.19517
functions" is accepted at Mathematical Programming !! This is a joint work with Jerome Bolte, Eric Moulines and Edouard Pauwels where we study a subgradient method with errors for nonconvex nonsmooth functions.
arxiv.org/pdf/2404.19517
arxiv.org
June 5, 2025 at 6:13 AM
🎉🎉🎉Our paper "Inexact subgradient methods for semialgebraic
functions" is accepted at Mathematical Programming !! This is a joint work with Jerome Bolte, Eric Moulines and Edouard Pauwels where we study a subgradient method with errors for nonconvex nonsmooth functions.
arxiv.org/pdf/2404.19517
functions" is accepted at Mathematical Programming !! This is a joint work with Jerome Bolte, Eric Moulines and Edouard Pauwels where we study a subgradient method with errors for nonconvex nonsmooth functions.
arxiv.org/pdf/2404.19517
mean-field this, mean-field that, how about a nice field for once
May 28, 2025 at 7:26 PM
mean-field this, mean-field that, how about a nice field for once
Doing analysis of stochastic Frank-Wolfe and steepest descent/generalized matching pursuit variants at the same time is useful. If your argument/setup isn't symmetric for both then something is probably wrong or you have formulated/parameterized things incorrectly.
May 8, 2025 at 12:16 PM
Doing analysis of stochastic Frank-Wolfe and steepest descent/generalized matching pursuit variants at the same time is useful. If your argument/setup isn't symmetric for both then something is probably wrong or you have formulated/parameterized things incorrectly.
Which lab is training a language model that can fix the latex for my beamer slides so that things don't shift a few pixels when I go to the next \onslide within a slide???
May 6, 2025 at 7:04 PM
Which lab is training a language model that can fix the latex for my beamer slides so that things don't shift a few pixels when I go to the next \onslide within a slide???
Reposted by Tony S.F.

Our research group in the department of Mathematics and Computer Science at the University of Basel (Switzerland) is looking for several PhD candidates and one post-doc who have a theoretical background in optimization and machine learning or practical experience in the field of reasoning.

Universität Basel: Post-doc position in the field of Optimization and Deep Learning Theory
The Optimization of Machine Learning Systems Group (Prof. A. Lucchi) at the Department of Mathematics and Computer Science at the University of Basel is looking for one post-doctorate to work in the a...
jobs.unibas.ch
May 3, 2025 at 9:06 AM
Our research group in the department of Mathematics and Computer Science at the University of Basel (Switzerland) is looking for several PhD candidates and one post-doc who have a theoretical background in optimization and machine learning or practical experience in the field of reasoning.
Really not a fan of people's "creative" paper titles. A few people are able to do it well/tastefully but it inspires so many bad/cringe titles and it's worse for keyword searching.
May 2, 2025 at 7:36 PM
Really not a fan of people's "creative" paper titles. A few people are able to do it well/tastefully but it inspires so many bad/cringe titles and it's worse for keyword searching.
That problem is smooth.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
April 27, 2025 at 10:46 AM
That problem is smooth.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
And if it's not, it is differentiable everywhere.
And if it's not, we avoid the kinks almost surely.
And if we don't, what is computed is a subgradient.
And if it's not, it approximates one.
And if that's not true, who cares? The loss went down.
Reposted by Tony S.F.
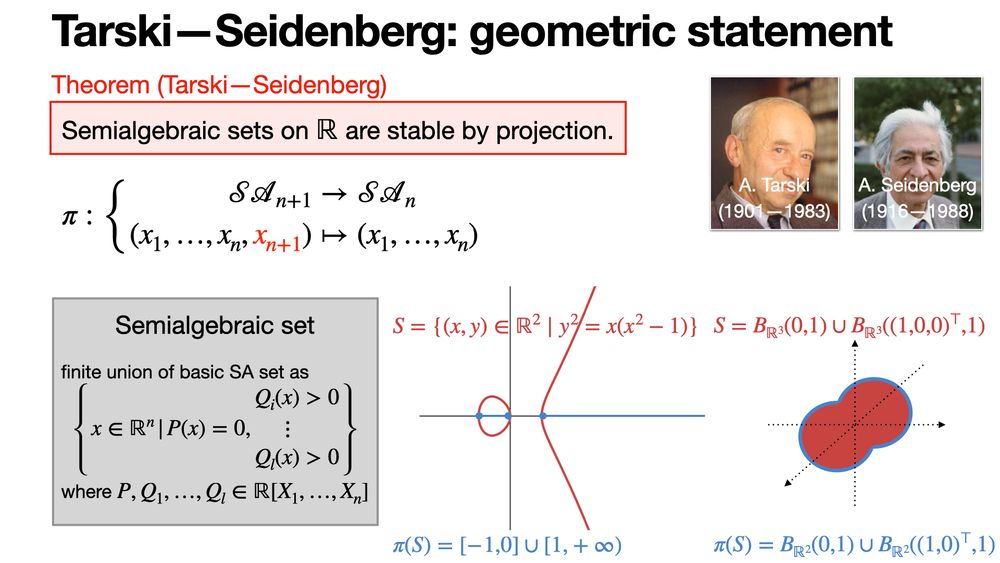
Tarski—Seidenberg theorem claims that semialgebraic sets on 𝐑 are stable by projection. perso.univ-rennes1.fr/michel.coste...
March 7, 2025 at 6:00 AM
Tarski—Seidenberg theorem claims that semialgebraic sets on 𝐑 are stable by projection. perso.univ-rennes1.fr/michel.coste...
We also provide the first convergence rate analysis that I'm aware of for stochastic unconstrained Frank-Wolfe (i.e., without weight decay), which directly covers the muon optimizer (and much more)!

🔥 Want to train large neural networks WITHOUT Adam while using less memory and getting better results? ⚡
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇
Check out SCION: a new optimizer that adapts to the geometry of your problem using norm-constrained linear minimization oracles (LMOs): 🧵👇

February 13, 2025 at 4:59 PM
We also provide the first convergence rate analysis that I'm aware of for stochastic unconstrained Frank-Wolfe (i.e., without weight decay), which directly covers the muon optimizer (and much more)!
Reposted by Tony S.F.

Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
November 27, 2024 at 9:00 AM
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423