


@saurabhsaxena.bsky.social
Our team in Google DeepMind Toronto is hiring a Student Researcher for Summer 2025 to work on projects in Video generative models and 3D Computer Vision. If you are interested, please apply at: forms.gle/Yj1jmbvjBFQC...

Student Researcher, Google DeepMind in Generative Models and 3D Computer Vision
Location: Toronto
Duration: 6 months
Start date: Flexible in Spring/Summer 2025
Project Details:
The project focuses on advancing generative modeling and/or computer vision techniques. The primary go...
forms.gle
March 5, 2025 at 9:30 PM
Our team in Google DeepMind Toronto is hiring a Student Researcher for Summer 2025 to work on projects in Video generative models and 3D Computer Vision. If you are interested, please apply at: forms.gle/Yj1jmbvjBFQC...
Reposted

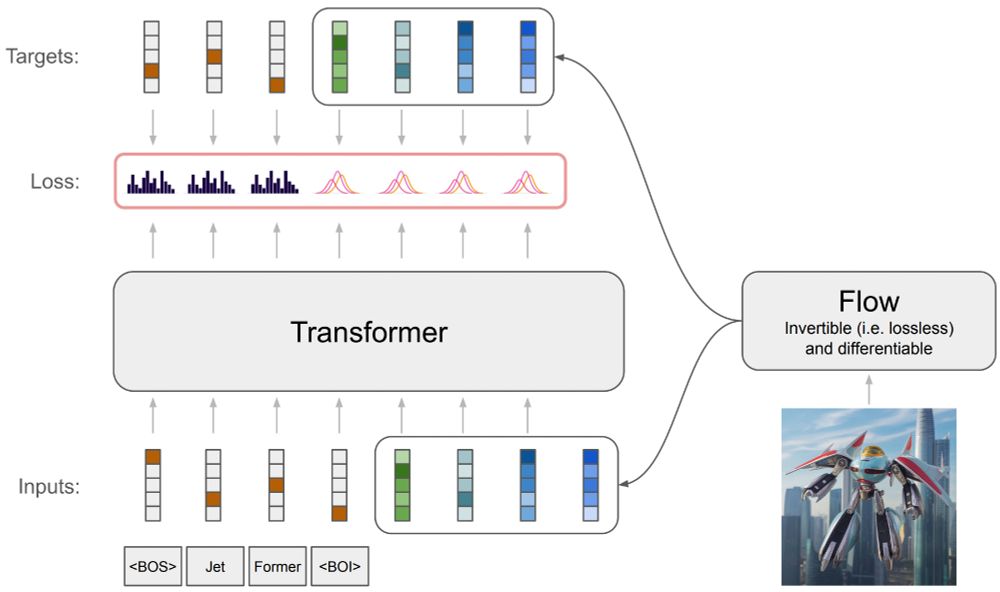
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
December 2, 2024 at 4:41 PM
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
SfM failing on dynamic videos? 😠 RoMo to the rescue! 💪 Our simple method uses epipolar cues and semantic features for robustly estimating motion masks, boosting dynamic SfM performance 🚀 Plus, a new dataset of dynamic scenes with ground truth cameras! 🤯 #computervision
🧵👇
🧵👇

Hello everyone!! 👋
Excited to be here and share our latest work to get started!
RoMo: Robust Motion Segmentation Improves Structure from Motion
romosfm.github.io
Boost the performance of your SfM pipeline on dynamic scenes! 🚀 RoMo masks dynamic objects in a video, in a zero-shot manner.
Excited to be here and share our latest work to get started!
RoMo: Robust Motion Segmentation Improves Structure from Motion
romosfm.github.io
Boost the performance of your SfM pipeline on dynamic scenes! 🚀 RoMo masks dynamic objects in a video, in a zero-shot manner.
December 3, 2024 at 6:05 AM
SfM failing on dynamic videos? 😠 RoMo to the rescue! 💪 Our simple method uses epipolar cues and semantic features for robustly estimating motion masks, boosting dynamic SfM performance 🚀 Plus, a new dataset of dynamic scenes with ground truth cameras! 🤯 #computervision
🧵👇
🧵👇
