




Ryan Dickerson
@rsdickerson.bsky.social
Exploring the changing world of work | Host of the Good Fit Careers Podcast | Former Executive Headhunter
Reposted by Ryan Dickerson

Gemini changelog from 13.03 was updated:
- Update to Gemini 2.0 Flash Thinking (experimental) in Gemini
- Deep Research is now powered by Gemini 2.0 Flash Thinking (experimental) and available to more Gemini users at no cost
- Update to Gemini 2.0 Flash Thinking (experimental) in Gemini
- Deep Research is now powered by Gemini 2.0 Flash Thinking (experimental) and available to more Gemini users at no cost

March 15, 2025 at 8:15 AM
Gemini changelog from 13.03 was updated:
- Update to Gemini 2.0 Flash Thinking (experimental) in Gemini
- Deep Research is now powered by Gemini 2.0 Flash Thinking (experimental) and available to more Gemini users at no cost
- Update to Gemini 2.0 Flash Thinking (experimental) in Gemini
- Deep Research is now powered by Gemini 2.0 Flash Thinking (experimental) and available to more Gemini users at no cost
Reposted by Ryan Dickerson
Claude Sonnet 3.7 evals are here too 👀
A huge jump on the SWE bench 🔥
A huge jump on the SWE bench 🔥

February 24, 2025 at 6:35 PM
Claude Sonnet 3.7 evals are here too 👀
A huge jump on the SWE bench 🔥
A huge jump on the SWE bench 🔥
Reposted by Ryan Dickerson


Reposted by Ryan Dickerson
Claude 3.7 Sonnet is also available to free users!
It seems like thinking experience you will be able to try only ones though.
It seems like thinking experience you will be able to try only ones though.

February 24, 2025 at 7:15 PM
Claude 3.7 Sonnet is also available to free users!
It seems like thinking experience you will be able to try only ones though.
It seems like thinking experience you will be able to try only ones though.
Reposted by Ryan Dickerson

Forget “tapestry” or “delve” these are the actual unique giveaway words for each model, relative to each other. arxiv.org/pdf/2502.12150

February 19, 2025 at 3:04 AM
Forget “tapestry” or “delve” these are the actual unique giveaway words for each model, relative to each other. arxiv.org/pdf/2502.12150
Reposted by Ryan Dickerson
Thoughts on Sam's post:
1) It echoes the story from multiple labs about the confidence of scaling up to AGI fast (but you don't have to believe them)
2) There is no clear vision of what that world looks like
3) The labs are placing the burden on policymakers to decide what to do with what they make
1) It echoes the story from multiple labs about the confidence of scaling up to AGI fast (but you don't have to believe them)
2) There is no clear vision of what that world looks like
3) The labs are placing the burden on policymakers to decide what to do with what they make


February 10, 2025 at 6:15 AM
Thoughts on Sam's post:
1) It echoes the story from multiple labs about the confidence of scaling up to AGI fast (but you don't have to believe them)
2) There is no clear vision of what that world looks like
3) The labs are placing the burden on policymakers to decide what to do with what they make
1) It echoes the story from multiple labs about the confidence of scaling up to AGI fast (but you don't have to believe them)
2) There is no clear vision of what that world looks like
3) The labs are placing the burden on policymakers to decide what to do with what they make
Reposted by Ryan Dickerson

Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
February 4, 2025 at 6:54 PM
Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
Reposted by Ryan Dickerson

Training our most capable Gemini models relies heavily on our JAX software stack+Google's TPU hardware platforms.
If you want to learn more, see this awesome book "How to Scale Your Model":
jax-ml.github.io/scaling-book/
Put together by several of my Google DeepMind colleagues listed below 🎉.
If you want to learn more, see this awesome book "How to Scale Your Model":
jax-ml.github.io/scaling-book/
Put together by several of my Google DeepMind colleagues listed below 🎉.
Making LLMs run efficiently can feel scary, but scaling isn’t magic, it’s math! We wanted to demystify the “systems view” of LLMs and wrote a little textbook called “How To Scale Your Model” which we’re releasing today. 1/n
February 4, 2025 at 7:51 PM
Training our most capable Gemini models relies heavily on our JAX software stack+Google's TPU hardware platforms.
If you want to learn more, see this awesome book "How to Scale Your Model":
jax-ml.github.io/scaling-book/
Put together by several of my Google DeepMind colleagues listed below 🎉.
If you want to learn more, see this awesome book "How to Scale Your Model":
jax-ml.github.io/scaling-book/
Put together by several of my Google DeepMind colleagues listed below 🎉.
Reposted by Ryan Dickerson

o3-mini is really good at writing internal documentation - feed it a codebase, get back a detailed explanation of how specific aspects of it work simonwillison.net/2025/Feb/5/o...
o3-mini is really good at writing internal documentation
I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have [extensive hand-written documentation](https://docs.datasette.io/en/latest/authentication.html) for...
simonwillison.net
February 5, 2025 at 6:09 AM
o3-mini is really good at writing internal documentation - feed it a codebase, get back a detailed explanation of how specific aspects of it work simonwillison.net/2025/Feb/5/o...
Reposted by Ryan Dickerson
Open Thoughts project
They are building the best reasoning datasets out in the open.
Building off their work with Stratos, today they are releasing OpenThoughts-114k and OpenThinker-7B.
Repo: github.com/open-thought...
They are building the best reasoning datasets out in the open.
Building off their work with Stratos, today they are releasing OpenThoughts-114k and OpenThinker-7B.
Repo: github.com/open-thought...

January 29, 2025 at 6:49 AM
Open Thoughts project
They are building the best reasoning datasets out in the open.
Building off their work with Stratos, today they are releasing OpenThoughts-114k and OpenThinker-7B.
Repo: github.com/open-thought...
They are building the best reasoning datasets out in the open.
Building off their work with Stratos, today they are releasing OpenThoughts-114k and OpenThinker-7B.
Repo: github.com/open-thought...
Reposted by Ryan Dickerson
Together.ai's Agent Recipes
Explore Agent Recipes: Explore common agent recipes with ready to copy code to improve your LLM applications. These agent recipes are largely inspired by Anthropic's article.
www.agentrecipes.com
Explore Agent Recipes: Explore common agent recipes with ready to copy code to improve your LLM applications. These agent recipes are largely inspired by Anthropic's article.
www.agentrecipes.com

Agent Recipes
Explore common agent recipes with ready to copy code to improve your LLM applications.
www.agentrecipes.com
January 15, 2025 at 9:04 PM
Together.ai's Agent Recipes
Explore Agent Recipes: Explore common agent recipes with ready to copy code to improve your LLM applications. These agent recipes are largely inspired by Anthropic's article.
www.agentrecipes.com
Explore Agent Recipes: Explore common agent recipes with ready to copy code to improve your LLM applications. These agent recipes are largely inspired by Anthropic's article.
www.agentrecipes.com
Reposted by Ryan Dickerson
New randomized, controlled trial by the World Bank of students using GPT-4 as a tutor in Nigeria. Six weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interventions.
And it helped all students, especially girls who were initially behind.
And it helped all students, especially girls who were initially behind.
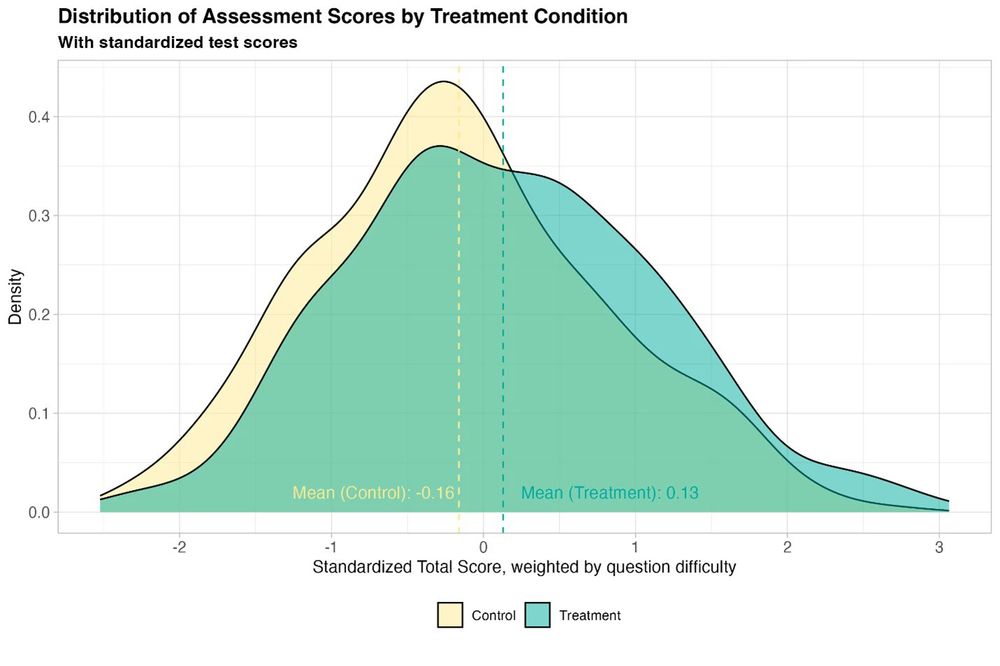
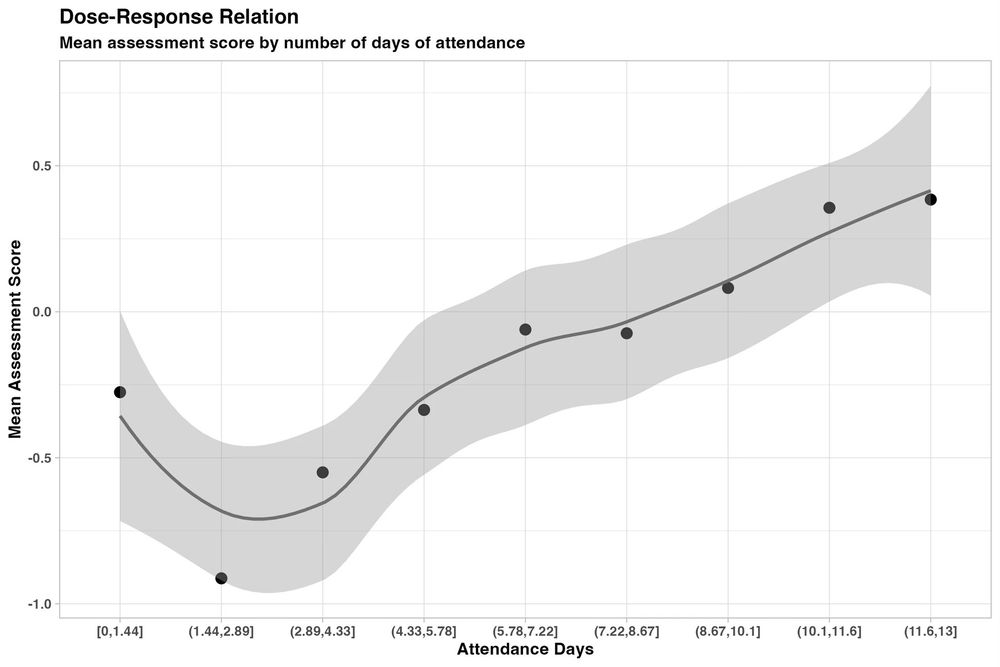
January 15, 2025 at 8:58 PM
New randomized, controlled trial by the World Bank of students using GPT-4 as a tutor in Nigeria. Six weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interventions.
And it helped all students, especially girls who were initially behind.
And it helped all students, especially girls who were initially behind.
Reposted by Ryan Dickerson

✨ Bluesky search tips and tricks
Add `from:me` to find your own posts
Add `to:me` to find replies/posts that mention you
Add `since:YYYY-MM-DD` and/or `until:YYYY-MM-DD` to specify a date range
Add `domain:theonion.com` to find posts linking to The Onion
See more at
bsky.social/about/blog/0...
Add `from:me` to find your own posts
Add `to:me` to find replies/posts that mention you
Add `since:YYYY-MM-DD` and/or `until:YYYY-MM-DD` to specify a date range
Add `domain:theonion.com` to find posts linking to The Onion
See more at
bsky.social/about/blog/0...

Tips and Tricks for Bluesky Search - Bluesky
Let’s dive into all the tips and tricks for advanced Bluesky search!
bsky.social
January 14, 2025 at 9:12 PM
✨ Bluesky search tips and tricks
Add `from:me` to find your own posts
Add `to:me` to find replies/posts that mention you
Add `since:YYYY-MM-DD` and/or `until:YYYY-MM-DD` to specify a date range
Add `domain:theonion.com` to find posts linking to The Onion
See more at
bsky.social/about/blog/0...
Add `from:me` to find your own posts
Add `to:me` to find replies/posts that mention you
Add `since:YYYY-MM-DD` and/or `until:YYYY-MM-DD` to specify a date range
Add `domain:theonion.com` to find posts linking to The Onion
See more at
bsky.social/about/blog/0...
Reposted by Ryan Dickerson
Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time.
- Better memory efficiency and improved performance.
- Perfect for handling longer context windows
- Better memory efficiency and improved performance.
- Perfect for handling longer context windows

January 14, 2025 at 6:47 AM
Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time.
- Better memory efficiency and improved performance.
- Perfect for handling longer context windows
- Better memory efficiency and improved performance.
- Perfect for handling longer context windows
Reposted by Ryan Dickerson

Anthropic, as one of the first frontier AI labs, received ISO 42001 certification

January 14, 2025 at 9:14 AM
Anthropic, as one of the first frontier AI labs, received ISO 42001 certification
Reposted by Ryan Dickerson
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Instead of self improving a single LLM, they self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
Project: llm-multiagent-ft.github.io
Instead of self improving a single LLM, they self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
Project: llm-multiagent-ft.github.io
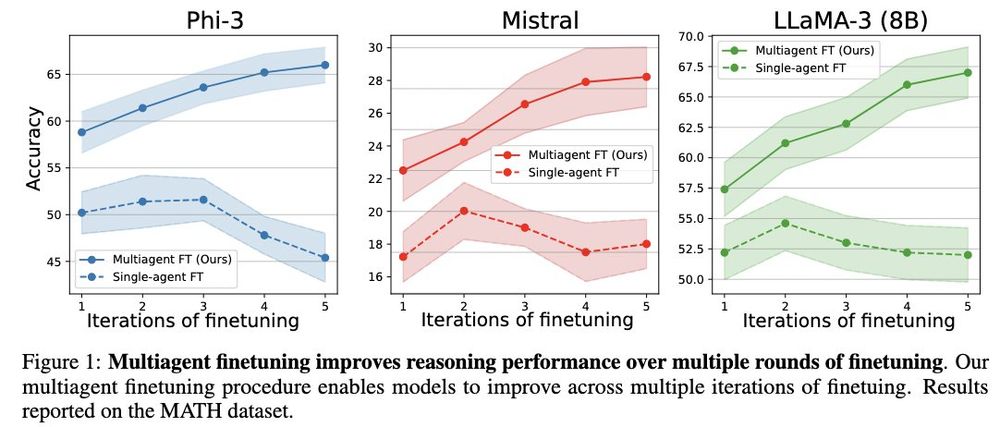
January 14, 2025 at 12:38 AM
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Instead of self improving a single LLM, they self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
Project: llm-multiagent-ft.github.io
Instead of self improving a single LLM, they self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
Project: llm-multiagent-ft.github.io
Reposted by Ryan Dickerson
Trying a little experiment: "Hey, Claude, turn the first four stanzas of The Lady of Shalott into a film by describing 8 second clips..."
I pasted those into veo 2 verbatim & overlayed the poem for reference (I also asked for one additional scene revealing the Lady, again using the verbatim prompt)
I pasted those into veo 2 verbatim & overlayed the poem for reference (I also asked for one additional scene revealing the Lady, again using the verbatim prompt)
January 12, 2025 at 6:21 AM
Trying a little experiment: "Hey, Claude, turn the first four stanzas of The Lady of Shalott into a film by describing 8 second clips..."
I pasted those into veo 2 verbatim & overlayed the poem for reference (I also asked for one additional scene revealing the Lady, again using the verbatim prompt)
I pasted those into veo 2 verbatim & overlayed the poem for reference (I also asked for one additional scene revealing the Lady, again using the verbatim prompt)
Reposted by Ryan Dickerson
It seems like Google is working on Interactive Mindmaps for NotebookLM 👀
"Generate an interactive mind map for all the sources in the notebook"
"Generate an interactive mind map for all the sources in the notebook"

January 10, 2025 at 11:20 PM
It seems like Google is working on Interactive Mindmaps for NotebookLM 👀
"Generate an interactive mind map for all the sources in the notebook"
"Generate an interactive mind map for all the sources in the notebook"
Reposted by Ryan Dickerson
What does it mean to "use" test-time compute wisely? How to train to do so? How to measure that scaling it is useful?
"Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem"
blog.ml.cmu.edu/2025/01/08/o...
"Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem"
blog.ml.cmu.edu/2025/01/08/o...

Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem
Figure 1: Training models to optimize test-time compute and learn "how to discover" correct responses, as opposed to the traditional learning paradigm of learning "what answer" to output.
The major...
blog.ml.cmu.edu
January 10, 2025 at 5:20 AM
What does it mean to "use" test-time compute wisely? How to train to do so? How to measure that scaling it is useful?
"Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem"
blog.ml.cmu.edu/2025/01/08/o...
"Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem"
blog.ml.cmu.edu/2025/01/08/o...
Reposted by Ryan Dickerson

I have a draft of my introduction to cooperative multi-agent reinforcement learning on arxiv. Check it out and let me know any feedback you have. The plan is to polish and extend the material into a more comprehensive text with Frans Oliehoek.
arxiv.org/abs/2405.06161
arxiv.org/abs/2405.06161

A First Introduction to Cooperative Multi-Agent Reinforcement Learning
Multi-agent reinforcement learning (MARL) has exploded in popularity in recent years. While numerous approaches have been developed, they can be broadly categorized into three main types: centralized ...
arxiv.org
January 7, 2025 at 4:25 PM
I have a draft of my introduction to cooperative multi-agent reinforcement learning on arxiv. Check it out and let me know any feedback you have. The plan is to polish and extend the material into a more comprehensive text with Frans Oliehoek.
arxiv.org/abs/2405.06161
arxiv.org/abs/2405.06161
Reposted by Ryan Dickerson
Simulated AI hospital where “doctor” agents work w/ simulated “patients” & improve: “After treating around ten thousand patients, the evolved doctor agent achieves a state-of-the-art accuracy of 93.06% on a subset of the MedQA dataset that covers major respiratory diseases” arxiv.org/abs/2405.02957



January 8, 2025 at 3:16 AM
Simulated AI hospital where “doctor” agents work w/ simulated “patients” & improve: “After treating around ten thousand patients, the evolved doctor agent achieves a state-of-the-art accuracy of 93.06% on a subset of the MedQA dataset that covers major respiratory diseases” arxiv.org/abs/2405.02957
Reposted by Ryan Dickerson
Hi folks! I'm excited to be on BlueSky! I'm looking forward to posting about computer science research, ML, scientific advances, tasty food, nature, and making groan-worthy puns.
January 5, 2025 at 9:48 PM
Hi folks! I'm excited to be on BlueSky! I'm looking forward to posting about computer science research, ML, scientific advances, tasty food, nature, and making groan-worthy puns.
Reposted by Ryan Dickerson
Cursor now can "apply" with 5k tokens per second 🤯
How soon will we be getting isomorphic code that changes as you speak? 👀
How soon will we be getting isomorphic code that changes as you speak? 👀
December 31, 2024 at 4:25 PM
Cursor now can "apply" with 5k tokens per second 🤯
How soon will we be getting isomorphic code that changes as you speak? 👀
How soon will we be getting isomorphic code that changes as you speak? 👀

Reposted by Ryan Dickerson

New work from my team at Anthropic in collaboration with Redwood Research. I think this is plausibly the most important AGI safety result of the year. Cross-posting the thread below:

December 18, 2024 at 5:47 PM
New work from my team at Anthropic in collaboration with Redwood Research. I think this is plausibly the most important AGI safety result of the year. Cross-posting the thread below: