



Mart Roosmaa
@roosmaa.net
👨💻 Programming (Go, Rust) & homelab (k8s) | 📺 Anime | 🪛 3D printing & electronics | 🎮 Gaming
He/him.
He/him.
Pinned
Mart Roosmaa
@roosmaa.net
· 4d
Put together a bsky feed for posts related to running AI locally:
bsky.app/profile/did:...
bsky.app/profile/did:...
@atproto.com need some help debugging bsky backend querying my feed generator. At "coldstart" bsky produces a http5xx. From my server access logs I can see it hit the .well-known/did.json and then nothing else. After refreshing the bsky page, it starts working and properly hitting the xrpc API.
December 20, 2025 at 10:49 AM
@atproto.com need some help debugging bsky backend querying my feed generator. At "coldstart" bsky produces a http5xx. From my server access logs I can see it hit the .well-known/did.json and then nothing else. After refreshing the bsky page, it starts working and properly hitting the xrpc API.
Gnome has been my desktop of choice for the better part of my life. Giving back a little is the least I can do.

December 19, 2025 at 12:07 PM
Gnome has been my desktop of choice for the better part of my life. Giving back a little is the least I can do.
2 of the 6 consumer SSDs (that I bought for my NAS) have died in less than a year. Both of them from the same brand - fanxiang. The other 2 brands - Kingspec & Crucial - are still going strong.
Be smart, do NOT trust fanxiang with your data.
Be smart, do NOT trust fanxiang with your data.
December 18, 2025 at 3:22 PM
2 of the 6 consumer SSDs (that I bought for my NAS) have died in less than a year. Both of them from the same brand - fanxiang. The other 2 brands - Kingspec & Crucial - are still going strong.
Be smart, do NOT trust fanxiang with your data.
Be smart, do NOT trust fanxiang with your data.
Put together a bsky feed for posts related to running AI locally:
bsky.app/profile/did:...
bsky.app/profile/did:...
December 18, 2025 at 7:46 AM
Put together a bsky feed for posts related to running AI locally:
bsky.app/profile/did:...
bsky.app/profile/did:...
Reposted by Mart Roosmaa

Openness for Nemotron includes open evaluation! Eval transparency completes the last puzzle in the E2E repro lifecycle for LLMs. Check out our step-by-step blog on how to use the same pipeline we used for the evaluation of Nemotron 3 Nano through Nemo Evaluator: huggingface.co/blog/nvidia/...

December 17, 2025 at 9:38 PM
Openness for Nemotron includes open evaluation! Eval transparency completes the last puzzle in the E2E repro lifecycle for LLMs. Check out our step-by-step blog on how to use the same pipeline we used for the evaluation of Nemotron 3 Nano through Nemo Evaluator: huggingface.co/blog/nvidia/...
Reposted by Mart Roosmaa

If you've been meaning to give Zed a spin during the slower season, now's the time. Use code ZEDSEASON at checkout for $15 in LLM spend on us. Limited supply, valid through Dec 31.
Already using Zed? Share this with someone who needs a nudge.
Already using Zed? Share this with someone who needs a nudge.

December 15, 2025 at 4:23 PM
If you've been meaning to give Zed a spin during the slower season, now's the time. Use code ZEDSEASON at checkout for $15 in LLM spend on us. Limited supply, valid through Dec 31.
Already using Zed? Share this with someone who needs a nudge.
Already using Zed? Share this with someone who needs a nudge.
The main thing Ollama (and LM studio) has going for it, is that everyone has integrated it everywhere. IDEs, Obsidian plugins, self-hostable AI apps.
December 12, 2025 at 1:56 PM
The main thing Ollama (and LM studio) has going for it, is that everyone has integrated it everywhere. IDEs, Obsidian plugins, self-hostable AI apps.
I tried to give Ollama a fair chance. I was tempted by the automatic VRAM management it does. But everything else is just inferior to llama.cpp. The modelfile concept is just weird. No support for sharded GGUFs. And why use Go templates when all of the ecosystem uses Jinja2?
December 12, 2025 at 8:48 AM
I tried to give Ollama a fair chance. I was tempted by the automatic VRAM management it does. But everything else is just inferior to llama.cpp. The modelfile concept is just weird. No support for sharded GGUFs. And why use Go templates when all of the ecosystem uses Jinja2?
I did not understand HuggingFace before. I had done some LLM courses out of curiosity, but HuggingFace didn't click. Until I started running things locally. Base models, adapters, fine-tunes, quantizations. I get it now!
December 11, 2025 at 5:13 PM
I did not understand HuggingFace before. I had done some LLM courses out of curiosity, but HuggingFace didn't click. Until I started running things locally. Base models, adapters, fine-tunes, quantizations. I get it now!
At some point I need to more seriously test out ROCm vs Vulkan performance for local models I use. Haven't spent much time on ROCm currently as AMD broke it in the latest linux-firmware release. It has been reverted already, but not sure what the release cadence is there.
December 11, 2025 at 7:38 AM
At some point I need to more seriously test out ROCm vs Vulkan performance for local models I use. Haven't spent much time on ROCm currently as AMD broke it in the latest linux-firmware release. It has been reverted already, but not sure what the release cadence is there.
llama.cpp just recently merged in (github.com/ggml-org/...) support for serving multiple models, effectively making llama-swap a lot less useful. I love it. Just makes me wonder if llama.cpp is intending to compete with ollama (and LM Studio to some extent).

server: introduce API for serving / loading / unloading multiple models by ngxson · Pull Request #17470 · ggml-org/llama.cpp
Close #16487
Close #16256
Close #17556
For more detailes on WebUI changes, please refer to this comment from @allozaur : #17470 (comment)
This PR introduces the ability to use multiple models, unlo...
github.com
December 10, 2025 at 6:58 PM
llama.cpp just recently merged in (github.com/ggml-org/...) support for serving multiple models, effectively making llama-swap a lot less useful. I love it. Just makes me wonder if llama.cpp is intending to compete with ollama (and LM Studio to some extent).
I wish @zed.dev's Open AI compatible provider support would attempt to auto-detect the models from the server. It's such a chore to manage the models manually in settings.json.
December 9, 2025 at 5:30 PM
I wish @zed.dev's Open AI compatible provider support would attempt to auto-detect the models from the server. It's such a chore to manage the models manually in settings.json.
After a bit of experimentation, I've settled on llama-swap and llama.cpp combo to run my local models. LM Studios was a bunch of UI that I wasn't going to use, and having the option to go and tweak every lever that llama.cpp has feels good.
December 9, 2025 at 12:38 PM
After a bit of experimentation, I've settled on llama-swap and llama.cpp combo to run my local models. LM Studios was a bunch of UI that I wasn't going to use, and having the option to go and tweak every lever that llama.cpp has feels good.
ISP: We see your bandwidth usage has spiked...
Me: Oh don't mind me, I'm just downloading some models from HuggingFace.
Me: Oh don't mind me, I'm just downloading some models from HuggingFace.
December 8, 2025 at 3:42 PM
ISP: We see your bandwidth usage has spiked...
Me: Oh don't mind me, I'm just downloading some models from HuggingFace.
Me: Oh don't mind me, I'm just downloading some models from HuggingFace.
Got myself @frame.work desktop as an early christmas present. Been having a blast setting it up and playing around with local LLMs.
December 8, 2025 at 7:19 AM
Got myself @frame.work desktop as an early christmas present. Been having a blast setting it up and playing around with local LLMs.
Switched my personal email from Proton to mailbox.org.
Webmail UI is a slight downgrade, but the knobs you get for spam control, etc is wonderful. It's also cheaper. And my main reason for switching - up to 25 custom domains.
Webmail UI is a slight downgrade, but the knobs you get for spam control, etc is wonderful. It's also cheaper. And my main reason for switching - up to 25 custom domains.
August 8, 2025 at 10:54 AM
Switched my personal email from Proton to mailbox.org.
Webmail UI is a slight downgrade, but the knobs you get for spam control, etc is wonderful. It's also cheaper. And my main reason for switching - up to 25 custom domains.
Webmail UI is a slight downgrade, but the knobs you get for spam control, etc is wonderful. It's also cheaper. And my main reason for switching - up to 25 custom domains.
Ahh, the wonders of modern world. Junie writes some unit-tests, and then spends all the monthly token quota attempting get the tests passing. I guess the fact that it didn't just remove the tests could be considered a win.
July 30, 2025 at 8:44 PM
Ahh, the wonders of modern world. Junie writes some unit-tests, and then spends all the monthly token quota attempting get the tests passing. I guess the fact that it didn't just remove the tests could be considered a win.
I wrote a bunch of implementation docs for a browser extension. Then let Gemini 2.5 Pro make an implementation plan out of it, in distinct stages. And now I'm feeding these into Junie one by one, and trying not to criticize the output. Vibing they call it. I call it stressful.
July 30, 2025 at 7:12 PM
I wrote a bunch of implementation docs for a browser extension. Then let Gemini 2.5 Pro make an implementation plan out of it, in distinct stages. And now I'm feeding these into Junie one by one, and trying not to criticize the output. Vibing they call it. I call it stressful.
Updating Windows is SLOOOW and seemingly never ending. Downloading 100mb update takes more time than downloading 500GB game on Steam. After restarting to finish the install, for 5 minutes it claims there's no more updates, and then it finds yet another one. I think I've already done 3 restarts...
July 26, 2025 at 9:49 AM
Updating Windows is SLOOOW and seemingly never ending. Downloading 100mb update takes more time than downloading 500GB game on Steam. After restarting to finish the install, for 5 minutes it claims there's no more updates, and then it finds yet another one. I think I've already done 3 restarts...
Take Zed's code, throw out half (or more) and build a blazing fast Obsidian clone? 🤔
July 25, 2025 at 4:17 PM
Take Zed's code, throw out half (or more) and build a blazing fast Obsidian clone? 🤔
As the first task for JetBrains Junie, I had it move some test code around. The UI is super nice - very easy to jump into diffs & terminal out put of different commands being executed. The calls to underlying LLM models seemed a lot slower than claude-code, though.
July 19, 2025 at 8:45 AM
As the first task for JetBrains Junie, I had it move some test code around. The UI is super nice - very easy to jump into diffs & terminal out put of different commands being executed. The calls to underlying LLM models seemed a lot slower than claude-code, though.
My 30-day Claude Pro subscription is expiring tomorrow. Next, will give the JetBrains AI Pro (the cheaper option) a go for a month to try out Junie.
Based on the amount of tokens claude-code has gone through in a month, I'm expecting to consume the allocated token quota fairly quickly with Junie.
Based on the amount of tokens claude-code has gone through in a month, I'm expecting to consume the allocated token quota fairly quickly with Junie.
July 13, 2025 at 4:18 PM
My 30-day Claude Pro subscription is expiring tomorrow. Next, will give the JetBrains AI Pro (the cheaper option) a go for a month to try out Junie.
Based on the amount of tokens claude-code has gone through in a month, I'm expecting to consume the allocated token quota fairly quickly with Junie.
Based on the amount of tokens claude-code has gone through in a month, I'm expecting to consume the allocated token quota fairly quickly with Junie.
Reposted by Mart Roosmaa

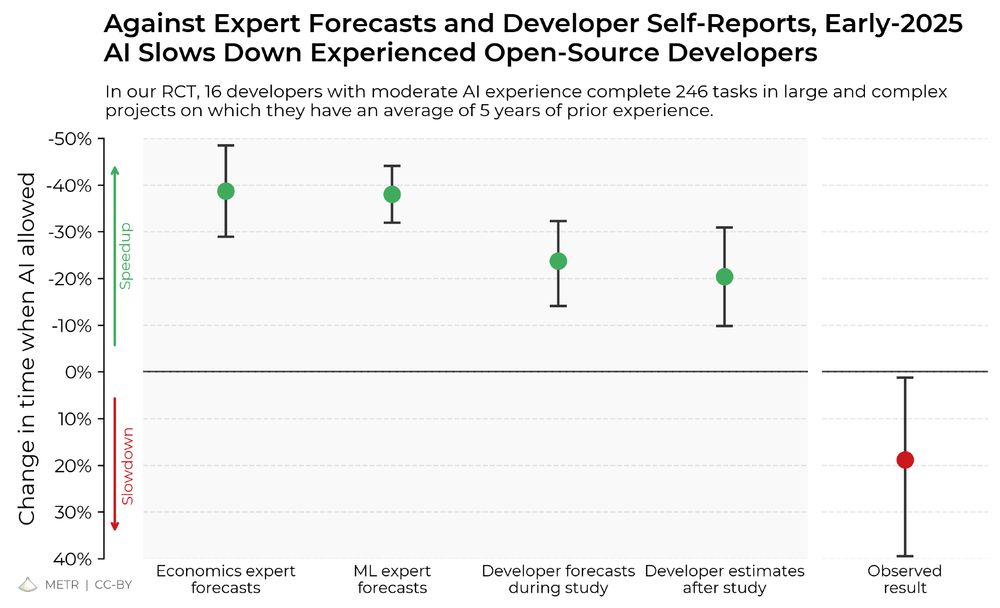
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
July 10, 2025 at 7:47 PM
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
Are working parents over-employed? 🤔 It sure does feel like juggling several jobs...
July 5, 2025 at 8:26 PM
Are working parents over-employed? 🤔 It sure does feel like juggling several jobs...