


Subbarao Kambhampati (కంభంపాటి సుబ్బారావు)
@rao2z.bsky.social
AI researcher & teacher at SCAI, ASU. Former President of AAAI & Chair of AAAS Sec T. Here to tweach #AI. YouTube Ch: http://bit.ly/38twrAV Twitter: rao2z
Pinned

A meta list of all my 2024 #SundayHarangue's
Not quite sure why, but I apparently wrote sixteen long #AI related Sunday Harangues in 2024.. 😅.
Most were first posted on twitter.
👉https://x.com/rao2z/status/1873214567091966189
Not quite sure why, but I apparently wrote sixteen long #AI related Sunday Harangues in 2024.. 😅.
Most were first posted on twitter.
👉https://x.com/rao2z/status/1873214567091966189
Does it really make sense to think of inference efficiency in terms of the number of tokens produced?
No. 👇
x.com/i/status/202...
No. 👇
x.com/i/status/202...
x.com
February 16, 2026 at 8:39 PM
Does it really make sense to think of inference efficiency in terms of the number of tokens produced?
No. 👇
x.com/i/status/202...
No. 👇
x.com/i/status/202...
Here are the recordings of two lectures on 𝗣𝗹𝗮𝗻𝗻𝗶𝗻𝗴 & 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗖𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀 𝗼𝗳 𝗟𝗟𝗠𝘀/𝗟𝗥𝗠𝘀 that I gave this week at Melbourne ML Summer School (lnkd.in/g7rxg9sw).
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 1: youtube.com/watch?v=_PPV...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 2: youtube.com/watch?v=fKlm...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 1: youtube.com/watch?v=_PPV...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 2: youtube.com/watch?v=fKlm...


February 13, 2026 at 3:31 PM
Here are the recordings of two lectures on 𝗣𝗹𝗮𝗻𝗻𝗶𝗻𝗴 & 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗖𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀 𝗼𝗳 𝗟𝗟𝗠𝘀/𝗟𝗥𝗠𝘀 that I gave this week at Melbourne ML Summer School (lnkd.in/g7rxg9sw).
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 1: youtube.com/watch?v=_PPV...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 2: youtube.com/watch?v=fKlm...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 1: youtube.com/watch?v=_PPV...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 2: youtube.com/watch?v=fKlm...
A common theme in our work these past few years has been pushing back on facile anthropomorphizations (and/or efforts that bring questionable/discredited Cognitive Science metaphors) to LLMs.. So I enjoyed giving this talk at @ivado.bsky.social yesterday... www.youtube.com/watch?v=CoyS...

Anthropomorphization Sins in Modern AI (or Perils of Prematurely Applying Lens of Cognition to LLMs)
YouTube video by Subbarao Kambhampati
www.youtube.com
January 28, 2026 at 1:03 PM
A common theme in our work these past few years has been pushing back on facile anthropomorphizations (and/or efforts that bring questionable/discredited Cognitive Science metaphors) to LLMs.. So I enjoyed giving this talk at @ivado.bsky.social yesterday... www.youtube.com/watch?v=CoyS...
Three of my talks in India last month--at @iitdelhi.bsky.social,
@msftresearch.bsky.social India and at IndoML Symposium--were "On the Mythos of LRM Thinking Tokens." Here is a recording of one of them--the talk I gave at MSR India.
www.youtube.com/watch?v=fCQX...
@msftresearch.bsky.social India and at IndoML Symposium--were "On the Mythos of LRM Thinking Tokens." Here is a recording of one of them--the talk I gave at MSR India.
www.youtube.com/watch?v=fCQX...

On the Mythos of LRM "Thinking Tokens" (Talk @ Microsoft Research, India; 12/16/2025)
YouTube video by Subbarao Kambhampati
www.youtube.com
January 6, 2026 at 9:44 PM
Three of my talks in India last month--at @iitdelhi.bsky.social,
@msftresearch.bsky.social India and at IndoML Symposium--were "On the Mythos of LRM Thinking Tokens." Here is a recording of one of them--the talk I gave at MSR India.
www.youtube.com/watch?v=fCQX...
@msftresearch.bsky.social India and at IndoML Symposium--were "On the Mythos of LRM Thinking Tokens." Here is a recording of one of them--the talk I gave at MSR India.
www.youtube.com/watch?v=fCQX...
ICYMI, here is my keynote on the semantics of LRM "thinking traces" at #NeurIPS2025 workshop on Multimodal Algorithmic Reasoning. It's a unified view of the seven papers we presented at the conference workshops. Special thanks to the engaged audience..🙏
www.youtube.com/watch?v=rvby...
www.youtube.com/watch?v=rvby...

Talk on the semantics of "Thinking Traces" (Keynote at NeurIPS2025 MAR Workshop)
YouTube video by Subbarao Kambhampati
www.youtube.com
December 9, 2025 at 1:11 PM
ICYMI, here is my keynote on the semantics of LRM "thinking traces" at #NeurIPS2025 workshop on Multimodal Algorithmic Reasoning. It's a unified view of the seven papers we presented at the conference workshops. Special thanks to the engaged audience..🙏
www.youtube.com/watch?v=rvby...
www.youtube.com/watch?v=rvby...
[On using Continuous Latent Space Vectors in the context windows of Transformers and LLMs] #SundayHarangue
👉 x.com/rao2z/status...
👉 x.com/rao2z/status...

November 3, 2025 at 3:16 PM
[On using Continuous Latent Space Vectors in the context windows of Transformers and LLMs] #SundayHarangue
👉 x.com/rao2z/status...
👉 x.com/rao2z/status...
My talk at Samsung AI Forum yesterday
www.youtube.com/watch?v=L2nA...
www.youtube.com/watch?v=L2nA...

LRMs and Agentic AI (Talk at Samsung AI Forum)
YouTube video by Subbarao Kambhampati
www.youtube.com
September 16, 2025 at 5:39 PM
My talk at Samsung AI Forum yesterday
www.youtube.com/watch?v=L2nA...
www.youtube.com/watch?v=L2nA...
In the year since LRMs ("reasoning models") hit the scene, we have been trying to understand, analyze and demystify them.. Here are our efforts to date--conveniently all in one place..👇
www.linkedin.com/posts/subbar...
www.linkedin.com/posts/subbar...

In the year since LRMs ("reasoning models") hit the scene, we have been trying to understand, analyze and demystify them.. Here are our efforts to date--conveniently all in one… | Subbarao K...
In the year since LRMs ("reasoning models") hit the scene, we have been trying to understand, analyze and demystify them.. Here are our efforts to date--conveniently all in one place..
(𝗙𝗶𝗿𝘀𝘁..) 𝗘𝘃𝗮𝗹...
www.linkedin.com
September 14, 2025 at 10:00 PM
In the year since LRMs ("reasoning models") hit the scene, we have been trying to understand, analyze and demystify them.. Here are our efforts to date--conveniently all in one place..👇
www.linkedin.com/posts/subbar...
www.linkedin.com/posts/subbar...
𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐯𝐞 𝐓𝐡𝐢𝐧𝐤𝐢𝐧𝐠? The anthropomorphization of LRM intermediate tokens as thinking begat a cottage industry to "get efficiency by shortening thinking." We ask: 𝗜𝘀 𝗖𝗼𝗧 𝗹𝗲𝗻𝗴𝘁𝗵 𝗿𝗲𝗮𝗹𝗹𝘆 𝗮 𝗿𝗲𝗳𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗼𝗳 𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝗵𝗮𝗿𝗱𝗻𝗲𝘀𝘀 𝗼𝗿 𝗶𝘀 𝗶𝘁 𝗺𝗼𝗿𝗲 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝘃𝗲? 👉 www.linkedin.com/posts/subbar...

September 10, 2025 at 4:50 PM
𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐯𝐞 𝐓𝐡𝐢𝐧𝐤𝐢𝐧𝐠? The anthropomorphization of LRM intermediate tokens as thinking begat a cottage industry to "get efficiency by shortening thinking." We ask: 𝗜𝘀 𝗖𝗼𝗧 𝗹𝗲𝗻𝗴𝘁𝗵 𝗿𝗲𝗮𝗹𝗹𝘆 𝗮 𝗿𝗲𝗳𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗼𝗳 𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝗵𝗮𝗿𝗱𝗻𝗲𝘀𝘀 𝗼𝗿 𝗶𝘀 𝗶𝘁 𝗺𝗼𝗿𝗲 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝘃𝗲? 👉 www.linkedin.com/posts/subbar...
Rejecting papers in #AI Conferences because of "resource constraints" is shooting ourselves in the foot as a community; use Findings.. #SundayHarangue 👇
x.com/rao2z/status...
x.com/rao2z/status...

Subbarao Kambhampati (కంభంపాటి సుబ్బారావు) on X: "Rejecting papers in #AI Conferences because of "resource constraints" is shooting ourselves in the foot as a community; use Findings.. #SundayHarangue By now, we have all know that top AI conferences are oversubscribed (in terms of paper submissions), and have heard that that" / X
Rejecting papers in #AI Conferences because of "resource constraints" is shooting ourselves in the foot as a community; use Findings.. #SundayHarangue By now, we have all know that top AI conferences are oversubscribed (in terms of paper submissions), and have heard that that
x.com
August 31, 2025 at 7:58 PM
Rejecting papers in #AI Conferences because of "resource constraints" is shooting ourselves in the foot as a community; use Findings.. #SundayHarangue 👇
x.com/rao2z/status...
x.com/rao2z/status...
Proofs are not reasoning traces & I/O Format Language shouldn't be much of an issue for LLMs + other things #SundayHarangue (Special IMO edition). 🧵 👇
x.com/rao2z/status...
x.com/rao2z/status...
Subbarao Kambhampati (కంభంపాటి సుబ్బారావు) on X: "Proofs are not reasoning traces & I/O Format Language shouldn't be much of an issue for LLMs #SundayHarangue (Special IMO edition). 1/ My feed these last couple of days of IMO discussions has been full of comments that seem to conflate LRM intermediate tokens (aka reasoning" / X
Proofs are not reasoning traces & I/O Format Language shouldn't be much of an issue for LLMs #SundayHarangue (Special IMO edition). 1/ My feed these last couple of days of IMO discussions has been full of comments that seem to conflate LRM intermediate tokens (aka reasoning
x.com
July 22, 2025 at 1:46 PM
Proofs are not reasoning traces & I/O Format Language shouldn't be much of an issue for LLMs + other things #SundayHarangue (Special IMO edition). 🧵 👇
x.com/rao2z/status...
x.com/rao2z/status...
Both LLMs and LRMs are upper bounded by humanity's knowledge closure. True scientific discoveries are, by definition, outside of that closure. Ergo, LLMs/LRMs are great force multipliers to us; but don't support "Nobel this weekend" hype..
👉 www.linkedin.com/posts/subbar...
👉 www.linkedin.com/posts/subbar...
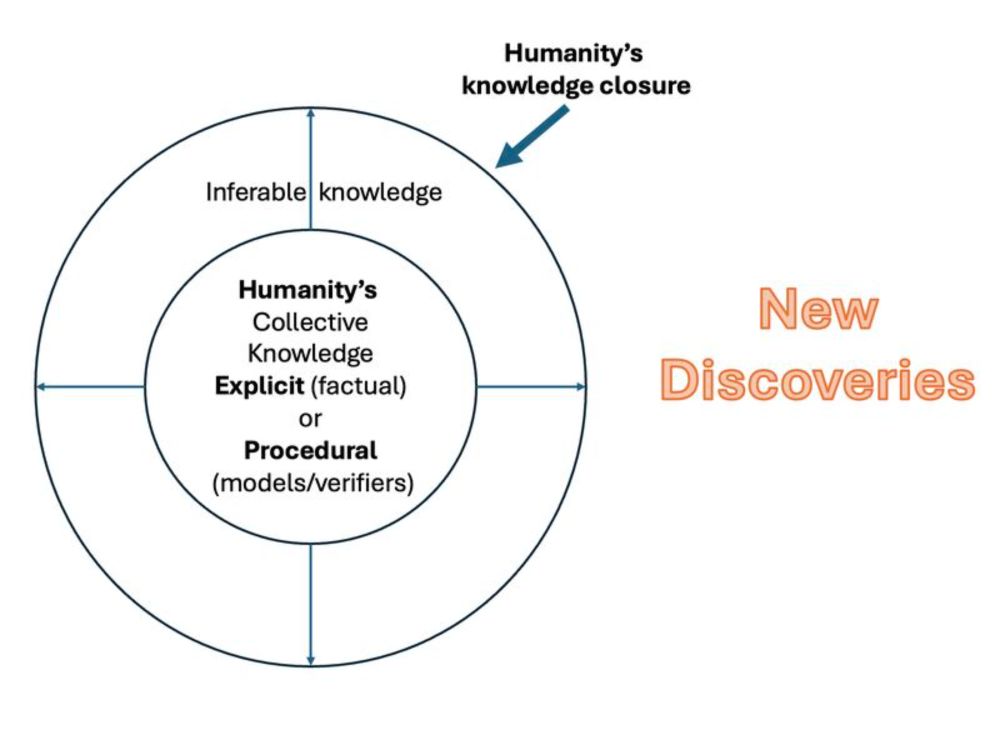
Neither LLMs nor LRMs have the ability to go beyond the humanity's knowledge closure--which is needed for true discoveries. | Subbarao Kambhampati
Neither LLMs nor LRMs have the ability to go beyond the humanity's knowledge closure--which is needed for true discoveries. Both are beholden to the collected knowledge of the humanity (whether de...
www.linkedin.com
July 19, 2025 at 10:18 PM
Both LLMs and LRMs are upper bounded by humanity's knowledge closure. True scientific discoveries are, by definition, outside of that closure. Ergo, LLMs/LRMs are great force multipliers to us; but don't support "Nobel this weekend" hype..
👉 www.linkedin.com/posts/subbar...
👉 www.linkedin.com/posts/subbar...
Computational Complexity is the wrong measure for LRMs (as it was for LLMs)--think distributional distance instead #SundayHarangue (yes, we're back!)
👉 x.com/rao2z/status...
👉 x.com/rao2z/status...

July 13, 2025 at 9:42 PM
Computational Complexity is the wrong measure for LRMs (as it was for LLMs)--think distributional distance instead #SundayHarangue (yes, we're back!)
👉 x.com/rao2z/status...
👉 x.com/rao2z/status...
A̶̶̶I̶̶̶ ̶ ̶ ̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶G̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶G̶e̶n̶e̶r̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶S̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶S̶u̶p̶e̶r̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)
ASDI (Artificial Super Duper Intelligence)
Don't get stuck with yesterday's hypeonyms!
Dare to get to the next level!
#AIAphorisms
̶̶̶A̶̶̶G̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶G̶e̶n̶e̶r̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶S̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶S̶u̶p̶e̶r̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)
ASDI (Artificial Super Duper Intelligence)
Don't get stuck with yesterday's hypeonyms!
Dare to get to the next level!
#AIAphorisms
June 23, 2025 at 10:36 PM
A̶̶̶I̶̶̶ ̶ ̶ ̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶G̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶G̶e̶n̶e̶r̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶S̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶S̶u̶p̶e̶r̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)
ASDI (Artificial Super Duper Intelligence)
Don't get stuck with yesterday's hypeonyms!
Dare to get to the next level!
#AIAphorisms
̶̶̶A̶̶̶G̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶G̶e̶n̶e̶r̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶S̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶S̶u̶p̶e̶r̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)
ASDI (Artificial Super Duper Intelligence)
Don't get stuck with yesterday's hypeonyms!
Dare to get to the next level!
#AIAphorisms
For anyone interested, here are the videos of the three ~50min each lectures on the reasoning/planning capabilities of LLMs/LRMs that I gave at #ACDL2025 in Riva Del Sole resort last week. 1/
www.youtube.com/playlist?lis...
www.youtube.com/playlist?lis...

ACDL Summer School Lectures on Planning/Reasoning Abilities of LLMs/LRMs - YouTube
www.youtube.com
June 19, 2025 at 10:27 PM
For anyone interested, here are the videos of the three ~50min each lectures on the reasoning/planning capabilities of LLMs/LRMs that I gave at #ACDL2025 in Riva Del Sole resort last week. 1/
www.youtube.com/playlist?lis...
www.youtube.com/playlist?lis...
Reposted by Subbarao Kambhampati (కంభంపాటి సుబ్బారావు)

...it basically confirmed what is already well-established: LLMs (& LRMs & "LLM agents") have trouble w/ problems that require many steps of reasoning/planning.
See, e.g., lots of recent papers by Subbarao Kambhampati's group at ASU. (2/2)
See, e.g., lots of recent papers by Subbarao Kambhampati's group at ASU. (2/2)
June 9, 2025 at 10:53 PM
...it basically confirmed what is already well-established: LLMs (& LRMs & "LLM agents") have trouble w/ problems that require many steps of reasoning/planning.
See, e.g., lots of recent papers by Subbarao Kambhampati's group at ASU. (2/2)
See, e.g., lots of recent papers by Subbarao Kambhampati's group at ASU. (2/2)
An AGI-wannabe reasoning model whining that it couldn't handle a problem because its context window isn't big enough is like a superman-wannabe little kid protesting that he couldn't add those numbers because he doesn't have enough fingers and toes.. #AIAphorisms
June 16, 2025 at 12:47 AM
An AGI-wannabe reasoning model whining that it couldn't handle a problem because its context window isn't big enough is like a superman-wannabe little kid protesting that he couldn't add those numbers because he doesn't have enough fingers and toes.. #AIAphorisms
Reposted by Subbarao Kambhampati (కంభంపాటి సుబ్బారావు)

"our counter-intuitive results demonstrate ways in which common interpretations of Large Reasoning Models may be anthropomorphizations or simplifications" arxiv.org/abs/2505.13775

Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens
Recent impressive results from large reasoning models have been interpreted as a triumph of Chain of Thought (CoT), and especially of the process of training on CoTs sampled from base LLMs in order to...
arxiv.org
June 1, 2025 at 1:30 PM
"our counter-intuitive results demonstrate ways in which common interpretations of Large Reasoning Models may be anthropomorphizations or simplifications" arxiv.org/abs/2505.13775
The transformer expressiveness results are often a bit of a red herring as there tends to be a huge gap between what can be expressed in transformers, and what can be learned with gradient descent. Mind the Gap, a new paper with
Lucas Saldyt dives deeper into this issue 👇👇
x.com/SaldytLucas/...
Lucas Saldyt dives deeper into this issue 👇👇
x.com/SaldytLucas/...

Lucas Saldyt on X: "Neural networks can express more than they learn, creating expressivity-trainability gaps. Our paper, “Mind The Gap,” shows neural networks best learn parallel algorithms, and analyzes gaps in faithfulness and effectiveness. @rao2z https://t.co/8YjxPkXFu0" / X
Neural networks can express more than they learn, creating expressivity-trainability gaps. Our paper, “Mind The Gap,” shows neural networks best learn parallel algorithms, and analyzes gaps in faithfulness and effectiveness. @rao2z https://t.co/8YjxPkXFu0
x.com
May 30, 2025 at 1:59 PM
The transformer expressiveness results are often a bit of a red herring as there tends to be a huge gap between what can be expressed in transformers, and what can be learned with gradient descent. Mind the Gap, a new paper with
Lucas Saldyt dives deeper into this issue 👇👇
x.com/SaldytLucas/...
Lucas Saldyt dives deeper into this issue 👇👇
x.com/SaldytLucas/...
Anthropomorphization of intermediate tokens as reasoning/thinking traces isn't quite a harmless fad, and may be pushing LRM research into questionable directions.. So we decided to put together a more complete argument. Paper 👉 arxiv.org/pdf/2504.09762 (Twitter thread: x.com/rao2z/status...)

May 28, 2025 at 1:41 PM
Anthropomorphization of intermediate tokens as reasoning/thinking traces isn't quite a harmless fad, and may be pushing LRM research into questionable directions.. So we decided to put together a more complete argument. Paper 👉 arxiv.org/pdf/2504.09762 (Twitter thread: x.com/rao2z/status...)
This RLiNo? paper (arxiv.org/abs/2505.13697) lead by Soumya Samineni and Durgesh_kalwar dives into the MDP model used in the RL post-training methods inspired by DeepSeek R1, and asks if some of the idiosyncrasies of RL aren't just consequences of the simplistic structural assumptions made

May 25, 2025 at 10:51 PM
This RLiNo? paper (arxiv.org/abs/2505.13697) lead by Soumya Samineni and Durgesh_kalwar dives into the MDP model used in the RL post-training methods inspired by DeepSeek R1, and asks if some of the idiosyncrasies of RL aren't just consequences of the simplistic structural assumptions made
Do Intermediate Tokens Produced by LRMs (need to) have any semantics? Our new study 👇
Thread 👉 x.com/rao2z/status...
Thread 👉 x.com/rao2z/status...

May 21, 2025 at 8:08 PM
Do Intermediate Tokens Produced by LRMs (need to) have any semantics? Our new study 👇
Thread 👉 x.com/rao2z/status...
Thread 👉 x.com/rao2z/status...
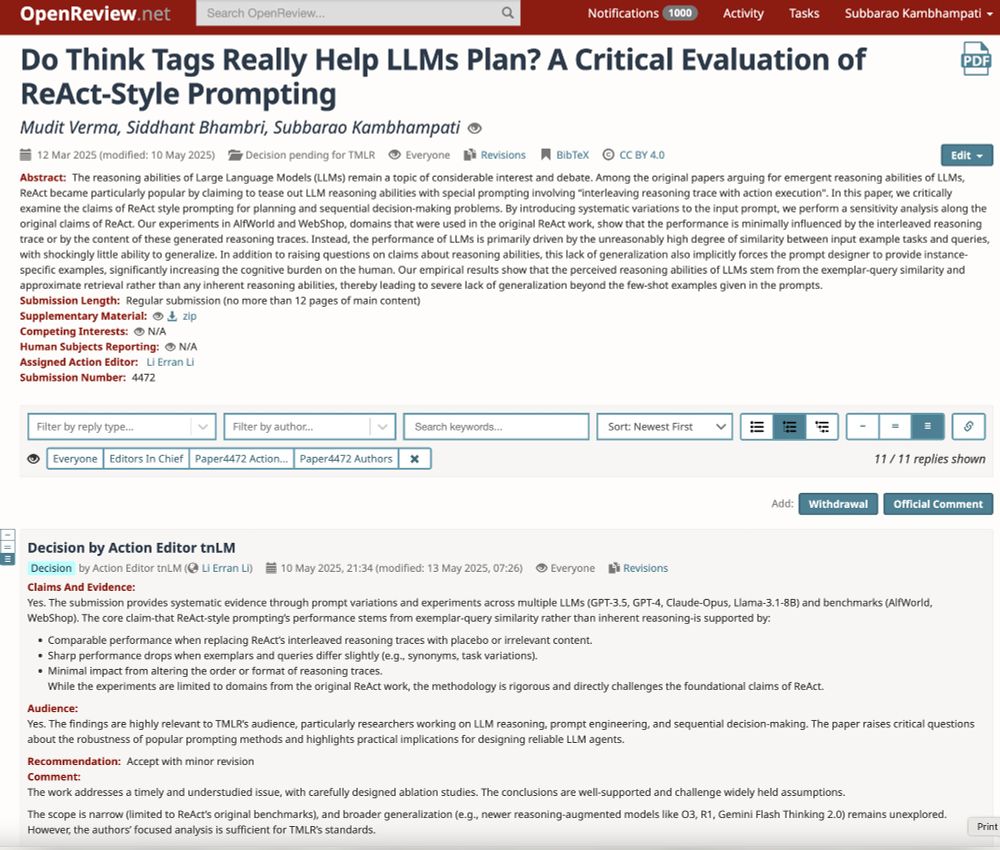
Delighted to share that Siddhant Bhambri & Mudit Verma's
critical evaluation and refutation of the reasoning claims of ReACT has been accepted to #TMLR (Transactions on Machine Learning)
👉https://openreview.net/forum?id=aFAMPSmNHR
critical evaluation and refutation of the reasoning claims of ReACT has been accepted to #TMLR (Transactions on Machine Learning)
👉https://openreview.net/forum?id=aFAMPSmNHR
May 13, 2025 at 5:22 PM
Delighted to share that Siddhant Bhambri & Mudit Verma's
critical evaluation and refutation of the reasoning claims of ReACT has been accepted to #TMLR (Transactions on Machine Learning)
👉https://openreview.net/forum?id=aFAMPSmNHR
critical evaluation and refutation of the reasoning claims of ReACT has been accepted to #TMLR (Transactions on Machine Learning)
👉https://openreview.net/forum?id=aFAMPSmNHR
Solving Single Agent Fully Observable Deterministic (SAFODP) Problems with Dec-POMDP approaches #SundayHarangue #allegory
x.com/rao2z/status...
x.com/rao2z/status...
Subbarao Kambhampati (కంభంపాటి సుబ్బారావు) on X: "Solving Single Agent Fully Observable Deterministic (SAFODP) Problems with Dec-POMDP approaches #SundayHarangue #allegory Imagine you modeled your decision problem into a Dec-POMDP problem ('cuz that's as expressive a decision model as you can get! )--but with some https://t.co/vDWYTHbnQA" / X
Solving Single Agent Fully Observable Deterministic (SAFODP) Problems with Dec-POMDP approaches #SundayHarangue #allegory Imagine you modeled your decision problem into a Dec-POMDP problem ('cuz that's as expressive a decision model as you can get! )--but with some https://t.co/vDWYTHbnQA
x.com
May 12, 2025 at 12:45 AM
Solving Single Agent Fully Observable Deterministic (SAFODP) Problems with Dec-POMDP approaches #SundayHarangue #allegory
x.com/rao2z/status...
x.com/rao2z/status...
IMHO, the whole idea of connecting "length of intermediate tokens" produced by LRMs to inference time compute is a mind-boggling demonstration of circular reasoning--that comes from the assumptions about MDP model and reward model.. 👇
x.com/rao2z/status...
x.com/rao2z/status...
x.com
May 9, 2025 at 2:42 PM
IMHO, the whole idea of connecting "length of intermediate tokens" produced by LRMs to inference time compute is a mind-boggling demonstration of circular reasoning--that comes from the assumptions about MDP model and reward model.. 👇
x.com/rao2z/status...
x.com/rao2z/status...
