



@ningsean.bsky.social
Reposted

Reposted

I have now had a chance to test out the Michelin CrossClimate 2 tires in some heavy snow.
Here's a short thread on my thoughts. Overall extremely pleased with a few minor surprises.
Here's a short thread on my thoughts. Overall extremely pleased with a few minor surprises.

November 29, 2025 at 9:32 PM
I have now had a chance to test out the Michelin CrossClimate 2 tires in some heavy snow.
Here's a short thread on my thoughts. Overall extremely pleased with a few minor surprises.
Here's a short thread on my thoughts. Overall extremely pleased with a few minor surprises.
Reposted

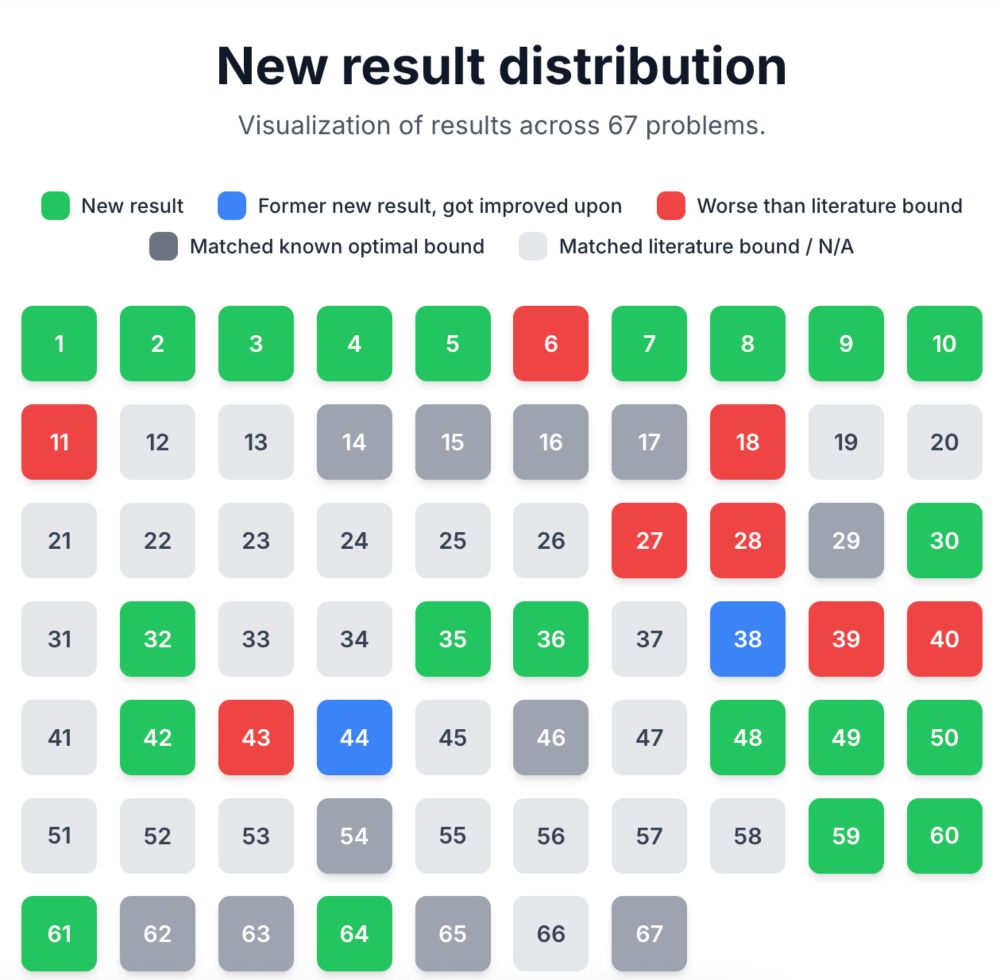
Looks like we got a new DeepSeek model over the holidays (again): github.com/deepseek-ai/...
Basically pushes RLVR & self-refinement to gold-level scores on IMO 2025.
Coincidentally, I am currently working on a chapter on self-refinement, and this comes in handy as a nice, scaled-up case study.
Basically pushes RLVR & self-refinement to gold-level scores on IMO 2025.
Coincidentally, I am currently working on a chapter on self-refinement, and this comes in handy as a nice, scaled-up case study.

November 29, 2025 at 3:11 PM
Looks like we got a new DeepSeek model over the holidays (again): github.com/deepseek-ai/...
Basically pushes RLVR & self-refinement to gold-level scores on IMO 2025.
Coincidentally, I am currently working on a chapter on self-refinement, and this comes in handy as a nice, scaled-up case study.
Basically pushes RLVR & self-refinement to gold-level scores on IMO 2025.
Coincidentally, I am currently working on a chapter on self-refinement, and this comes in handy as a nice, scaled-up case study.
Reposted

And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...

November 27, 2025 at 7:47 AM
And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...
Reposted

Bless her little heart.

November 24, 2025 at 4:32 AM
Bless her little heart.
Reposted

Open sourced Zork today opensource.microsoft.com/blog/2025/11... and ran it on a swarm of containers in the cloud 😂
Preserving code that shaped generations: Zork I, II, and III go Open Source
Microsoft’s Open Source Programs Office (OSPO), Team Xbox, and Activision are making Zork I, Zork II, and Zork III available under the MIT License.
opensource.microsoft.com
November 20, 2025 at 6:42 PM
Open sourced Zork today opensource.microsoft.com/blog/2025/11... and ran it on a swarm of containers in the cloud 😂
Reposted

This is Fendi. He is seen here demonstrating the internationally acknowledged sign language for politely requesting uppies. 13/10 would pick him up immediately (TT: isthat_jojo)
November 17, 2025 at 11:41 PM
This is Fendi. He is seen here demonstrating the internationally acknowledged sign language for politely requesting uppies. 13/10 would pick him up immediately (TT: isthat_jojo)
Reposted

from which the original tokens can be reconstructed with over 99.9\% accuracy.
Project: shaochenze.github.io/blog/2025/CA...
Paper: arxiv.org/abs/2510.27688
Repo: github.com/shaochenze/c...
Project: shaochenze.github.io/blog/2025/CA...
Paper: arxiv.org/abs/2510.27688
Repo: github.com/shaochenze/c...

November 5, 2025 at 12:11 AM
from which the original tokens can be reconstructed with over 99.9\% accuracy.
Project: shaochenze.github.io/blog/2025/CA...
Paper: arxiv.org/abs/2510.27688
Repo: github.com/shaochenze/c...
Project: shaochenze.github.io/blog/2025/CA...
Paper: arxiv.org/abs/2510.27688
Repo: github.com/shaochenze/c...
Reposted

This is dope. In the spirit of the BPP free breakfast program, but fancy.

French bakery in Bed-Stuy offers free breakfast to SNAP card holders
Beginning Nov. 1, when SNAP benefits are expected to be suspended, Je T’aime Patisserie will offer free breakfast to anyone who presents their EBT card from 7:30-10 a.m.
www.nydailynews.com
October 31, 2025 at 3:55 PM
This is dope. In the spirit of the BPP free breakfast program, but fancy.
Reposted

The White House has fired all six members of the U.S. Commission of Fine Arts, the independent federal agency that reviews design plans for monuments, memorials, coins and federal buildings. n.pr/4ntG3PR

White House fires entire commission that reviews designs for federal buildings
The White House has fired all six members of the U.S. Commission of Fine Arts, the independent federal agency that reviews design plans for monuments, memorials, coins and federal buildings.
n.pr
October 29, 2025 at 2:57 PM
The White House has fired all six members of the U.S. Commission of Fine Arts, the independent federal agency that reviews design plans for monuments, memorials, coins and federal buildings. n.pr/4ntG3PR
Reposted

Two U.S. Navy aircraft went down in separate incidents while conducting routine operations from an aircraft carrier in the South China Sea on Sunday. The crew members of both aircraft were in stable condition after being rescued and the causes of both crashes were under investigation.

2 U.S. Navy Aircraft Go Down in South China Sea
A helicopter and a fighter jet went down in separate incidents while operating from a U.S. aircraft carrier on Sunday, the Navy said. The crews were rescued.
nyti.ms
October 27, 2025 at 5:05 AM
Two U.S. Navy aircraft went down in separate incidents while conducting routine operations from an aircraft carrier in the South China Sea on Sunday. The crew members of both aircraft were in stable condition after being rescued and the causes of both crashes were under investigation.
Reposted

Reposted

October 17, 2025 at 4:47 AM
Reposted
- Latent encoder, E: embeds the input data into a latent space.
- Core recurrent “thinking” block, T: generates latent “thoughts”.
- Latent decoder, D: un-embeds from latent space to the output (language) space.
Paper: arxiv.org/abs/2510.07358
- Core recurrent “thinking” block, T: generates latent “thoughts”.
- Latent decoder, D: un-embeds from latent space to the output (language) space.
Paper: arxiv.org/abs/2510.07358

October 17, 2025 at 4:53 AM
- Latent encoder, E: embeds the input data into a latent space.
- Core recurrent “thinking” block, T: generates latent “thoughts”.
- Latent decoder, D: un-embeds from latent space to the output (language) space.
Paper: arxiv.org/abs/2510.07358
- Core recurrent “thinking” block, T: generates latent “thoughts”.
- Latent decoder, D: un-embeds from latent space to the output (language) space.
Paper: arxiv.org/abs/2510.07358
Reposted
GitHub 👉 github.com/PaddlePaddle...
HuggingFace 👉 huggingface.co/PaddlePaddle...
AI Studio 👉 paddleocr.ai/latest/en/in...
HuggingFace 👉 huggingface.co/PaddlePaddle...
AI Studio 👉 paddleocr.ai/latest/en/in...

GitHub - PaddlePaddle/PaddleOCR: Turn any PDF or image document into structured data for your AI. A powerful, lightweight OCR toolkit that bridges the gap between images/PDFs and LLMs. Supports 80+ la...
Turn any PDF or image document into structured data for your AI. A powerful, lightweight OCR toolkit that bridges the gap between images/PDFs and LLMs. Supports 80+ languages. - PaddlePaddle/PaddleOCR
github.com
October 16, 2025 at 3:59 PM
GitHub 👉 github.com/PaddlePaddle...
HuggingFace 👉 huggingface.co/PaddlePaddle...
AI Studio 👉 paddleocr.ai/latest/en/in...
HuggingFace 👉 huggingface.co/PaddlePaddle...
AI Studio 👉 paddleocr.ai/latest/en/in...
Reposted
Pretraining with Hierarchical Memories
They propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge).
Paper: arxiv.org/abs/2510.02375
They propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge).
Paper: arxiv.org/abs/2510.02375
October 14, 2025 at 5:18 AM
Pretraining with Hierarchical Memories
They propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge).
Paper: arxiv.org/abs/2510.02375
They propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge).
Paper: arxiv.org/abs/2510.02375
Reposted
"Install the Beads binary, tell your agent in AGENTS.md to stop using Markdown and run `bd quickstart`, and your agents will spontaneously get better at everything, particularly long-horizon planning and keeping track of newly discovered work."
github.com/steveyegge/b...
github.com/steveyegge/b...
October 14, 2025 at 4:27 AM
"Install the Beads binary, tell your agent in AGENTS.md to stop using Markdown and run `bd quickstart`, and your agents will spontaneously get better at everything, particularly long-horizon planning and keeping track of newly discovered work."
github.com/steveyegge/b...
github.com/steveyegge/b...
Reposted

During a “routine annual checkup” at Walter Reed Medical Center—Trump’s second of 2025—Trump received a report of gushing awe from White House physician Dr. Sean Barbarella.

Trump Humiliates RFK Jr. With Surprise COVID Booster Move
The president got all of his shots while his administration restricts the availability of vaccines.
trib.al
October 11, 2025 at 2:25 PM
During a “routine annual checkup” at Walter Reed Medical Center—Trump’s second of 2025—Trump received a report of gushing awe from White House physician Dr. Sean Barbarella.
Reposted
Updated & turned my Big LLM Architecture Comparison article into a video lecture.
The 11 LLM archs covered in this video:
1. DeepSeek V3/R1
2. OLMo 2
3. Gemma 3
4. Mistral Small 3.1
5. Llama 4
6. Qwen3
7. SmolLM3
8. Kimi 2
9. GPT-OSS
10. Grok 2.5
11. GLM-4.5/4.6
www.youtube.com/watch?v=rNlU...
The 11 LLM archs covered in this video:
1. DeepSeek V3/R1
2. OLMo 2
3. Gemma 3
4. Mistral Small 3.1
5. Llama 4
6. Qwen3
7. SmolLM3
8. Kimi 2
9. GPT-OSS
10. Grok 2.5
11. GLM-4.5/4.6
www.youtube.com/watch?v=rNlU...

The Big LLM Architecture Comparison
YouTube video by Sebastian Raschka
www.youtube.com
October 10, 2025 at 5:05 PM
Updated & turned my Big LLM Architecture Comparison article into a video lecture.
The 11 LLM archs covered in this video:
1. DeepSeek V3/R1
2. OLMo 2
3. Gemma 3
4. Mistral Small 3.1
5. Llama 4
6. Qwen3
7. SmolLM3
8. Kimi 2
9. GPT-OSS
10. Grok 2.5
11. GLM-4.5/4.6
www.youtube.com/watch?v=rNlU...
The 11 LLM archs covered in this video:
1. DeepSeek V3/R1
2. OLMo 2
3. Gemma 3
4. Mistral Small 3.1
5. Llama 4
6. Qwen3
7. SmolLM3
8. Kimi 2
9. GPT-OSS
10. Grok 2.5
11. GLM-4.5/4.6
www.youtube.com/watch?v=rNlU...
Reposted
The result is:
- +20–40% more non-zero gradients
- Up to 93 rollouts for hard tasks (w/o extra compute)
- +2–4 avg points, +9 peak gains on math benchmarks
- ~2× cheaper than uniform allocation
Paper: arxiv.org/abs/2509.25849
- +20–40% more non-zero gradients
- Up to 93 rollouts for hard tasks (w/o extra compute)
- +2–4 avg points, +9 peak gains on math benchmarks
- ~2× cheaper than uniform allocation
Paper: arxiv.org/abs/2509.25849

October 2, 2025 at 8:41 PM
The result is:
- +20–40% more non-zero gradients
- Up to 93 rollouts for hard tasks (w/o extra compute)
- +2–4 avg points, +9 peak gains on math benchmarks
- ~2× cheaper than uniform allocation
Paper: arxiv.org/abs/2509.25849
- +20–40% more non-zero gradients
- Up to 93 rollouts for hard tasks (w/o extra compute)
- +2–4 avg points, +9 peak gains on math benchmarks
- ~2× cheaper than uniform allocation
Paper: arxiv.org/abs/2509.25849
Reposted
Paper: DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search ( arxiv.org/abs/2509.25454 )
Model: huggingface.co/fangwu97/Dee...
Model: huggingface.co/fangwu97/Dee...

October 2, 2025 at 8:46 PM
Paper: DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search ( arxiv.org/abs/2509.25454 )
Model: huggingface.co/fangwu97/Dee...
Model: huggingface.co/fangwu97/Dee...
Reposted

This long-lasting meteor shower peaks in late October and is known for producing bright “fireball” shooting stars. Here’s what to know about Orionids and other major showers that will appear in 2025. www.wired.com/story/watch-...

How to Watch the Orionids Meteor Shower
This long-lasting meteor shower peaks in late October and is known for producing bright “fireball” shooting stars. Here’s what to know about Orionids and other major showers that will appear in...
www.wired.com
October 1, 2025 at 6:03 AM
This long-lasting meteor shower peaks in late October and is known for producing bright “fireball” shooting stars. Here’s what to know about Orionids and other major showers that will appear in 2025. www.wired.com/story/watch-...
Reposted

September 23, 2025 at 12:51 PM
Reposted
Paper: LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures ( arxiv.org/abs/2509.142... )
Repo: github.com/rbalestr-lab...
Repo: github.com/rbalestr-lab...

GitHub - rbalestr-lab/llm-jepa
Contribute to rbalestr-lab/llm-jepa development by creating an account on GitHub.
github.com
September 21, 2025 at 10:26 PM
Paper: LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures ( arxiv.org/abs/2509.142... )
Repo: github.com/rbalestr-lab...
Repo: github.com/rbalestr-lab...