




Nishant Balepur
@nbalepur.bsky.social
CS PhD Student. Trying to find that dog in me at UMD. Babysitting (aligning) + Bullying (evaluating) LLMs
nbalepur.github.io
nbalepur.github.io
🎉🎉 Excited to have two papers accepted to #ACL2025!
Our first paper designs a preference training method to boost LLM personalization 🎨
While the second outlines our position on why MCQA evals are terrible and how to make them better 🙏
Grateful for amazing collaborators!
Our first paper designs a preference training method to boost LLM personalization 🎨
While the second outlines our position on why MCQA evals are terrible and how to make them better 🙏
Grateful for amazing collaborators!

May 21, 2025 at 6:34 PM
🎉🎉 Excited to have two papers accepted to #ACL2025!
Our first paper designs a preference training method to boost LLM personalization 🎨
While the second outlines our position on why MCQA evals are terrible and how to make them better 🙏
Grateful for amazing collaborators!
Our first paper designs a preference training method to boost LLM personalization 🎨
While the second outlines our position on why MCQA evals are terrible and how to make them better 🙏
Grateful for amazing collaborators!
Reposted by Nishant Balepur

Want to know what training data has been memorized by models like GPT-4?
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)

Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. ...
arxiv.org
March 21, 2025 at 7:08 PM
Want to know what training data has been memorized by models like GPT-4?
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)
We propose information-guided probes, a method to uncover memorization evidence in *completely black-box* models,
without requiring access to
🙅♀️ Model weights
🙅♀️ Training data
🙅♀️ Token probabilities 🧵 (1/5)
Reposted by Nishant Balepur

Finally may have figured out why LLMs rhyme so compulsively: instruction-tuning. Training an LLM to respond "helpfully" to user queries may push models into more "pleasing" aesthetic forms.

March 21, 2025 at 9:57 AM
Finally may have figured out why LLMs rhyme so compulsively: instruction-tuning. Training an LLM to respond "helpfully" to user queries may push models into more "pleasing" aesthetic forms.
Had a great time presenting my research on building more helpful QA systems @imperialcollegeldn.bsky.social! Thank you @joestacey.bsky.social for letting me invite myself 🫶
And loved visiting London+Edinburgh this week, hope to be back soon! 🙏
And loved visiting London+Edinburgh this week, hope to be back soon! 🙏



March 21, 2025 at 12:07 PM
Had a great time presenting my research on building more helpful QA systems @imperialcollegeldn.bsky.social! Thank you @joestacey.bsky.social for letting me invite myself 🫶
And loved visiting London+Edinburgh this week, hope to be back soon! 🙏
And loved visiting London+Edinburgh this week, hope to be back soon! 🙏
🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
March 11, 2025 at 2:30 PM
🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
Reposted by Nishant Balepur
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵

February 24, 2025 at 9:04 PM
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Reposted by Nishant Balepur

⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
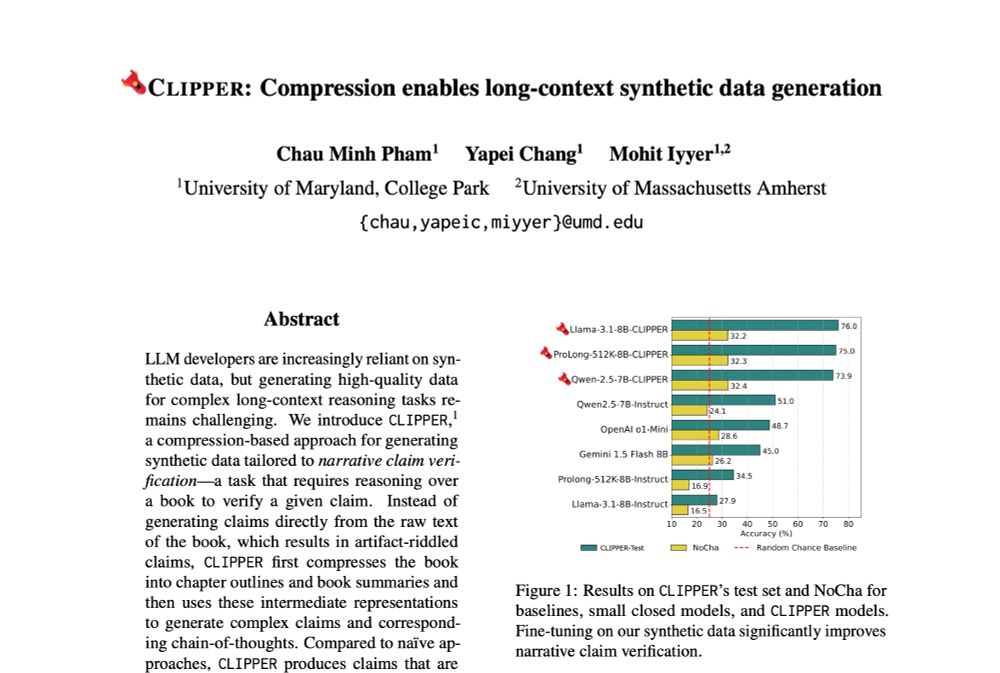
February 21, 2025 at 4:25 PM
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
February 24, 2025 at 9:04 PM
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Excited to share 2 papers at #NAACL2025 main!
📄✍️ MoDS: Multi-Doc Summarization for Debatable Queries (Adobe intern work, coming soon!)
🤔❓Reverse QA: LLMs struggle with the simple task of giving questions for answers
Grateful for all my collaborators 😁
📄✍️ MoDS: Multi-Doc Summarization for Debatable Queries (Adobe intern work, coming soon!)
🤔❓Reverse QA: LLMs struggle with the simple task of giving questions for answers
Grateful for all my collaborators 😁

January 31, 2025 at 2:32 PM
Excited to share 2 papers at #NAACL2025 main!
📄✍️ MoDS: Multi-Doc Summarization for Debatable Queries (Adobe intern work, coming soon!)
🤔❓Reverse QA: LLMs struggle with the simple task of giving questions for answers
Grateful for all my collaborators 😁
📄✍️ MoDS: Multi-Doc Summarization for Debatable Queries (Adobe intern work, coming soon!)
🤔❓Reverse QA: LLMs struggle with the simple task of giving questions for answers
Grateful for all my collaborators 😁
Reposted by Nishant Balepur

People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯

January 28, 2025 at 2:55 PM
People often claim they know when ChatGPT wrote something, but are they as accurate as they think?
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Turns out that while general population is unreliable, those who frequently use ChatGPT for writing tasks can spot even "humanized" AI-generated text with near-perfect accuracy 🎯
Manifesting some good luck for my experiment running tonight 🤞
Best of luck to anyone submitting tmrw :)
Best of luck to anyone submitting tmrw :)

December 15, 2024 at 5:03 AM
Manifesting some good luck for my experiment running tonight 🤞
Best of luck to anyone submitting tmrw :)
Best of luck to anyone submitting tmrw :)
Reposted by Nishant Balepur

Exciting research on an AI-driven mnemonic generator for easier vocabulary memorization by @nbalepur.bsky.social, Jordan Boyd-Graber, Rachel Rudinger, & @alexanderhoyle.bsky.social. Part of 21 CLIP projects at #EMNLP2024. 👉 Read more: go.umd.edu/1u48 #AI

December 3, 2024 at 3:46 PM
Exciting research on an AI-driven mnemonic generator for easier vocabulary memorization by @nbalepur.bsky.social, Jordan Boyd-Graber, Rachel Rudinger, & @alexanderhoyle.bsky.social. Part of 21 CLIP projects at #EMNLP2024. 👉 Read more: go.umd.edu/1u48 #AI
Reposted by Nishant Balepur

OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
November 26, 2024 at 9:12 PM
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social