



Mihail Stoian
@mihailstoian.bsky.social
Second-year database PhD student @UTN. Interned @Oracle, @AWS
Pinned
Mihail Stoian
@mihailstoian.bsky.social
· Apr 10
DPconv just won a SIGMOD'25 Honorable Mention! 🥁
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
Reposted by Mihail Stoian

🦆 Episode 3 in Season 2 of the DuckDB in Research series is out now!
🎙️ Parachute: Rethinking Query Execution and Bidirectional Information Flow in DuckDB (@duckdb.org) with Mihail Stoian (@mihailstoian.bsky.social)
🔗 Listen now on Spotify: open.spotify.com/episode/21HQ...
🎙️ Parachute: Rethinking Query Execution and Bidirectional Information Flow in DuckDB (@duckdb.org) with Mihail Stoian (@mihailstoian.bsky.social)
🔗 Listen now on Spotify: open.spotify.com/episode/21HQ...

Parachute: Rethinking Query Execution and Bidirectional Information Flow in DuckDB - with Mihail Stoian
open.spotify.com
October 30, 2025 at 8:42 AM
🦆 Episode 3 in Season 2 of the DuckDB in Research series is out now!
🎙️ Parachute: Rethinking Query Execution and Bidirectional Information Flow in DuckDB (@duckdb.org) with Mihail Stoian (@mihailstoian.bsky.social)
🔗 Listen now on Spotify: open.spotify.com/episode/21HQ...
🎙️ Parachute: Rethinking Query Execution and Bidirectional Information Flow in DuckDB (@duckdb.org) with Mihail Stoian (@mihailstoian.bsky.social)
🔗 Listen now on Spotify: open.spotify.com/episode/21HQ...
Big thanks to Jack Waudby for having me on his @disseminatepodcast.bsky.social! Enjoyed our chat about 🪂 Parachute and how @duckdb.org's ecosystem makes testing database research prototypes smoother than ever.
Highly recommend the podcast for anyone into cutting-edge CS research.
Highly recommend the podcast for anyone into cutting-edge CS research.

📢 A new DuckDB in Research podcast episode is out.
📈 In this week's episode, Jack Waudby interviews Mihail Stoian (@mihailstoian.bsky.social), PhD student at the Data Systems Lab, UT Nuremberg about the Parachute approach for robust query processing.
🎧 Listen at duckdb.org/science/miha...
📈 In this week's episode, Jack Waudby interviews Mihail Stoian (@mihailstoian.bsky.social), PhD student at the Data Systems Lab, UT Nuremberg about the Parachute approach for robust query processing.
🎧 Listen at duckdb.org/science/miha...

October 30, 2025 at 9:32 PM
Big thanks to Jack Waudby for having me on his @disseminatepodcast.bsky.social! Enjoyed our chat about 🪂 Parachute and how @duckdb.org's ecosystem makes testing database research prototypes smoother than ever.
Highly recommend the podcast for anyone into cutting-edge CS research.
Highly recommend the podcast for anyone into cutting-edge CS research.
Reposted by Mihail Stoian

"The fastest way of processing data is to not process it."
Our SIGMOD 2025 paper shows how Snowflake skips 99.4% of data with new pruning techniques for LIMIT, top-k, and JOIN queries.
Blog: snowflakepruning.github.io
Paper: arxiv.org/abs/2504.11540
@sigmod2025.bsky.social
Our SIGMOD 2025 paper shows how Snowflake skips 99.4% of data with new pruning techniques for LIMIT, top-k, and JOIN queries.
Blog: snowflakepruning.github.io
Paper: arxiv.org/abs/2504.11540
@sigmod2025.bsky.social
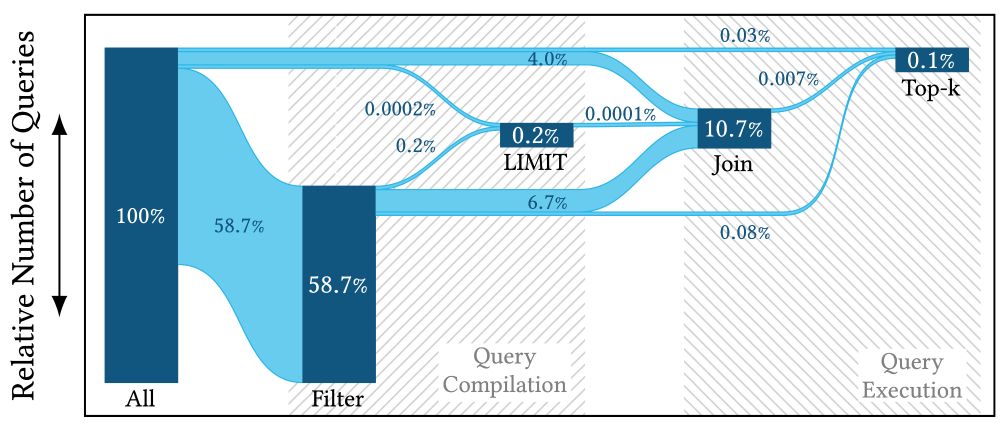
Andi Zimmerer | Pruning in Snowflake: Working Smarter, Not Harder
Modern cloud-based data analytics systems must efficiently process petabytes of data residing on cloud storage. A key optimization technique in state-of-the-art systems like Snowflake is partition pru...
snowflakepruning.github.io
May 5, 2025 at 5:09 AM
"The fastest way of processing data is to not process it."
Our SIGMOD 2025 paper shows how Snowflake skips 99.4% of data with new pruning techniques for LIMIT, top-k, and JOIN queries.
Blog: snowflakepruning.github.io
Paper: arxiv.org/abs/2504.11540
@sigmod2025.bsky.social
Our SIGMOD 2025 paper shows how Snowflake skips 99.4% of data with new pruning techniques for LIMIT, top-k, and JOIN queries.
Blog: snowflakepruning.github.io
Paper: arxiv.org/abs/2504.11540
@sigmod2025.bsky.social
Reposted by Mihail Stoian
SIGMOD BEST PAPER Honorable Mentions
🥇 CRDV: Conflict-free Replicated Data Views
Nuno Faria (INESCTEC & U. Minho)*; José Pereira (U. Minho & INESCTEC)
🥇 DPconv: Super-Polynomially Faster Join Ordering
Mihail Stoian (UTN)*; Andreas Kipf (UTN)
🥇 CRDV: Conflict-free Replicated Data Views
Nuno Faria (INESCTEC & U. Minho)*; José Pereira (U. Minho & INESCTEC)
🥇 DPconv: Super-Polynomially Faster Join Ordering
Mihail Stoian (UTN)*; Andreas Kipf (UTN)
April 22, 2025 at 7:29 PM
SIGMOD BEST PAPER Honorable Mentions
🥇 CRDV: Conflict-free Replicated Data Views
Nuno Faria (INESCTEC & U. Minho)*; José Pereira (U. Minho & INESCTEC)
🥇 DPconv: Super-Polynomially Faster Join Ordering
Mihail Stoian (UTN)*; Andreas Kipf (UTN)
🥇 CRDV: Conflict-free Replicated Data Views
Nuno Faria (INESCTEC & U. Minho)*; José Pereira (U. Minho & INESCTEC)
🥇 DPconv: Super-Polynomially Faster Join Ordering
Mihail Stoian (UTN)*; Andreas Kipf (UTN)
DPconv just won a SIGMOD'25 Honorable Mention! 🥁
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
April 10, 2025 at 5:57 PM
DPconv just won a SIGMOD'25 Honorable Mention! 🥁
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
I was quite impressed, given this year's high-quality papers. Let's see who won the big prize.
My list of candidates in the thread below 🧵.
Paper: dl.acm.org/doi/10.1145/...
Slides: stoianmihail.github.io/assets/dpcon...
🔺Redbench is now live: github.com/utndatasyste....
Let's see how workload-aware your system really is.
Let's see how workload-aware your system really is.
We just released Redbench, a new benchmark that contains 30 analytical SQL workloads that can be used to benchmark workload-driven optimizations. Go check it out!
GitHub: github.com/utndatasyste...
GitHub: github.com/utndatasyste...

GitHub - utndatasystems/redbench: Redbench is a set of 30 analytical SQL workloads that can be used to benchmark workload-driven optimizations.
Redbench is a set of 30 analytical SQL workloads that can be used to benchmark workload-driven optimizations. - utndatasystems/redbench
github.com
April 9, 2025 at 10:11 PM
🔺Redbench is now live: github.com/utndatasyste....
Let's see how workload-aware your system really is.
Let's see how workload-aware your system really is.
Reposted by Mihail Stoian

Thrilled to share that we've received the Best Demonstration Award 🏆 at EDBT 2025!
Congratulations to my students @mihailstoian.bsky.social and Ping-Lin Kuo for their excellent work and dedication over the past few weeks—well deserved!
Paper: openproceedings.org/2025/conf/ed...
Congratulations to my students @mihailstoian.bsky.social and Ping-Lin Kuo for their excellent work and dedication over the past few weeks—well deserved!
Paper: openproceedings.org/2025/conf/ed...




March 28, 2025 at 1:39 PM
Thrilled to share that we've received the Best Demonstration Award 🏆 at EDBT 2025!
Congratulations to my students @mihailstoian.bsky.social and Ping-Lin Kuo for their excellent work and dedication over the past few weeks—well deserved!
Paper: openproceedings.org/2025/conf/ed...
Congratulations to my students @mihailstoian.bsky.social and Ping-Lin Kuo for their excellent work and dedication over the past few weeks—well deserved!
Paper: openproceedings.org/2025/conf/ed...
Umbra's DP optimizer for queries of ~100 relations ran in cubic time.
AWS Redshift's Redset captures a 2,296-relation query.
Our revamped DP enumeration optimizes tree queries like snowflakes of *millions* of relations within 1 sec. 🛸
Joint work w/ Altan Birler & Thomas Neumann.
AWS Redshift's Redset captures a 2,296-relation query.
Our revamped DP enumeration optimizes tree queries like snowflakes of *millions* of relations within 1 sec. 🛸
Joint work w/ Altan Birler & Thomas Neumann.

January 13, 2025 at 7:20 AM
Umbra's DP optimizer for queries of ~100 relations ran in cubic time.
AWS Redshift's Redset captures a 2,296-relation query.
Our revamped DP enumeration optimizes tree queries like snowflakes of *millions* of relations within 1 sec. 🛸
Joint work w/ Altan Birler & Thomas Neumann.
AWS Redshift's Redset captures a 2,296-relation query.
Our revamped DP enumeration optimizes tree queries like snowflakes of *millions* of relations within 1 sec. 🛸
Joint work w/ Altan Birler & Thomas Neumann.
Are you a fan of Parquet and at #NeurIPS2024 tomorrow? Let's meet at our poster at @trl-research.bsky.social to see how you can reduce your Parquet file sizes by up to 40%.
Virtual compresses tables via functions while ensuring fast column scans.
⏰ 2.30pm
📍East Meeting Room 11 & 12
Virtual compresses tables via functions while ensuring fast column scans.
⏰ 2.30pm
📍East Meeting Room 11 & 12

December 14, 2024 at 1:06 AM
Are you a fan of Parquet and at #NeurIPS2024 tomorrow? Let's meet at our poster at @trl-research.bsky.social to see how you can reduce your Parquet file sizes by up to 40%.
Virtual compresses tables via functions while ensuring fast column scans.
⏰ 2.30pm
📍East Meeting Room 11 & 12
Virtual compresses tables via functions while ensuring fast column scans.
⏰ 2.30pm
📍East Meeting Room 11 & 12
Reposted by Mihail Stoian

Vol:17 No:12 → DataLoom: Simplifying Data Loading with LLMs
👥 Authors: Alexander Van Renen, Mihail Stoian, Andreas Kipf
📄 PDF: https://www.vldb.org/pvldb/vol17/p4449-renen.pdf
👥 Authors: Alexander Van Renen, Mihail Stoian, Andreas Kipf
📄 PDF: https://www.vldb.org/pvldb/vol17/p4449-renen.pdf

December 2, 2024 at 5:00 AM
Vol:17 No:12 → DataLoom: Simplifying Data Loading with LLMs
👥 Authors: Alexander Van Renen, Mihail Stoian, Andreas Kipf
📄 PDF: https://www.vldb.org/pvldb/vol17/p4449-renen.pdf
👥 Authors: Alexander Van Renen, Mihail Stoian, Andreas Kipf
📄 PDF: https://www.vldb.org/pvldb/vol17/p4449-renen.pdf