



Micah Carroll
@micahcarroll.bsky.social
PhD student @ berkeley. https://micahcarroll.github.io/
LLMs' sycophancy issues are a predictable result of optimizing for user feedback. Even if clear sycophantic behaviors get fixed, AIs' exploits of our cognitive biases may only become more subtle.
Grateful our research on this was featured in @washingtonpost.com by @nitasha.bsky.social!
Grateful our research on this was featured in @washingtonpost.com by @nitasha.bsky.social!

AI is speedrunning the social media era by optimizing chatbots for engagement, user feedback, time spent.
Evidence is mounting that this poses unintended risks, includ. chats from peer-reviewed research, OpenAI's "sycophancy" debacle, & Character ai lawsuits www.washingtonpost.com/technology/2...
Evidence is mounting that this poses unintended risks, includ. chats from peer-reviewed research, OpenAI's "sycophancy" debacle, & Character ai lawsuits www.washingtonpost.com/technology/2...

Your chatbot friend might be messing with your mind
OpenAI, Meta and others want people to spend more time with AI chatbots, but there is growing evidence that they can hook users or reinforce harmful ideas.
www.washingtonpost.com
June 1, 2025 at 6:25 PM
LLMs' sycophancy issues are a predictable result of optimizing for user feedback. Even if clear sycophantic behaviors get fixed, AIs' exploits of our cognitive biases may only become more subtle.
Grateful our research on this was featured in @washingtonpost.com by @nitasha.bsky.social!
Grateful our research on this was featured in @washingtonpost.com by @nitasha.bsky.social!
Reposted by Micah Carroll

How effective are LLMs are persuading and deceiving people? In a new preprint we review different theoretical risks of LLM persuasion; empirical work measuring how persuasive LLMs currently are; and proposals to mitigate these risks. 🧵
arxiv.org/abs/2412.17128
arxiv.org/abs/2412.17128

Lies, Damned Lies, and Distributional Language Statistics: Persuasion and Deception with Large Language Models
Large Language Models (LLMs) can generate content that is as persuasive as human-written text and appear capable of selectively producing deceptive outputs. These capabilities raise concerns about pot...
arxiv.org
January 10, 2025 at 1:59 PM
How effective are LLMs are persuading and deceiving people? In a new preprint we review different theoretical risks of LLM persuasion; empirical work measuring how persuasive LLMs currently are; and proposals to mitigate these risks. 🧵
arxiv.org/abs/2412.17128
arxiv.org/abs/2412.17128
Reposted by Micah Carroll

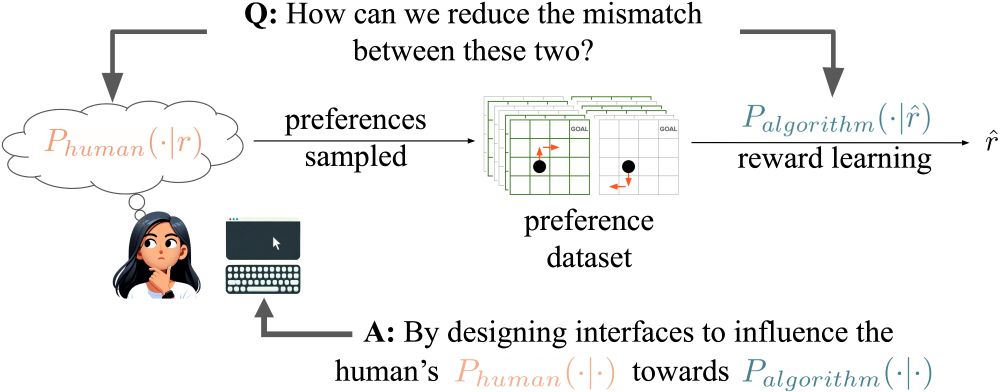
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)

January 14, 2025 at 11:51 PM
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
#AI #MachineLearning #RLHF #Alignment (1/n)